一. 模块的导入:-import,执行对应的文件并引入变量名
为了编写可维护的代码,我们把很多函数分组,分别放到不同的文件里,这样每个文件包含的代码就相对较少,很多编程语言都采用这种组织代码的方式。在Python中,一个.py文件就称之为一个模块(module)。
使用模块最大的好处是提高了代码的可维护性;其次,提高了代码开发的效率,编写代码不必从零开始,当一个模块编写完成,就可以被其他地方引用,同时,我们在编写程序的时候,也可以引用其他模块,包括Python内置的模块和来自第三方的模块。
所以,模块总共有三种:
- Python标准库
- 第三方模块
- 应用程序自定义模块
此外,使用模块还可以避免函数名和变量名冲突。相同名字的函数和变量完全可以分别存在不同的模块中,因此,在我们自己编写模块时,不必考虑函数或变量命名是否与其他模块中命名重复。但是也要注意,自定义函数或变量的命名尽量不要与内置函数名冲突。
1. 将执行文件本身作为模块导入
1 x = 111
2 y = 222
3
4 import sys
5 obj = sys.modules[__name__]
6 print(getattr(obj,'x'))
2. 执行文件同层导入,执行文件与模块的文件路径如下

1 #cal.py文件内容
2
3 def add(x, y):
4 return x+y
- 导入方法1:
1 #bin.py文件中导入方法1
2
3 import cal
4 print(cal.add(2,9))
- 导入方法2:
1 #bin.py文件中导入方法2
2
3 from cal import add
4 print(add(2,9))
- 导入方法3:
1 #bin.py文件中导入方法3 2 3 from cal import * 4 print(add(2,9))
注:import语句导入文件时,从执行文件所在的目录处开始搜索目标文件
3. 执行文件跨层导入,执行文件与模块的文件路径如下

1 #cals.test.py文件内容
2
3 def add(x,y):
4 return x+y
1 #cals.main.py文件内容
2
3 from cals import test #模块导入时顶层路径以执行文件所在的路径为参考
4 def run(x,y):
5 print(test.add(x,y))
1 #bin.py文件中导入方法
2
3 from cals import main
4 main.run(2,9)
4. 动态导入模块的方法,执行文件与模块的文件路径如下
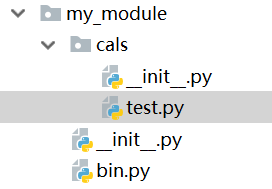
1 #cals.test.py文件内容
2
3 def add(x,y):
4 return x+y
5 def multiply(x,y):
6 return x*y
- 动态导入方法1:
1 #bin.py文件中动态导入方法1
2
3 module_t=__import__('cals.test')
4 print(module_t.test.add(2,9)) #通过导入方法1,可以获取得到顶层模块的内存地址
5 print(module_t.test.multiply(2,11))
- 动态导入方法2:
1 #bin.py文件中动态导入方法2
2
3 import importlib
4 module_t=importlib.import_module('cals.test')
5 print(module_t.add(2,9)) #通过导入方法2,可以直接获取得到底层模块的内存地址
6 print(module_t.multiply(2,11))
二. 包
为了避免模块名冲突,Python又引入了按目录组织模块的方法,称为包(package)。比如,一个abc.py的文件就是一个名字叫abc的模块,一个xyz.py的文件就是一个名字叫xyz的模块,在当abc模块与xyz模块与系统已有的其他模块命名冲突时,我们就可以通过包来组织模块。

引入了包以后,只要顶层的包名不产生冲突,那么位于不同包文件内部的模块之间就不会有命名冲突。
请注意,每个包文件中都包含一个__init__.py文件,这个文件是要求必须存在的,否则,Python就会把这个文件当成普通文件(文件夹)来处理,会丢失包的所有属性。__init__.py可以是空文件,也可以有Python代码,因为__init__.py本身就是一个模块,而它的模块名就是对应的包的名字。
包的导入同模块的导入方法相同,执行文件与待导入包的文件路径如下。

1 #web1.web2.web3.cal.py中文件内容
2
3 def add(x,y):
4 return x+y
- 导入方法1:
1 #bin.py文件中导入方法
2
3 from web1.web2.web3 import cal
4 print(cal.add(2,9))
- 导入方法2:
1 #bin.py文件中导入方法
2
3 from web1.web2.web3.cal import add
4 print(add(2,9))
三. 模块的__name__属性
在执行文件中,__name__='__main__';
在被导入文件中,__name__='所在文件路径'。
- 通常在模块中使用if __name__=='__main__':语句,来检测模块中功能函数的正确性;
- 在执行文件中也可以使用if __name__=='__main__':语句,以防止执行文件被调用。
四. 查看当前文件路径的方法
- 查看包含当前文件的文件路径:
1 #查看包含bin.py文件的文件路径
2
3 import os
4 print(os.path.abspath(__file__))
5
6 """
7 运行结果:
8 H:MyPythonmy_modulein.py
9 """
- 查看包含当前文件的上层目录:
1 #查看包含bin.py文件的上层目录
2
3 import os
4 print(os.path.dirname(__file__))
5
6 """
7 运行结果:
8 H:/MyPython/my_module
9 """