1. 前言
ShardingSphere-JDBC 是 Apache ShardingSphere 的第一个产品,也是 Apache ShardingSphere 的前身。 定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
- 适用于任何基于 JDBC 的 ORM 框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template 或直接使用 JDBC。
- 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP 等。
- 支持任意实现 JDBC 规范的数据库,目前支持 MySQL,Oracle,SQLServer,PostgreSQL 以及任何遵循 SQL92 标准的数据库。

下面基于ShardingSphere-JDBC实现分库分表。框架基于SpringBoot2.1.2.RELEASE,结合 shardingsphere和 mybatis-plus实现。
2. 分库分表实现
2.1 数据库搭建
user_db_1(ds0)
├── user_0
└── user_1
user_db_2(ds1)
├── user_0
└── user_1
数据库user_db_1(别名:ds0)
CREATE DATABASE /*!32312 IF NOT EXISTS*/`user_db_1` /*!40100 DEFAULT CHARACTER SET utf8mb4 */; USE `user_db_1`; /*Table structure for table `user_0` */ DROP TABLE IF EXISTS `user_0`; CREATE TABLE `user_0` ( `id` bigint(20) NOT NULL, `name` varchar(255) DEFAULT NULL, `age` int(11) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; /*Table structure for table `user_1` */ DROP TABLE IF EXISTS `user_1`; CREATE TABLE `user_1` ( `id` bigint(20) NOT NULL, `name` varchar(255) DEFAULT NULL, `age` int(11) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
数据库user_db_2(别名:ds1)
CREATE DATABASE /*!32312 IF NOT EXISTS*/`user_db_2` /*!40100 DEFAULT CHARACTER SET utf8mb4 */; USE `user_db_2`; /*Table structure for table `user_0` */ DROP TABLE IF EXISTS `user_0`; CREATE TABLE `user_0` ( `id` bigint(20) NOT NULL, `name` varchar(255) DEFAULT NULL, `age` int(11) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; /*Table structure for table `user_1` */ DROP TABLE IF EXISTS `user_1`; CREATE TABLE `user_1` ( `id` bigint(20) NOT NULL, `name` varchar(255) DEFAULT NULL, `age` int(11) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
数据库结构和表结构需要保持一致:

2.2 搭建工程
2.2.1 依赖
pom.xml
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.1.2.RELEASE</version> <relativePath/> <!-- lookup parent from repository --> </parent> <groupId>com.zang</groupId> <artifactId>shadingjdbc</artifactId> <version>0.0.1-SNAPSHOT</version> <name>shadingjdbc</name> <description>Demo project for Spring Boot</description> <properties> <java.version>1.8</java.version> </properties> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>druid-spring-boot-starter</artifactId> <version>1.1.20</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> </dependency> <dependency> <groupId>org.apache.shardingsphere</groupId> <artifactId>sharding-jdbc-spring-boot-starter</artifactId> <version>4.0.0-RC1</version> </dependency> <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-boot-starter</artifactId> <version>3.4.1</version> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> </dependency> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-web</artifactId> <version>5.1.4.RELEASE</version> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> <configuration> <excludes> <exclude> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> </exclude> </excludes> </configuration> </plugin> </plugins> </build> </project>
2.2.2 实体类
import com.baomidou.mybatisplus.annotation.TableName; import com.baomidou.mybatisplus.extension.activerecord.Model; import lombok.Data; @Data @TableName("user") public class User extends Model<User> { private Long id; private String name; private Integer age; }
2.2.3 dao层
import com.baomidou.mybatisplus.core.mapper.BaseMapper; import com.zang.shadingjdbc.model.User; import org.springframework.stereotype.Repository; @Repository public interface UserMapper extends BaseMapper<User> { }
2.2.4 service层
import com.baomidou.mybatisplus.extension.service.IService; import com.zang.shadingjdbc.model.User; import java.util.List; public interface UserService extends IService<User> { void insert(User user); User findById(Long id); List<User> findAll(); }
import com.baomidou.mybatisplus.core.toolkit.Wrappers; import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl; import com.zang.shadingjdbc.mapper.UserMapper; import com.zang.shadingjdbc.model.User; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.stereotype.Service; import java.util.List; @Service public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements UserService{ @Autowired private UserMapper userMapper; @Override public void insert(User entity) { userMapper.insert(entity); } @Override public User findById(Long id) { return userMapper.selectById(id); } @Override public List<User> findAll() { return userMapper.selectList(Wrappers.<User>lambdaQuery()); } }
2.3 分库分表配置
ShardingSphere-JDBC在工程中的核心就是其配置。这里使用配置文件方式实现分库以及分表。
# 数据源 ds0,ds1 spring.shardingsphere.datasource.names=ds0,ds1 # 第一个数据库 spring.shardingsphere.datasource.ds0.type=com.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.cj.jdbc.Driver spring.shardingsphere.datasource.ds0.jdbc-url=jdbc:mysql://localhost:3306/user_db_1?characterEncoding=utf-8&&serverTimezone=GMT%2B8 spring.shardingsphere.datasource.ds0.username=root spring.shardingsphere.datasource.ds0.password=123 # 第二个数据库 spring.shardingsphere.datasource.ds1.type=com.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.cj.jdbc.Driver spring.shardingsphere.datasource.ds1.jdbc-url=jdbc:mysql://localhost:3306/user_db_2?characterEncoding=utf-8&&serverTimezone=GMT%2B8 spring.shardingsphere.datasource.ds1.username=root spring.shardingsphere.datasource.ds1.password=123 # 指定course表里面主键cid 生成策略 SNOWFLAKE spring.shardingsphere.sharding.tables.user.key-generator.column=id spring.shardingsphere.sharding.tables.user.key-generator.type=SNOWFLAKE # 水平拆分的数据库(表) 配置分库 + 分表策略 行表达式分片策略 # 分库策略 id为偶数添加到ds0,奇数添加到ds1 spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=id spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression=ds$->{id % 2} # 分表策略 其中user为逻辑表 分表主要取决于age行 spring.shardingsphere.sharding.tables.user.actual-data-nodes=ds$->{0..1}.user_$->{0..1} spring.shardingsphere.sharding.tables.user.table-strategy.inline.sharding-column=age # 分片算法表达式 age为偶数时分配到user_0,奇数时分配到user_1 spring.shardingsphere.sharding.tables.user.table-strategy.inline.algorithm-expression=user_$->{age % 2} # 打开SQL输出日志 spring.shardingsphere.props.sql.show=true # 一个实体类对应两张表,覆盖 spring.main.allow-bean-definition-overriding=true
部分说明:
逻辑表 user
水平拆分的数据库(表)的相同逻辑和数据结构表的总称。例:用户数据根据主键尾数拆分为2张表,分别是user0到user1,他们的逻辑表名为user。
真实表
在分片的数据库中真实存在的物理表。即上个示例中的user0到user1
分片算法:
Hint分片算法
对应HintShardingAlgorithm,用于处理使用Hint行分片的场景。需要配合HintShardingStrategy使用。
分片策略:
行表达式分片策略 对应InlineShardingStrategy。使用Groovy的表达式,提供对SQL语句中的=和IN的分片操作支持,只支持单分片键。对于简单的分片算法,可以通过简单的配置使用,从而避免繁琐的Java代码开发,如: user$->{id % 2} 表示user表根据id模2,而分成2张表,表名称为user0到user_1。
自增主键生成策略
通过在客户端生成自增主键替换以数据库原生自增主键的方式,做到分布式主键无重复。 采用UUID.randomUUID()的方式产生分布式主键。或者 SNOWFLAKE
2.4 单元测试
这里使用单元测试来模拟业务调用。
import com.zang.shadingjdbc.model.User; import com.zang.shadingjdbc.service.UserService; import org.junit.Test; import org.junit.runner.RunWith; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.test.context.SpringBootTest; import org.springframework.test.context.junit4.SpringRunner; import java.util.List; @RunWith(SpringRunner.class) @SpringBootTest public class ShadingjdbcApplicationTests { @Autowired private UserService userService; @Test public void addUserDb() { for (int i = 21; i < 40; i++) { User user = new User(); user.setName("zhangsan"+i); user.setAge(i); userService.insert(user); } } @Test public void findAllUser() { List<User> userList = userService.findAll(); System.out.println(userList.size()); } @Test public void findUser() { User user = userService.findById(1346047719665295361L); System.out.println(user.getName()); } }
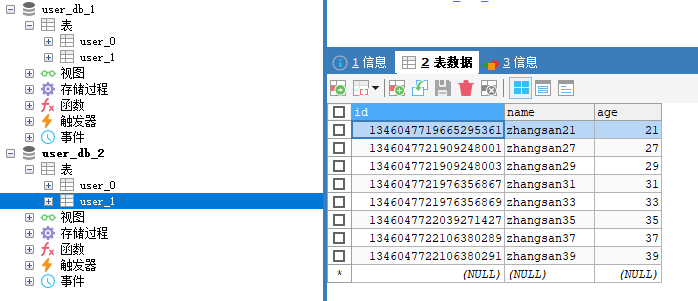
2.4.1 数据存储
执行单元测试的 addUserDb方法,查看数据是按照配置的策略进行存储。
2.4.2 单个数据查询
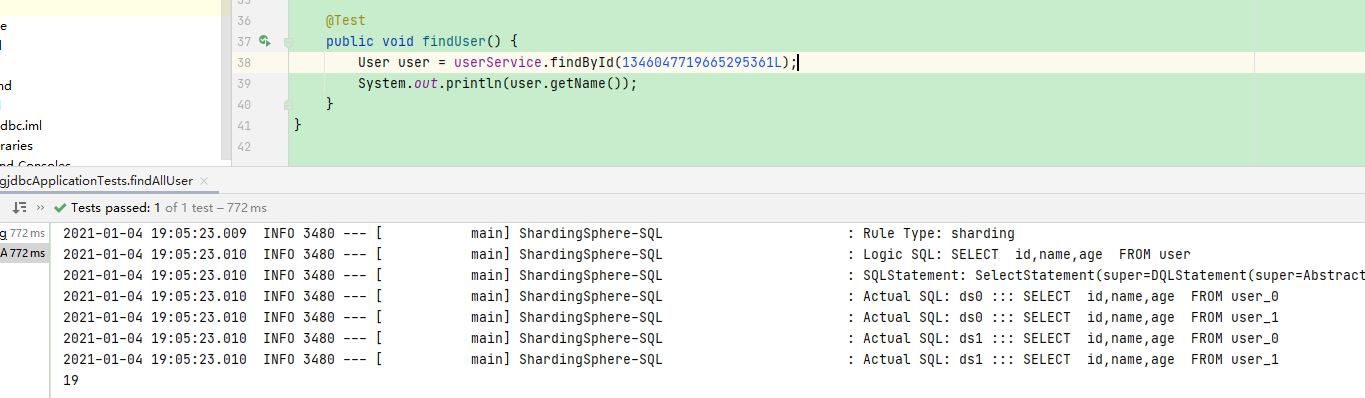
执行单元测试的 findUser方法,可以看到其根据分库策略匹配到ds1库,对库中的表进行查询;因为分表字段age没有传入,所以没有定位到ds1中的表,查询执行了两次。

2.4.3 查询所有数据
执行单元测试的 findAllUser方法,可以看到其将所有库表都查询一遍。
以上,即实现了简单的分库分表。