前段时间开始研究图像检索,进展困难,于是回归基础,捧起PRML一书,无奈看起来极其晕乎,参考AN的的讲义才有点初步的认识。
1、概述:什么是生成学习算法
两类学习算法:判别学习算法(discriminative learning algorithm)和生成学习算法(generative learning algorithm)。DLA通过建立输入空间X与输出标注{1, 0}间的映射关系学习得到p(y|x)。而GLA首先确定p(x|y)和p(y),由贝叶斯准则得到后验分布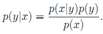 。通过最大后验准则进行预测,也即
。通过最大后验准则进行预测,也即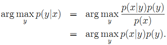 。
。
2、GDA(Gaussian Discriminant Analysis model)高斯判决模型
模型:二类问题
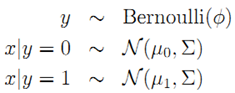 =============>
=============>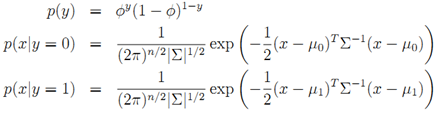
其中,输入特征x是连续随机变量。
训练:
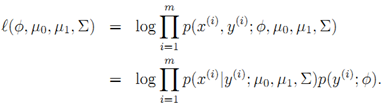
对四个参数分别求极值(闭式解):
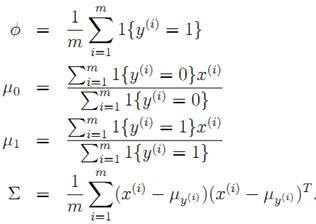
GDA的优势:由于有高斯分布的先验信息,如果确实符合实际数据,则只需要少量的样本就可以得到较好的模型。对比之下,logistic回归模型有更好的鲁棒性。
3、Naive Bayes
输入特征X离散特征,并且有Naïve Bayes assumption,即xi在y的条件下独立:
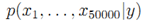
 ,n为词表的维数。
,n为词表的维数。
训练模型(联合概率分布):给定训练样本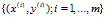
 ,
,
其中 ,
,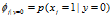 ,
,
闭式解:

预测:输入一个n维特征值(如词表),由贝叶斯准则得到后验概率

由最大后验准则得到分类结果。
4、Laplace平滑
解决问题:"新词"问题。(0/0)本质是输入样本特征空间维数的提升,旧的模型无法提供有效分类信息。
方法:拉普拉斯平滑,约束条件

5、文本分类的事件模型