MySql笔记
文章目录
01 基础
学习的是YouTube上面的一个up主,B站也有同步课程,有兴趣可以关注一下,视频讲的更加详细。
YouTube链接:https://www.youtube.com/channel/UCRCqgMdsAHK3yfvW4en6JpA
基础知识:
- Database中包含多个相关的table,每个Table中有行和列。
- Table中包含Primary Key(主键)和Foreign Key(外键)。主键是独一无二的,并且是有唯一存在的,不可以重复或空。给一个主键,可以找出一条独一无二的记录。 主键可以不止有一个信息。
- 主键是唯一的,用于标识一张表。外键可以有多个,用于建立表和表的关系。

之后会用到的示例数据库:

SELECT&FROM
语法:
SELECT * FROM table_name; --选择所有列(*为通配符)
SELECT column_name1,column_name2 FROM table_name; --选择两列
SELECT DISTINCT column_name FROM table_name; --提取出该列独一无二的数值,去除重复
SELECT column_name FROM table_name LIMIT 5 OFFSET 4 --检索五行,从第四行开始(不包含第4行)
语句结束之后要加分号:
WHERE&AND
-
数据库中很少需要检索所有行,通常只会根据指定操作或报告的需要提取表数据的子集。只检索所需要的条件需要指定搜索条件(过滤条件)。
-
可以使用的操作符有:“=”、“<>” “ !=” “ <” “>” “BETWEEN” “Like” “IN” “IS NULL”等
例:
SELECT * FROM Employee WHERE Salay>70000 AND Salary<85000;--检索工资大于70000且小于85000的行
SELECT * FROM Employee WHERE Salarry IN (70000,85000);-- 检索工资为70000或者85000的行
SELECT * FROM Employee WHERE Name LIKE ‘%an%’; --检索名字中包含an的行
LIKE后面需要写单引号
GROUP BY
SELECT DepartmentID,COUNT(Name) FROM Employee GROUP BY DepartmentId;
--COUNT是按照GROUP BY计数的,并不是按照COUNT内的计数,但是输出的列名会是COUNT(Name),也可以对这列重新命名,语句如下:
SELECT DepartmentID,COUNT(Name) AS Number_Empolyee FROM Employee GROUP BY DepartmentId;
--AS 后面跟的是重命名之后的名字,也可以跟其他函数,比如
SELECT DepartmentID,COUNT(Salary) AS Total,MIN(Salary) AS MinSalary,Max(Salary) AS MaxSalary FROM Employee GROUP BY DepartmentId;
HAVING &ORDER BY
- HAVING 一定要和GROUP BY一起用,一定要在分好组的基础上用。
SELECT DepartmentID FROM Employee GROUP BY DepartmentId HAVING COUNT(*) >3;
-- 按照DepartmentID,并且选择数量大于3个的。
SELECT Name,Salary,DepartmentId FROM Employee ORDER BY Salary,DepartmentId;
--从小到大排序,根据Salary排序,如果Salary重复或相等,则按照DepartmentId排序。
SELECT Name,Salary,DepartmentId FROM Employee ORDER BY Salary DESC;
--降序排(默认是升序)
02 提高篇
表之间的连接方式:

所有内容都是基于以下表:

INNER JOIN
- 返回两个table同时存在的内容。可以理解为求一下并集(满足条件的)
- FROM Left_table_Name INNER JOIN Right_Table_Name
示例语句:
SELECT Employee.Id AS Id,Employee.Name AS Name,Employee.Salary AS Salary,Employee.DepartmentId AS DepartmentId,Department.Name AS DepartmentName FROM Employee INNER JOIN Department ON Employee.DepartmentId = Department.Id;
--ON后面跟的是条件,选取符合条件的,然后内连接。
执行之后的结果为:

LEFT JOIN
- LEFT JOIN 关键字会从左表 (table_name1) 那里返回所有的行,即使在右表 (table_name2) 中没有匹配的行,没有输出为空(<N/A>)。
- 用法:SELECT column_name(s) FROM table_name1
LEFT JOIN table_name2 ON table_name1.column_name=table_name2.column_name
示例:
SELECT Employee.Id AS Id,Employee.Name AS Name,Employee.Salary AS Salary,Employee.DepartmentId AS DepartmentId,Department.Name AS DepartmentName FROM Employee LEFT JOIN Department ON Employee.DepartmentId = Department.Id;
返回结果:

需要注意的点:在写SELECT时,后面要写成table.column,而不是直接写列的名字。比较好的习惯是利用AS重命名一下列名。
RIGHT JOIN & OUTER JOIN
RIGHT JOIN
- RIGHT JOIN 关键字会右表 (table_name2) 那里返回所有的行,即使在左表 (table_name1) 中没有匹配的行。
- 关键字用法:
SELECT column_name(s) FROM table_name1 RIGHT JOIN table_name2 ON table_name1.column_name=table_name2.column_name
示例:
SELECT Employee.Id AS Id,Employee.Name AS Name,Employee.Salary AS Salary,Employee.DepartmentId AS DepartmentId,Department.Name AS DepartmentName FROM Employee RIGHT JOIN Department ON Employee.DepartmentId = Department.Id;
输出结果:

OUTER JOIN
- 把所有的内容都保留,与INNER JOIN相反
UNION
- UNION 操作符用于合并两个或多个 SELECT 语句的结果集。UNION 内部的 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每条 SELECT 语句中的列的顺序必须相同。
- UNION 命令只会选取不同的值,如果有重复值只会选出来一个。
- UNION ALL 命令和 UNION 命令几乎是等效的,不过 UNION ALL 命令会列出所有的值。
示例:

SELECT title as Position,Name,Salary FROM professor UNION SELECT title as Position,Name,Salary FROM RTA;
结果:

注意:
注意UNION 和 UNION的区别;
列的顺序和数量要一样;
补充
UPDATE 函数
Update 语句用于修改表中的数据。
语法:
UPDATE 表名称 SET 列名称 = 新值 WHERE 列名称 = 某值
LIMIT
LIMIT是指从某条数据之后,取出n条数据,一般有两种用法:
LIMIT a,b # 从a+1开始取b条数据
LIMIT a # 直接取a条数据(相当于省略了0)
开窗函数
开窗的定义:
窗口就是一个字段的数据范围。有了窗口,实际上我们可以在一个细粒度上的结果集上,进行分组。让后再对分组中的值进行 sum 、avg、count、first_value、last_value、lag、lead、row_number、dense_rank、rank 等操作。所以分组不仅仅是 group by 的专属,开窗函数也可以的。

开窗函数在聚合函数后增加了一个OVER 关键字。开窗函数的调用格式为:
函数名(列) OVER(选项)
# 举例
sum(amt) over(partition by year_mon)
#窗口的定义就是 over 里面的内容了,partition 从单词语义上解释是分区的意思,其实就是分组。
#partition by 就是根据哪个字段作为分组。
#根据 year_mon 分组,并且把每个窗口里面的字段 amt 进行求和操作。
OVER关键字表示把函数当成开窗函数而不是聚合函数。SQL标准允许将所有聚合函数用做开窗函数,使用OVER 关键字来区分这两种用法。
开窗函数中可以在OVER关键字后的选项中使用ORDER BY子句来指定排序规则,而且有的开窗函数还要求必须指定排序规则。使用ORDER BY子句可以对结果集按照指定的排序规则进行排序,并且在一个指定的范围内进行聚合运算。
ORDER BY 字段名 RANGE|ROWS BETWEEN 边界规则1 AND 边界规则2
# RANGE表示按照值的范围进行范围的定义,而ROWS表示按照行的范围进行范围的定义;
可取:
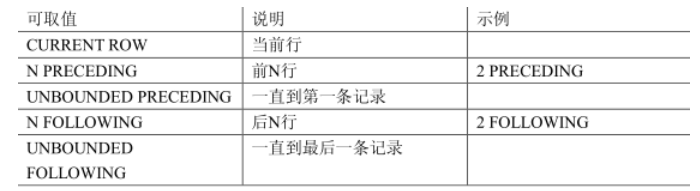
例如:
select fname,
fcity,
fage,
fsalary,
sum(fsalary) over(order by fsalary rows between unbounded preceding and current row) 到当前行工资求和
from t_person
# range
select fname,
fcity,
fage,
fsalary,
sum(fsalary) over(order by fsalary range between unbounded preceding and current row) 到当前行工资求和
from t_person


-
这里的开窗函数“SUM(FSalary) OVER(ORDER BY FSalary ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)”表示按照FSalary进行排序,然后计算从第一行(UNBOUNDED PRECEDING)到当前行(CURRENT ROW)的和,这样的计算结果就是按照工资进行排序的工资值的累积和。
-
RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW”是开窗函数中最常使用的定位框架,为了简化使用,如果使用的是这种定位框架,则可以省略定位框架声明部分
-
这个SQL语句与例1中的SQL语句唯一不同的就是“ROWS”被替换成了“RANGE”。“ROWS”
是按照行数进行范围定位的,而“RANGE”则是按照值范围进行定位的,这两个不同的定位方式
主要用来处理并列排序的情况。比如 Lily、Swing、Bill这三个人的工资都是2000元,如果按照
“ROWS”进行范围定位,则计算从第一条到当前行的累积和,而如果 如果按照 “RANGE”进行
范围定位,则仍然计算从第一条到当前行的累积和,不过由于等于2000元的工资有三个人,所
以计算的累积和为从第一条到2000元工资的人员结,所以对 Lily、Swing、Bill这三个人进行开
窗函数聚合计算的时候得到的都是7000( “ 1000+2000+2000+2000 ”) -
partition by 和order by可以一起使用
rank(),dense_rank(),row_number()
- dence_rank在并列关系是,相关等级不会跳过。rank则跳过
- rank()是跳跃排序,有两个第二名时接下来就是第四名(同样是在各个分组内)
- dense_rank()l是连续排序,有两个第二名时仍然跟着第三名。
- row_number() 【语法】ROW_NUMBER() OVER (PARTITION BY COL1 ORDER BY COL2)
【功能】表示根据COL1分组,在分组内部根据 COL2排序,而这个值就表示每组内部排序后的顺序编号(组内连续的唯一的)
row_number() 返回的主要是“行”的信息,并没有排名
聚合函数
聚合函数,是对一组值进行计算并且返回单一值的函数:sum—求和,count—计数,max—最大值,avg—平均值等
WHERE 和 HAVING的区别
从整体声明的角度来理解:
Where是一个约束声明,在查询数据库的结果返回之前对数据库中的查询条件进行约束,即在结果返回之前起作用,且where后面不能使用聚合函数
Having是一个过滤声明,所谓过滤是在查询数据库的结果返回之后进行过滤,即在结果返回之后起作用,并且having后面可以使用聚合函数。
从使用的角度来看:
where后面之所以不能使用聚合函数是因为where的执行顺序在聚合函数之前;
having一般跟在group by之后,执行记录组选择的一部分来工作的。where则是执行所有数据来工作的。
不同的连接方式
INNER JOIN:如果表中有至少一个匹配,则返回行(可以理解为求并集)
LEFT JOIN:即使右表中没有匹配,也从左表返回所有的行
RIGHT JOIN:即使左表中没有匹配,也从右表返回所有的行
FULL JOIN:只要其中一个表中存在匹配,则返回行
SQL语句的内部执行顺序
(1)from
(3) join
(2) on
(4) where
(5)group by(开始使用select中的别名,后面的语句中都可以使用)
(6) avg,sum…
(7)having
(8) select
(9) distinct
(10) order by