YOLOV1:
摘要指出了文章的主要创新之处:把分类问题转换为回归问题,使用一个卷积神经网络就可以直接预测物体的bounding box和类别概率。
算法的优点有很多:
- 速度快,Titan X: 45fps。加速版则能达到150fps。
- 基于全局信息检测而不是生成region proposal的方法,可以将背景误检率降低一半(把背景识别成物体)。
- 泛化能力较强,在艺术作品上有较好的结果。
下面是作者论文中给的图:
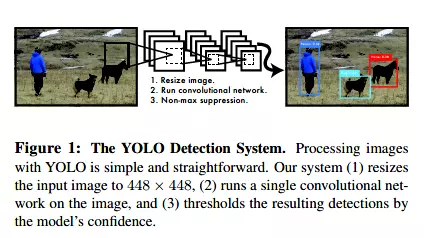
整体来看,Yolo算法采用一个单独的CNN模型实现end-to-end的目标检测,整个系统如图5所示:首先将输入图片resize到448x448,然后送入CNN网络,最后处理网络预测结果得到检测的目标。相比R-CNN算法,其是一个统一的框架,其速度更快,而且Yolo的训练过程也是end-to-end的。
 图5 Yolo检测系统
图5 Yolo检测系统
具体来说,Yolo的CNN网络将输入的图片分割成 网格,然后每个单元格负责去检测那些中心点落在该格子内的目标,如图6所示,可以看到狗这个目标的中心落在左下角一个单元格内,那么该单元格负责预测这个狗。每个单元格会预测
个边界框(bounding box)以及边界框的置信度(confidence score)。所谓置信度其实包含两个方面,一是这个边界框含有目标的可能性大小,二是这个边界框的准确度。前者记为
,当该边界框是背景时(即不包含目标),此时
。而当该边界框包含目标时,
。边界框的准确度可以用预测框与实际框(ground truth)的IOU(intersection over union,交并比)来表征,记为
。因此置信度可以定义为
。很多人可能将Yolo的置信度看成边界框是否含有目标的概率,但是其实它是两个因子的乘积,预测框的准确度也反映在里面。边界框的大小与位置可以用4个值来表征:
,其中
是边界框的中心坐标,而
和
是边界框的宽与高。还有一点要注意,中心坐标的预测值
是相对于每个单元格左上角坐标点的偏移值,并且单位是相对于单元格大小的,单元格的坐标定义如图6所示。而边界框的
和
预测值是相对于整个图片的宽与高的比例,这样理论上4个元素的大小应该在
范围。这样,每个边界框的预测值实际上包含5个元素:
,其中前4个表征边界框的大小与位置,而最后一个值是置信度。
 图6 网格划分
图6 网格划分
还有分类问题,对于每一个单元格其还要给出预测出 个类别概率值,其表征的是由该单元格负责预测的边界框其目标属于各个类别的概率。但是这些概率值其实是在各个边界框置信度下的条件概率,即
。值得注意的是,不管一个单元格预测多少个边界框,其只预测一组类别概率值,这是Yolo算法的一个缺点,在后来的改进版本中,Yolo9000是把类别概率预测值与边界框是绑定在一起的。同时,我们可以计算出各个边界框类别置信度(class-specific confidence scores):
。
边界框类别置信度表征的是该边界框中目标属于各个类别的可能性大小以及边界框匹配目标的好坏。后面会说,一般会根据类别置信度来过滤网络的预测框。
总结一下,每个单元格需要预测 个值。如果将输入图片划分为
网格,那么最终预测值为
大小的张量。整个模型的预测值结构如下图所示。对于PASCAL VOC数据,其共有20个类别,如果使用
,那么最终的预测结果就是
大小的张量。在下面的网络结构中我们会详细讲述每个单元格的预测值的分布位置。
 图7 模型预测值结构
图7 模型预测值结构
网络设计
Yolo采用卷积网络来提取特征,然后使用全连接层来得到预测值。网络结构参考GooLeNet模型,包含24个卷积层和2个全连接层,如图8所示。对于卷积层,主要使用1x1卷积来做channle reduction,然后紧跟3x3卷积。对于卷积层和全连接层,采用Leaky ReLU激活函数: 。但是最后一层却采用线性激活函数。
 图8 网络结构
图8 网络结构
可以看到网络的最后输出为 大小的张量。这和前面的讨论是一致的。这个张量所代表的具体含义如图9所示。对于每一个单元格,前20个元素是类别概率值,然后2个元素是边界框置信度,两者相乘可以得到类别置信度,最后8个元素是边界框的
。大家可能会感到奇怪,对于边界框为什么把置信度
和
都分开排列,而不是按照
这样排列,其实纯粹是为了计算方便,因为实际上这30个元素都是对应一个单元格,其排列是可以任意的。但是分离排布,可以方便地提取每一个部分。这里来解释一下,首先网络的预测值是一个二维张量
,其shape为
。采用切片,那么
就是类别概率部分,而
是置信度部分,最后剩余部分
是边界框的预测结果。这样,提取每个部分是非常方便的,这会方面后面的训练及预测时的计算。
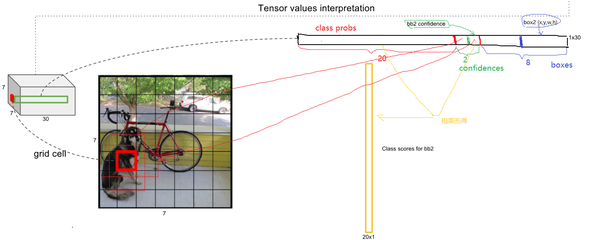 图9 预测张量的解析
图9 预测张量的解析
网络训练
在训练之前,先在ImageNet上进行了预训练,其预训练的分类模型采用图8中前20个卷积层,然后添加一个average-pool层和全连接层。预训练之后,在预训练得到的20层卷积层之上加上随机初始化的4个卷积层和2个全连接层。由于检测任务一般需要更高清的图片,所以将网络的输入从224x224增加到了448x448。整个网络的流程如下图所示:
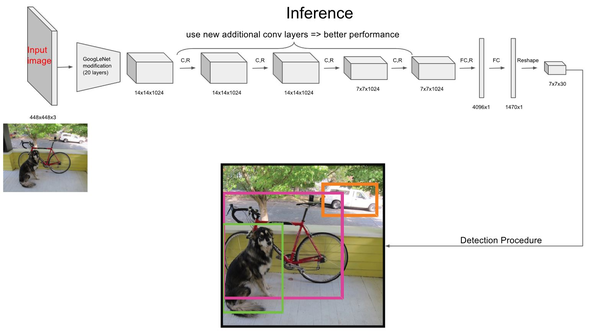 图10 Yolo网络流程
图10 Yolo网络流程
下面是训练损失函数的分析,Yolo算法将目标检测看成回归问题,所以采用的是均方差损失函数。但是对不同的部分采用了不同的权重值。首先区分定位误差和分类误差。对于定位误差,即边界框坐标预测误差,采用较大的权重 。然后其区分不包含目标的边界框与含有目标的边界框的置信度,对于前者,采用较小的权重值
。其它权重值均设为1。然后采用均方误差,其同等对待大小不同的边界框,但是实际上较小的边界框的坐标误差应该要比较大的边界框要更敏感。为了保证这一点,将网络的边界框的宽与高预测改为对其平方根的预测,即预测值变为
。
另外一点时,由于每个单元格预测多个边界框。但是其对应类别只有一个。那么在训练时,如果该单元格内确实存在目标,那么只选择与ground truth的IOU最大的那个边界框来负责预测该目标,而其它边界框认为不存在目标。这样设置的一个结果将会使一个单元格对应的边界框更加专业化,其可以分别适用不同大小,不同高宽比的目标,从而提升模型性能。大家可能会想如果一个单元格内存在多个目标怎么办,其实这时候Yolo算法就只能选择其中一个来训练,这也是Yolo算法的缺点之一。要注意的一点时,对于不存在对应目标的边界框,其误差项就是只有置信度,坐标项误差是没法计算的。而只有当一个单元格内确实存在目标时,才计算分类误差项,否则该项也是无法计算的。
综上讨论,最终的损失函数计算如下:
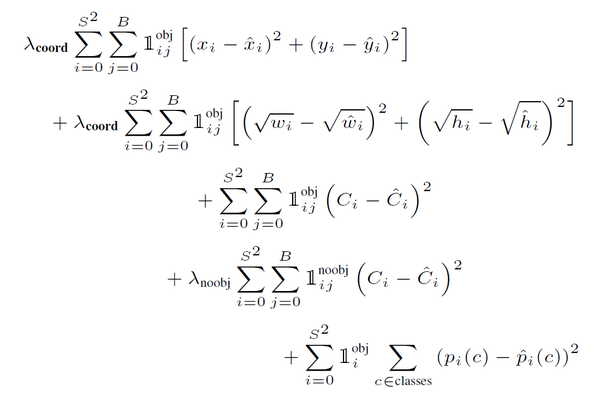
其中第一项是边界框中心坐标的误差项, 指的是第
个单元格存在目标,且该单元格中的第
个边界框负责预测该目标。第二项是边界框的高与宽的误差项。第三项是包含目标的边界框的置信度误差项。第四项是不包含目标的边界框的置信度误差项。而最后一项是包含目标的单元格的分类误差项,
指的是第
个单元格存在目标。这里特别说一下置信度的target值
,如果是不存在目标,此时由于
,那么
。如果存在目标,
,此时需要确定
,当然你希望最好的话,可以将IOU取1,这样
,但是在YOLO实现中,使用了一个控制参数rescore(默认为1),当其为1时,IOU不是设置为1,而就是计算truth和pred之间的真实IOU。不过很多复现YOLO的项目还是取
,这个差异应该不会太影响结果吧。
网络预测
在说明Yolo算法的预测过程之前,这里先介绍一下非极大值抑制算法(non maximum suppression, NMS),这个算法不单单是针对Yolo算法的,而是所有的检测算法中都会用到。NMS算法主要解决的是一个目标被多次检测的问题,如图11中人脸检测,可以看到人脸被多次检测,但是其实我们希望最后仅仅输出其中一个最好的预测框,比如对于美女,只想要红色那个检测结果。那么可以采用NMS算法来实现这样的效果:首先从所有的检测框中找到置信度最大的那个框,然后挨个计算其与剩余框的IOU,如果其值大于一定阈值(重合度过高),那么就将该框剔除;然后对剩余的检测框重复上述过程,直到处理完所有的检测框。Yolo预测过程也需要用到NMS算法。
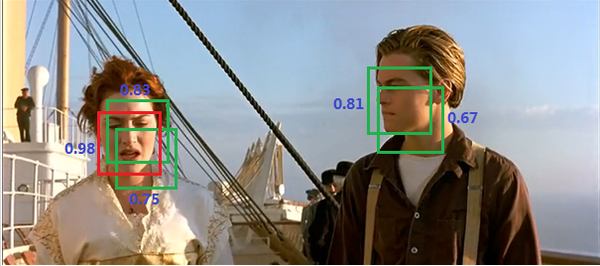 图11 NMS应用在人脸检测
图11 NMS应用在人脸检测
下面就来分析Yolo的预测过程,这里我们不考虑batch,认为只是预测一张输入图片。根据前面的分析,最终的网络输出是 ,但是我们可以将其分割成三个部分:类别概率部分为
,置信度部分为
,而边界框部分为
(对于这部分不要忘记根据原始图片计算出其真实值)。然后将前两项相乘(矩阵
乘以
可以各补一个维度来完成
)可以得到类别置信度值为
,这里总共预测了
个边界框。
所有的准备数据已经得到了,那么我们先说第一种策略来得到检测框的结果,我认为这是最正常与自然的处理。首先,对于每个预测框根据类别置信度选取置信度最大的那个类别作为其预测标签,经过这层处理我们得到各个预测框的预测类别及对应的置信度值,其大小都是 。一般情况下,会设置置信度阈值,就是将置信度小于该阈值的box过滤掉,所以经过这层处理,剩余的是置信度比较高的预测框。最后再对这些预测框使用NMS算法,最后留下来的就是检测结果。一个值得注意的点是NMS是对所有预测框一视同仁,还是区分每个类别,分别使用NMS。Ng在deeplearning.ai中讲应该区分每个类别分别使用NMS,但是看了很多实现,其实还是同等对待所有的框,我觉得可能是不同类别的目标出现在相同位置这种概率很低吧。
上面的预测方法应该非常简单明了,但是对于Yolo算法,其却采用了另外一个不同的处理思路(至少从C源码看是这样的),其区别就是先使用NMS,然后再确定各个box的类别。其基本过程如图12所示。对于98个boxes,首先将小于置信度阈值的值归0,然后分类别地对置信度值采用NMS,这里NMS处理结果不是剔除,而是将其置信度值归为0。最后才是确定各个box的类别,当其置信度值不为0时才做出检测结果输出。这个策略不是很直接,但是貌似Yolo源码就是这样做的。Yolo论文里面说NMS算法对Yolo的性能是影响很大的,所以可能这种策略对Yolo更好。但是我测试了普通的图片检测,两种策略结果是一样的。
 图12 Yolo的预测处理流程
图12 Yolo的预测处理流程
算法性能分析
这里看一下Yolo算法在PASCAL VOC 2007数据集上的性能,这里Yolo与其它检测算法做了对比,包括DPM,R-CNN,Fast R-CNN以及Faster R-CNN。其对比结果如表1所示。与实时性检测方法DPM对比,可以看到Yolo算法可以在较高的mAP上达到较快的检测速度,其中Fast Yolo算法比快速DPM还快,而且mAP是远高于DPM。但是相比Faster R-CNN,Yolo的mAP稍低,但是速度更快。所以。Yolo算法算是在速度与准确度上做了折中。
 表1 Yolo在PASCAL VOC 2007上与其他算法的对比
表1 Yolo在PASCAL VOC 2007上与其他算法的对比
为了进一步分析Yolo算法,文章还做了误差分析,将预测结果按照分类与定位准确性分成以下5类:
- Correct:类别正确,IOU>0.5;(准确度)
- Localization:类别正确,0.1 < IOU<0.5(定位不准);
- Similar:类别相似,IOU>0.1;
- Other:类别错误,IOU>0.1;
- Background:对任何目标其IOU<0.1。(误把背景当物体)
Yolo与Fast R-CNN的误差对比分析如下图所示:
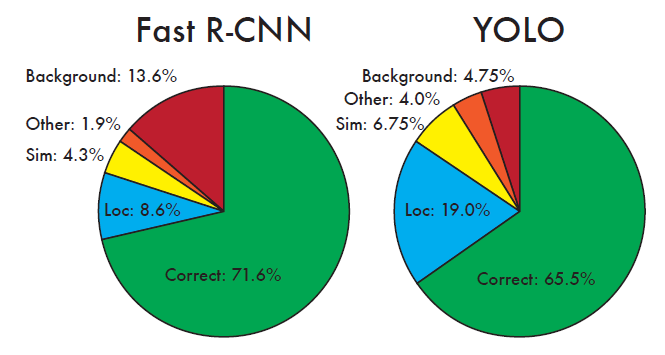 图13 Yolo与Fast R-CNN的误差对比分析
图13 Yolo与Fast R-CNN的误差对比分析
可以看到,Yolo的Correct的是低于Fast R-CNN。另外Yolo的Localization误差偏高,即定位不是很准确。但是Yolo的Background误差很低,说明其对背景的误判率较低。Yolo的那篇文章中还有更多性能对比,感兴趣可以看看。
现在来总结一下Yolo的优缺点。首先是优点,Yolo采用一个CNN网络来实现检测,是单管道策略,其训练与预测都是end-to-end,所以Yolo算法比较简洁且速度快。第二点由于Yolo是对整张图片做卷积,所以其在检测目标有更大的视野,它不容易对背景误判。其实我觉得全连接层也是对这个有贡献的,因为全连接起到了attention的作用。另外,Yolo的泛化能力强,在做迁移时,模型鲁棒性高。
最后不得不谈一下Yolo的缺点,首先Yolo各个单元格仅仅预测两个边界框,而且属于一个类别。对于小物体,Yolo的表现会不如人意。这方面的改进可以看SSD,其采用多尺度单元格。也可以看Faster R-CNN,其采用了anchor boxes。Yolo对于在物体的宽高比方面泛化率低,就是无法定位不寻常比例的物体。当然Yolo的定位不准确也是很大的问题。
链接:https://www.jianshu.com/p/a1e618795b29
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。