Introduction
增加large-scale context对于目标检测尤其是小物检测质量提升我们多次提到过, 这也很容易理解.
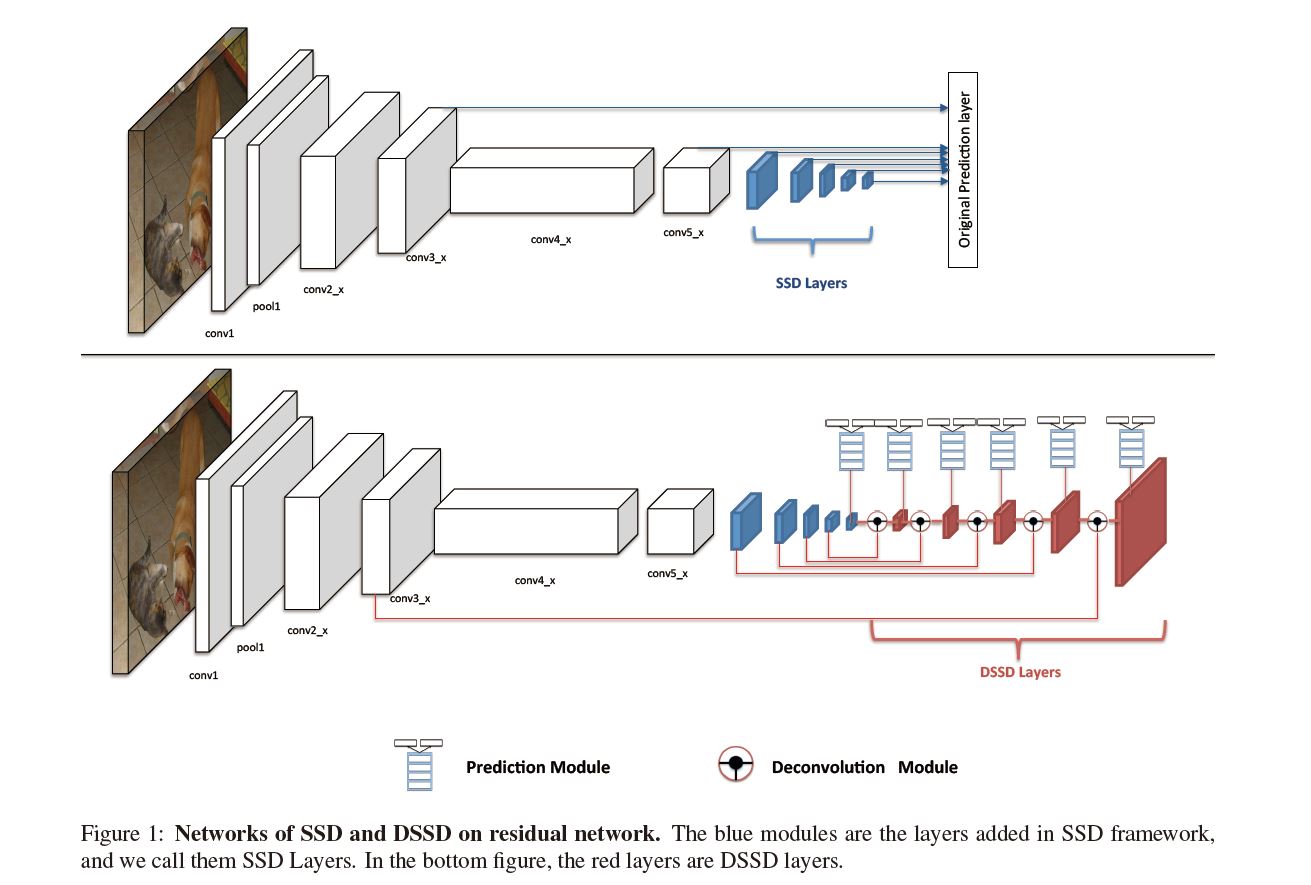
当时流行一种可以融合背景的方法"encoder decoder", 因为其先encode压缩输出尺寸, 后decode扩充尺寸, 看起来像一个漏斗, 因此也常称为漏斗式, 常常又是对称形式所以称为对称漏斗, 但本文中是非对称形式. 作者便将此形式改进后加入SSD后层, 结构如下图所示:
Related Work
利用single-scale输出预测multi-scale物体天生劣势, 作者从multi-scale考虑, 主要有两种表现形式:
- 将各层的feature map融合, 因为融合的feature map来自图片的各个level, 因此池化融合后的输出在classification和localization更具有表现力, 但此方法不仅需要大量储存空间还会降低速度.
- 直接使用各层的feature map, 各层输出感受野各不相同, 用大的感受野检测大型物体, 用小的感受野检测小型物体. 但是为了检测小型物体, 当时的做法多是直接利用浅层的输出, 但是因为浅层网络语义信息较少最终表现并不好.
作者就是从第二种方式得到启发, 使用反卷积和skip connection扩大图像, 这样除了能提升分辨率, 还能保证语义信息充足_(感受野似乎变小?)_.
这里我想所谓第一种表现力更强可能是因为直接相加, 将激活集中到同一张map中, 对于所谓增加储存空间可能因为需要反向传播因此要保存各层的map, 还要保存融合中间过程中的map, 这样速度也会有相应影响.
Deconvolutional Single Shot Detection (DSSD) model
Using Residual101 in place of VGG
首先作者将SSD的backbone换为ResNet-101, 并在其后加入数个卷积层, 单纯加卷积层并不能直接提升精度, 但是在这些后加入即将提到的prediction module后却能极大的提升精度.
Prediction module
原本SSD因为梯度太大, 对各层输出的feature map直接利用进行预测. 后来有人提出使用子网络可以提升效果, 那么本文就如下图所示加入一个残差模块(c): 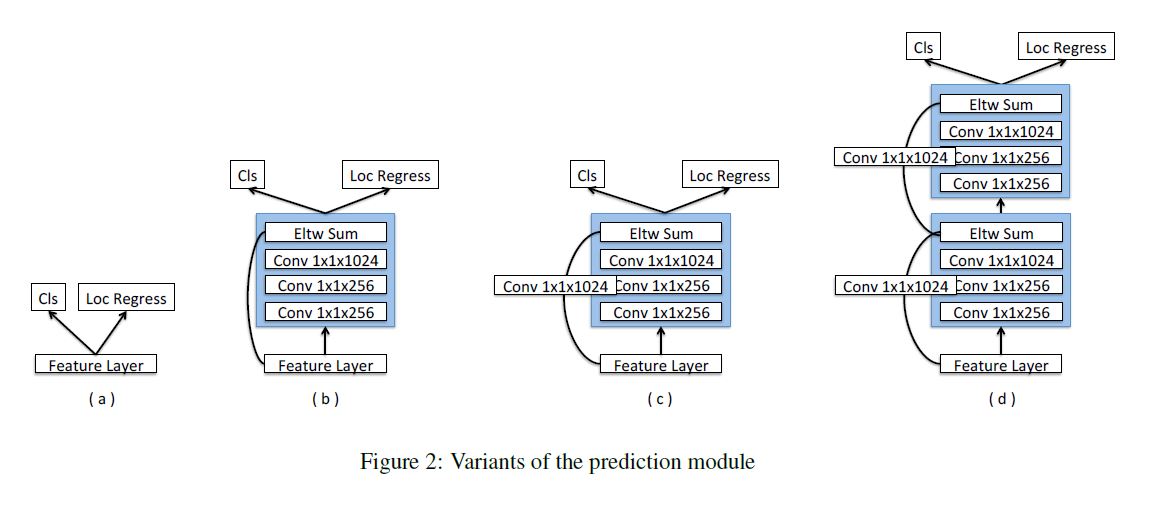
(a)是SSD原始模块, (b)是基础残差模块, (d)是双层改进残差模块.
Deconvolutional SSD
反卷积紧接SSD后方, 本文使用是一种非对称漏斗结构而非先前所说的对称漏斗, 即下图中的DSSD Layers部分:
我们可以注意首先有skip connection, 这也是本文的一大改进, 其次还有漏斗网络不对称, 尤其是decode层很少, 主要有以下两个原因:
- 为追求速度而简化模型.
- 没有在ILSVRC CLS-LOC上预训练的包含decoder的模型, 因为预训练好的classification模型比随机初始化模型精度更高
Deconvolution Module
上图中"Deconvolution Module"具体结构如下图所示:
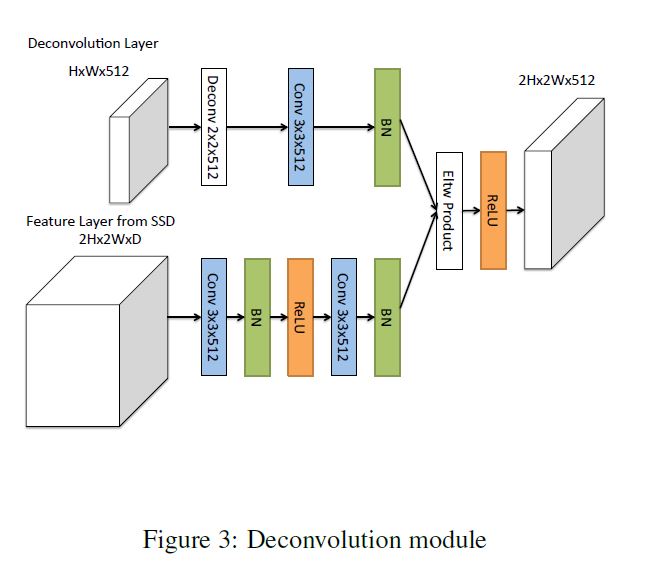
此模块主要有如下几个特点:
- 最后一层加入BN层.
- 使用反卷积而非线形上采样.
- 通过实验证明, 组合时各元素相乘比各元素相加取得更好地结果.
Training
训练策略基本与SSD相同, 首先利用IOU选positive bbox, 其后控制negative: positive = 3: 1, 对计算并反向传播loss...
作者训练时还对样本随机进行广度畸变(photometric distortion), 翻转和剪切.
关于bbox作者使用k-means同时扫参选择最佳数量和最佳比例, 最终得到的结果如下图所示:
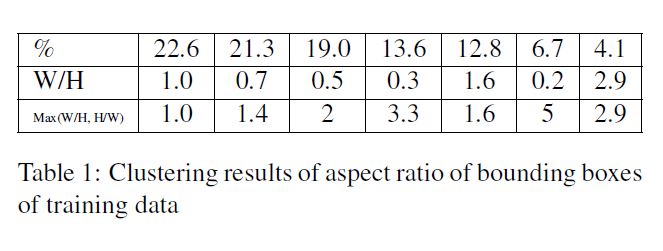
可以发现基本选出的bbox都是较为瘦高, 作者认为一个重要原因是数据集大多较宽而SSD会把他们resample成正方形, 最终将其拉长. 除此之外作者还加入了几个其他比例的bbox预设.
Experiments
Base network
作者把ResNet-101的stride缩小来提升分辨率, 并且用了我们EE中小波分析的方法填充因为缩小stride形成的hole_(很遗憾原理我也不懂, 方法是对于被缩小stride那一阶段的卷积核大于1的卷积层, 将dilation从1变为2, 原理出自M. Holschneider, R. Kronland-Martinet, J. Morlet, and P. Tchamitchian. A real-time algorithm for signal analysis with the help of the wavelet transform. In Wavelets, pages 286–297. Springer, 1990.)_
作者从网络中选取了若干层, 具体如下图所示, 其中depth是指选择层所在整个网络中的位置.
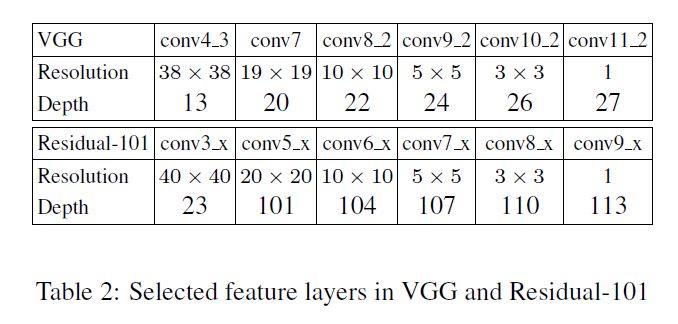
为了提升小物体的检测能力, 必须要使用浅层(conv3_x)的feature map. 同时此阶段卷积核大于1的卷积层只有9个, 那么此阶段和VGG - conv4_3相比分辨率提升感受野减小. 但相应的坏处就是feature map的信息变弱导致预测表现变差.
PASCAL VOC 2007
在低分辨率时ResNet-101和VGG表现相近, 但ResNet收敛更快; 当分辨率提升ResNet超越VGG越1%, 可能与网络深度增加导致在深层网络物体空间信息仍能很好的保存.
在下图中, 作者观察到在特定的条件下(如天空中的飞机, 草原上的羊, 海中的船)DSSD和SSD相比小物检测性能提升较为明显. 图例作图为SSD, 右图为DSSD.



Ablation Study on VOC2007
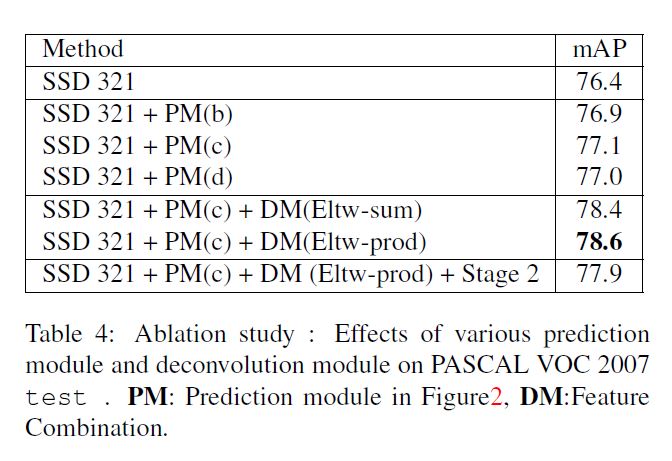
作者拆分各成分实验, 结果如下图, 补充的是:
- 使用两个PM对性能几乎无提升.
- 表中可以看见用元素乘法比加法效果更好.
- 用线形上采样等方法不仅速度慢, 精度提升也有限.
Others
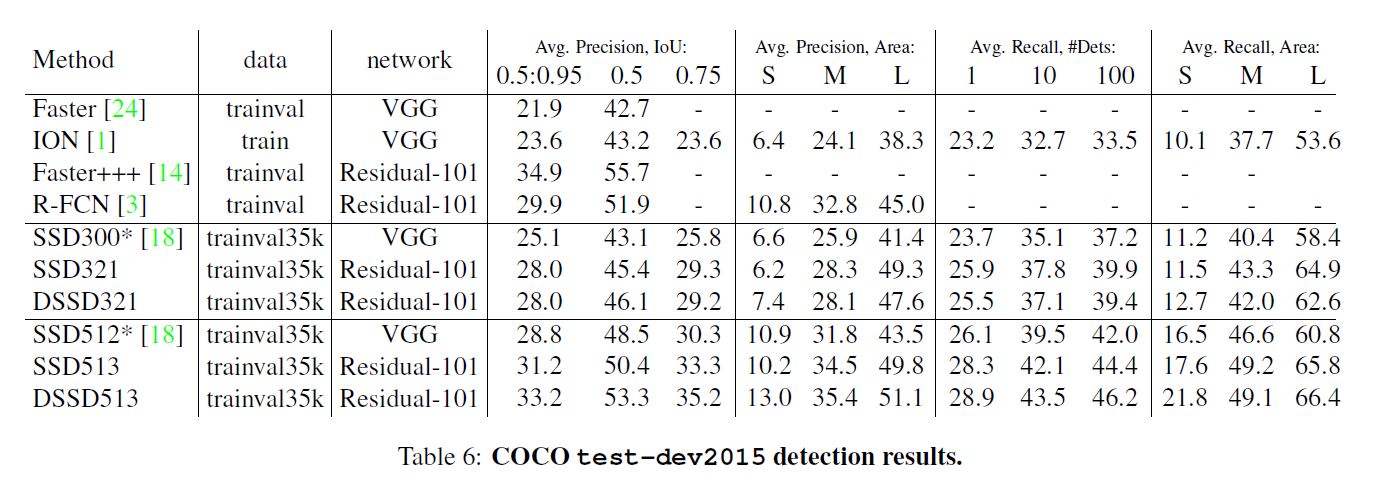
其余的实验从表格中可以直观得出结论, 其中要提一点的是实验都是把SSD的参数freeze掉后训练.

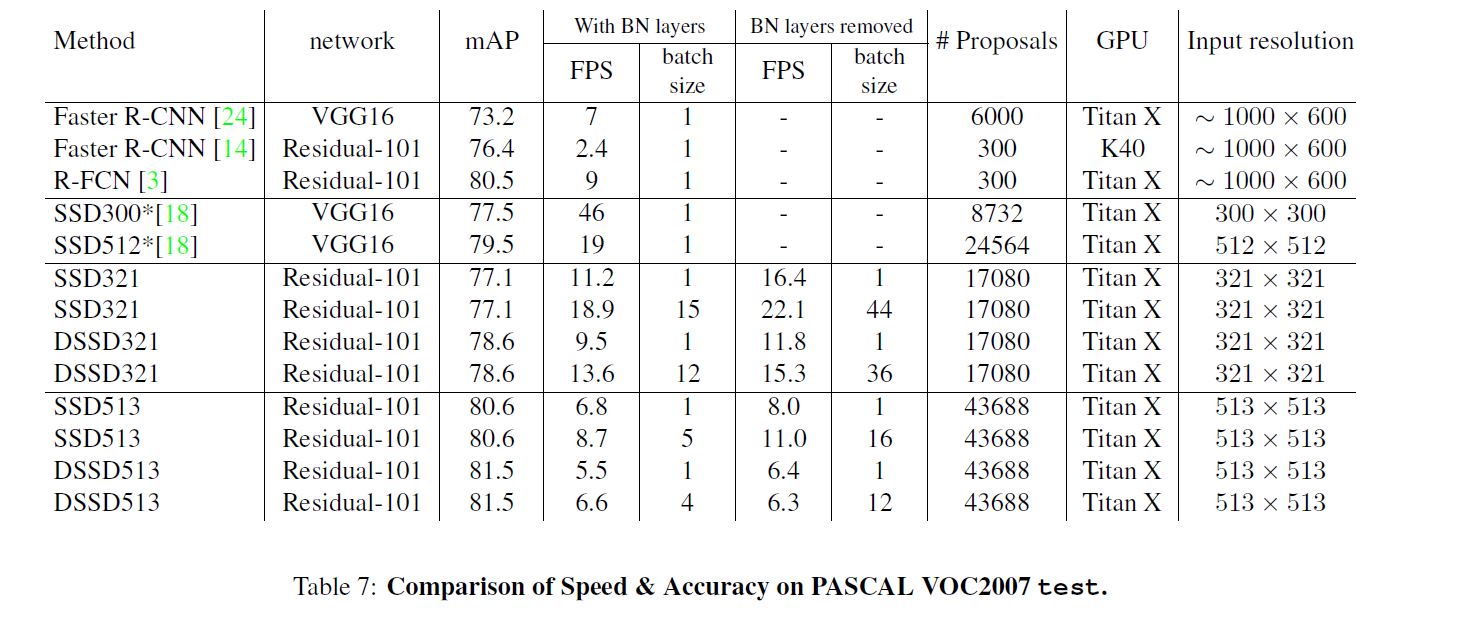
Inference Time
为了提升速度, 作者移除了BN, 作者将卷积层的参数重写, 其中ϵ=1−−5ϵ=1−−5是一个很小的数:
把与BN相关的变量移除, 最后得到下式:
这样大概会取得1.2到1.5倍速度的提升, 同时也减少至多三分之二的内存用量.
最终结果并没有SSD快, 其中重要原因之一是使用更复杂的backbone, 其次是在原来的基础上加入了若干网络, 另外会产生更多的bbox(约2.6倍).
Conclusion
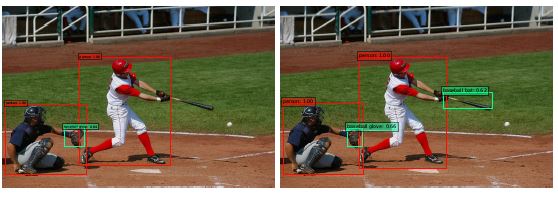
本文主要就是为了提升小物检测的质量, 引入的内容有反卷积和对各层skip和multi-scale预测, 确实从图例上看得出质量有所提升, 但质量仍然有很大的提升空间. 最后除了几张自然图片, 我再补充几张人文类型的图片, 能检测领带和棒球棒.