1. Schema.xml
在schema.xml文件中,主要配置了solrcore的一些数据信息,包括Field和FieldType的定义等信息,在solr中,Field和FieldType都需要先定义后使用。

1.1 Filed(定义Field域)

- Name:指定域的名称
- Type:指定域的类型
- Indexed:是否索引
- Stored:是否存储
- Required:是否必须
- multiValued:是否多值,比如商品信息中,一个商品有多张图片,一个Field像存储多个值的话,必须将multiValued设置为true。
1.2 dynamicField(动态域)

- Name:指定动态域的命名规则
1.3 uniqueKey(指定唯一键)

其中的id是在Field标签中已经定义好的域名,而且该域要设置为required为true。
一个schema.xml文件中必须有且仅有一个唯一键
1.4 copyField(复制域)

- Source:要复制的源域的域名
- Dest:目标域的域名
由dest指的的目标域,必须设置multiValued为true。
1.5 FieldType(定义域的类型)
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100"> <analyzer type="index"> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" /> <!-- in this example, we will only use synonyms at query time <filter class="solr.SynonymFilterFactory" synonyms="index_synonyms.txt" ignoreCase="true" expand="false"/> --> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> <analyzer type="query"> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" /> <filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> </fieldType>
- Name:指定域类型的名称
- Class:指定该域类型对应的solr的类型
- Analyzer:指定分析器
- Type:index、query,分别指定搜索和索引时的分析器
- Tokenizer:指定分词器
- Filter:指定过滤器
2. 中文分词器(ikanalyzer)
第一步:将ikanalyzer的jar包拷贝到以下目录

第二步:将ikanalyzer的扩展词库的配置文件拷贝到 目录

第三步:配置FieldType

第四步:配置使用中文分词的Field

第五步:重启tomcat
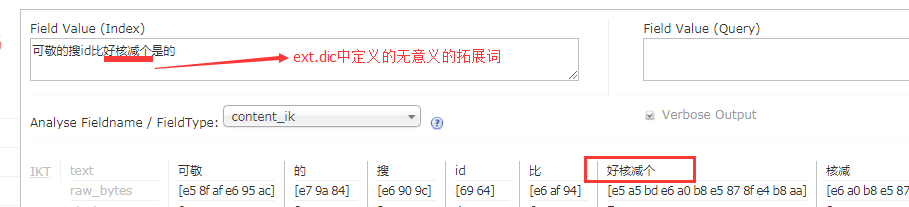
3. Dataimport(该插件可以将数据库中指定的sql语句的结果导入到solr索引库中)
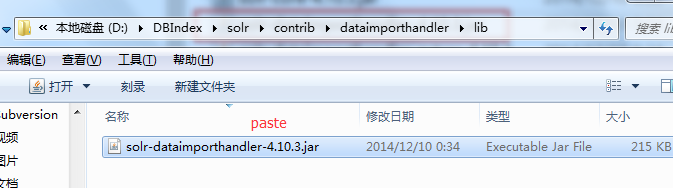
第一步:添加Dataimport的jar包
复制以下目录的jar包

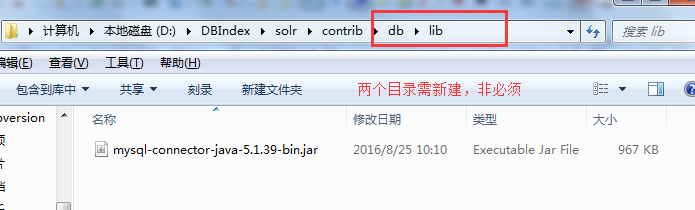
添加到以下目录(lib目录需要新建)
修改solrconfig.xml文件,添加lib标签
<lib dir="${solr.install.dir:../..}/contrib/dataimporthandler/lib" regex=".*.jar" />
将mysql的驱动包,复制到以下目录
修改solrconfig.xml文件,添加lib标签
<lib dir="${solr.install.dir:../..}/contrib/db/lib" regex=".*.jar" />
第二步:配置requestHandler
在solrconfig.xml中,添加一个dataimport的requestHandler

第三步:创建data-config.xml
在solrconfig.xml同级目录下,创建data-config.xml

第四步:重启tomcat
