1. 跑批是什么
顾名思义,就是应用程序对数据的批量处理。
跑批有以下特性:
- 大数据量:批量任务一般伴随着大量的数据处理;
- 自动化:要求制定时间或频率自动运行;
- 性能:要求在指定时间内完成批处理任务。
2. 跑批应用场景
在开发中常见的跑批应用场景如下(以目前做的系统举例):
- 定时的数据状态更新:到期失效
- 数据的计算:计算罚息、计提
- 文件处理:与其他应用系统同步,如还款计划同步
- 生成文件:对账、提供同步文件
在跑批开发中有一些存有潜在隐患的处理方式需要指出来:
- 对文件内或数据库数据一次性读取、查询加载到内存
- 基于要处理的数据进行循环,循环内部操作数据库
- 对数据逐条处理
- 事务范围基于整个跑批管理
- 有关联的跑批任务人为设定定时执行时间
3. 优化思考
当前的资源现状:
- 服务器资源利用率低,生产环境按照集群部署,跑批触发只会调度到其中一台
- CPU利用率低,被调度到的机器单线程运行整个任务
- 任务执行间隔时间内服务器资源空闲
批处理的核心思想:
分片:
- 对交易数据进行拆分成多个小片,且每一片都能够快速定位
- 任何数据只要有顺序,就能够分片
并发:
- 调度服务器层面使用广播策略,充分利用服务器资源
- 单个服务器内部通过线程池进行并发处理多片数据,充分利用CPU资源
- 纯运算型可通过 lambda并行流运算(前提是基础数据量足够多)
任务流:
- 前后关系紧密任务组成任务流,避免间隔时间资源空闲
- 对任务拆分为任务组件,不同任务支持不同的路由策略
4. 数据分片分析
4.1 数据准备
如下图,准备了200万的数据:
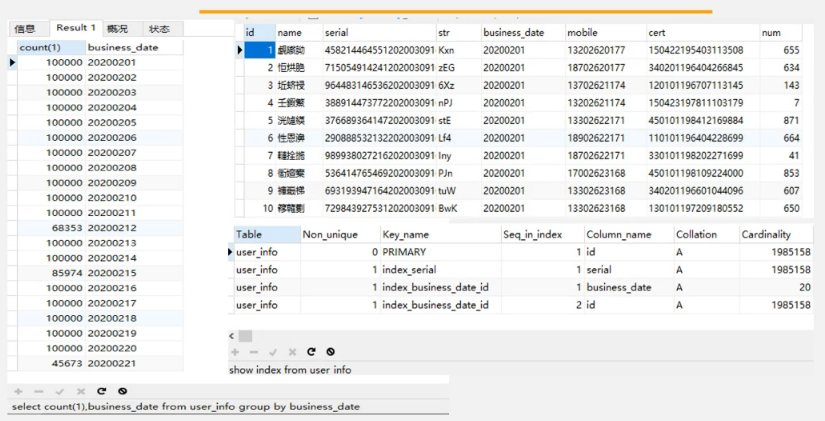
4.2 利用limit
测试最简单的分片逻辑——limit的执行效率:
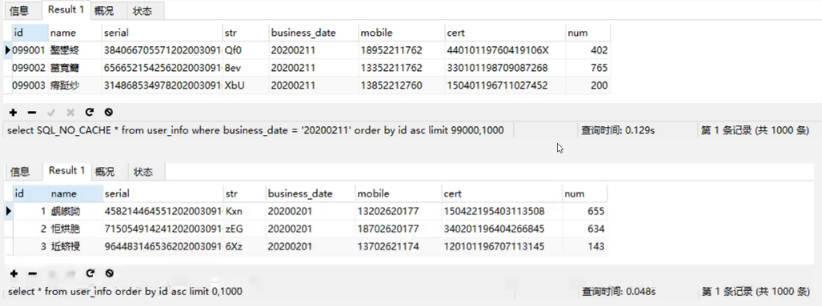


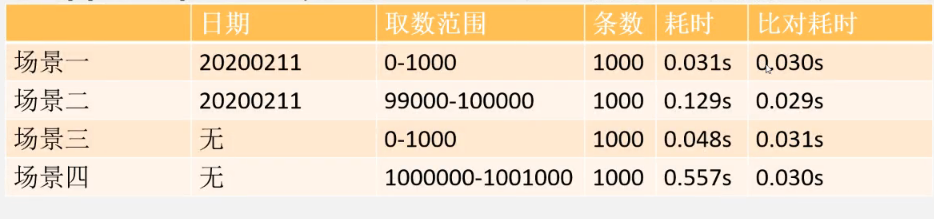
上面四种limit的耗时统计如下:
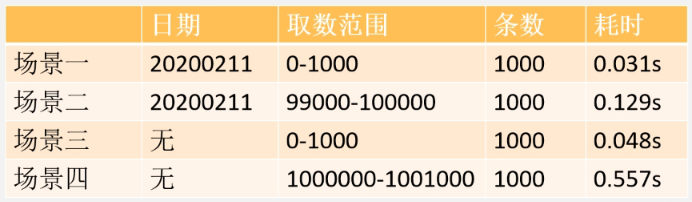
可以看出,随着起始记录的增加,查询时间也随着增大, 这说明分页语句limit跟起始页码是有很大关系的,所以limit 对记录很多的表并不适合直接使用。
4.3 分片优化——id>=形式
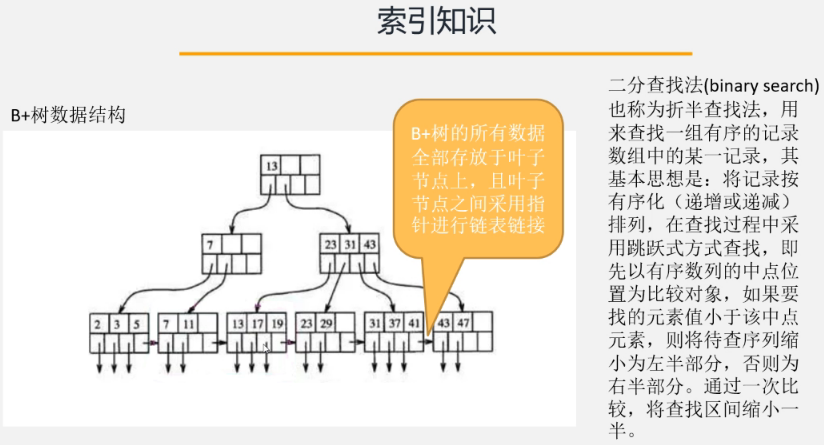
利用索引的排序特性与叶子节点链表链接特性以及快速定位数据所在位置的二分查找法,对分片进行优化。
下面是加条件查询:
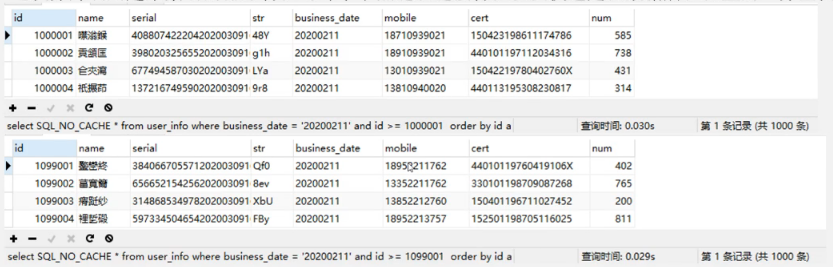
对全表查询,速度也有很大提升:
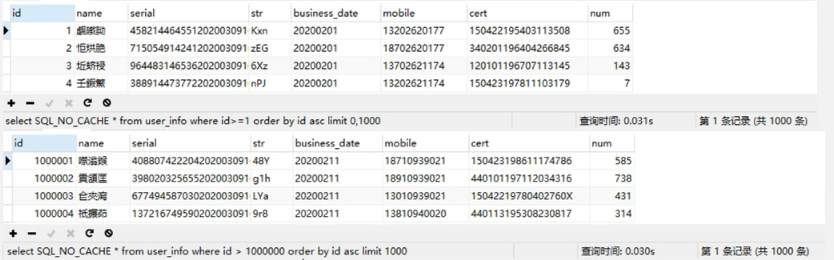
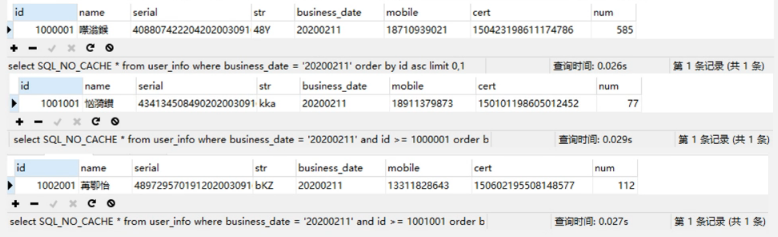
将两次查询进行比对:
很明显,当我们使用id进行范围查询的时候,查询效率趋于平稳且快速,那么只需要确定每一片需要使用的查询条件的id值与 business_date值,业务场景上一般按照业务日期进行跑批,日期是已知确定的,id可以通过lmit1000,1获取。
以此类推,10万数据按照1000条一片需要进行100次分片条件查询,预计平均耗时在3秒以内可以得到一组分片条件数据。
4.4 分片再优化——覆盖索引

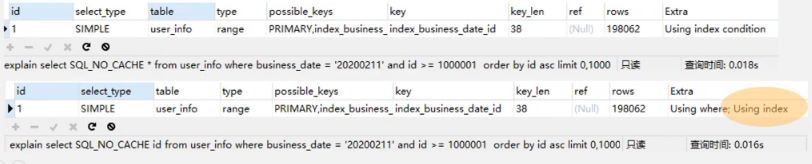
针对覆盖索引的知识,对分片SQL进一步优化,对于 business date与id本身已经是联合索引,而分片的条件只需要返回id。

如上,为了验证覆盖索引效果,对查询执行了N次,提取出来各自执行能达到的最短时间,最小值提升了2毫秒。
通过explain,仅查询id字段是用到了覆盖索引。
5. 分片结果的高效使用
系统中的批量任务是基于开源项目xxl-job进行调度执行的,项目详见作者博客 许雪里 。
在该项目落地过程中,有些问题浮现:
- 前面已经将数据完成分片,这个时候分片结果我们需要有个地方进行存储
- 需要注意的是分片是单机调度执行的,那么分片后,我们需要调度所有能够执行任务的机器,基于xxl-job调度框架,我们需要配置广播策略
- 每个机器节点基于数据存储的地方获取分配给自己的任务:xxl-job会通知到任务机器当前是第几个节点,基于这个值对分片数取模可以得到任务
- 每个节点可以独立起线程池将任务列表用多线程并发执行
- 系统中有好多模块要执行任务,是否要重复写相同的处理逻辑
所以基于上面的思路,为避免各个子系统对于分片存储和广播通知后多线程执行逻辑重复造轮子,对xxl-job进行了适配改造,具体改造点:
- 在分片任务执行完成后返回分片结果有调度器进行保存
- 保存的分片结果自动分配给各节点
- 在任务执行器中,会自动进行多线程调度
- 基于任务的作业图:可以将分片任务组件与任务执行组件进行绘图配置前后执行关系,并且不同仼务组件配置不同的路由策略,比如分片任务随机路由,任务执行配广播策略
- 针对不同的任务间执行顺序管理,通过作图方式绘制出任务流
6. MySQL数据库批量操作
当业务设计到数据库操作时,相比较于单条的新增或更新,批量的执行效率更高,所以涉及到批量的业务,能够使用批量就尽量使用批量。
批量插入:
insert into table_name(column1,column2,column3) values ('column11','column12','column13'),('column21','column22','column23')···
批量更新:
update table_name set column_name = 'column1' where column_name2 = 'column2';update table_name set column_name = 'column3' where column_name2 = 'column4';···
需要在数据库连接上开启批量操作:rewriteBatchedStatements=true&allowMultiQueries=true
master.jdbc.url=jdbc:mysql://127.0.0.1:3306/batch_test?useUnicode=true&characterEncoding=utf8&rewriteBatchedStatements=true&allowMultiQueries=true
7. 读取文件优化

对文件进行分片,文件中有一个元素,天然是有序的:行号。且按照行进行分片能够保证一片内数据完整性。
可以使用Java IO提供的RandomAccessFile类来进行文件的解析,主要基于以下三个方法:

分片思路:
- 开始对文件进行分片,初始指针位置为0,假设每1000行为一片,文件头为第一行,先读取一行
- 第一片记为第2行头部指针位置,从此位置开始读1000行
- 第二片记为第1002行头部指针位置,从此位置开始读1000行
- 依次类推,整个文件全部分片完成
- 各个分片被执行的时候只需要通过指针位置可以直接定位到数据点开始读取1000行
此外,Java NIO类SeekableByteChannel同样支持随机访问,只是没有整行读取功能,需要识别字节中是否有换行符,性能上强于RandomAccessFile。
8. 生成文件优化

优化思路:
- 每个服务器并发多线程生成单独的子文件
- 每个服务器本地文件进行合并为该服务器处理部分数据子文件
- 每个服务器对合并后的文件上传文件服务器汇聚,文件名可以带上服务器的独特标示
- 调度某个服务器独立进行文件服务器上文件合并动作,补充需要的文件内容,如头信息、数据量,压缩、加密处理等