在做深度学习实验或项目时,为了得到最优的模型结果,中间往往需要很多次的尝试和修改。而合理的文件组织结构,以及一些小技巧可以极大地提高代码的易读易用性。根据我的个人经验,在从事大多数深度学习研究时,程序都需要实现以下几个功能:
- 模型定义
- 数据处理和加载
- 训练模型(Train&Validate)
- 训练过程的可视化
- 测试(Test/Inference)
另外程序还应该满足以下几个要求:
- 模型需具有高度可配置性,便于修改参数、修改模型,反复实验
- 代码应具有良好的组织结构,使人一目了然
- 代码应具有良好的说明,使其他人能够理解
文件组织架构
前面提到过,程序主要包含以下功能:
- 模型定义
- 数据加载
- 训练和测试
首先来看程序文件的组织结构:
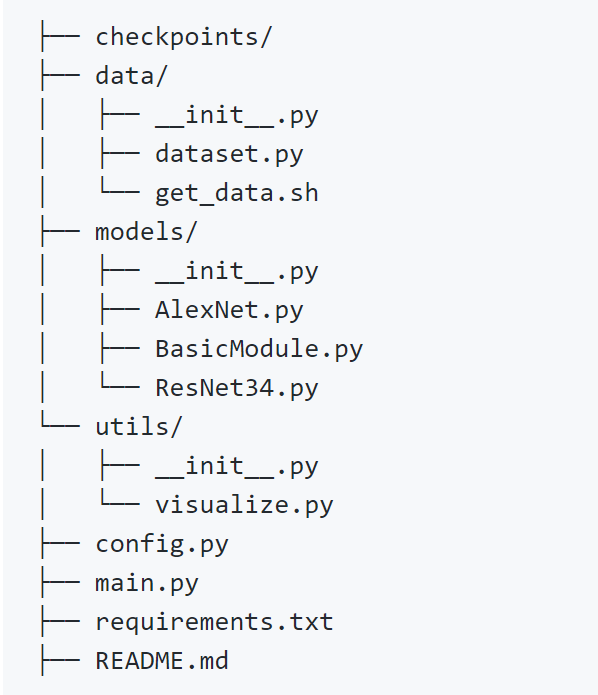
其中:
checkpoints/: 用于保存训练好的模型,可使程序在异常退出后仍能重新载入模型,恢复训练data/:数据相关操作,包括数据预处理、dataset实现等models/:模型定义,可以有多个模型,例如上面的AlexNet和ResNet34,一个模型对应一个文件utils/:可能用到的工具函数,在本次实验中主要是封装了可视化工具config.py:配置文件,所有可配置的变量都集中在此,并提供默认值main.py:主文件,训练和测试程序的入口,可通过不同的命令来指定不同的操作和参数requirements.txt:程序依赖的第三方库README.md:提供程序的必要说明
可以看到,几乎每个文件夹下都有__init__.py,一个目录如果包含了__init__.py 文件,那么它就变成了一个包(package)。__init__.py可以为空,也可以定义包的属性和方法,但其必须存在,其它程序才能从这个目录中导入相应的模块或函数。例如在data/文件夹下有__init__.py,则在main.py 中就可以from data.dataset import DogCat。而如果在__init__.py中写入from .dataset import DogCat,则在main.py中就可以直接写为:from data import DogCat,或者import data; dataset = data.DogCat,相比于from data.dataset import DogCat更加便捷。
数据加载
数据的相关处理主要保存在data/dataset.py中。关于数据加载的相关操作,在上一章中我们已经提到过,其基本原理就是使用Dataset提供数据集的封装,再使用Dataloader实现数据并行加载。Kaggle提供的数据包括训练集和测试集,而我们在实际使用中,还需专门从训练集中取出一部分作为验证集。对于这三类数据集,其相应操作也不太一样,而如果专门写三个Dataset,则稍显复杂和冗余,因此这里通过加一些判断来区分。对于训练集,我们希望做一些数据增强处理,如随机裁剪、随机翻转、加噪声等,而验证集和测试集则不需要。
关于数据集使用的注意事项,在上一章中已经提到,将文件读取等费时操作放在__getitem__函数中,利用多进程加速。避免一次性将所有图片都读进内存,不仅费时也会占用较大内存,而且不易进行数据增强等操作。另外在这里,我们将训练集中的30%作为验证集,可用来检查模型的训练效果,避免过拟合。在使用时,我们可通过dataloader加载数据。
模型定义
模型的定义主要保存在models/目录下,其中BasicModule是对nn.Module的简易封装,提供快速加载和保存模型的接口。
工具函数
在项目中,我们可能会用到一些helper方法,这些方法可以统一放在utils/文件夹下,需要使用时再引入。在本例中主要是封装了可视化工具visdom的一些操作,其代码如下,在本次实验中只会用到plot方法,用来统计损失信息
配置文件
在模型定义、数据处理和训练等过程都有很多变量,这些变量应提供默认值,并统一放置在配置文件中,这样在后期调试、修改代码或迁移程序时会比较方便,在这里我们将所有可配置项放在config.py中。
class DefaultConfig(object): env = 'default' # visdom 环境 model = 'AlexNet' # 使用的模型,名字必须与models/__init__.py中的名字一致 train_data_root = './data/train/' # 训练集存放路径 test_data_root = './data/test1' # 测试集存放路径 load_model_path = 'checkpoints/model.pth' # 加载预训练的模型的路径,为None代表不加载 batch_size = 128 # batch size use_gpu = True # use GPU or not num_workers = 4 # how many workers for loading data print_freq = 20 # print info every N batch debug_file = '/tmp/debug' # if os.path.exists(debug_file): enter ipdb result_file = 'result.csv' max_epoch = 10 lr = 0.1 # initial learning rate lr_decay = 0.95 # when val_loss increase, lr = lr*lr_decay weight_decay = 1e-4 # 损失函数
可配置的参数主要包括:
- 数据集参数(文件路径、batch_size等)
- 训练参数(学习率、训练epoch等)
- 模型参数
这样我们在程序中就可以这样使用:
import models from config import DefaultConfig opt = DefaultConfig() lr = opt.lr model = getattr(models, opt.model) dataset = DogCat(opt.train_data_root)
def parse(self, kwargs): """ 根据字典kwargs 更新 config参数 """ # 更新配置参数 for k, v in kwargs.items(): if not hasattr(self, k): # 警告还是报错,取决于你个人的喜好 warnings.warn("Warning: opt has not attribut %s" %k) setattr(self, k, v) # 打印配置信息 print('user config:') for k, v in self.__class__.__dict__.items(): if not k.startswith('__'): print(k, getattr(self, k))
main.py
在讲解主程序main.py之前,我们先来看看2017年3月谷歌开源的一个命令行工具fire^3 ,通过pip install fire即可安装。下面来看看fire的基础用法,假设example.py文件内容如下:
import fire def add(x, y): return x + y def mul(**kwargs): a = kwargs['a'] b = kwargs['b'] return a * b if __name__ == '__main__': fire.Fire()
那么我们可以使用:
python example.py add 1 2 # 执行add(1, 2) python example.py mul --a=1 --b=2 # 执行mul(a=1, b=2), kwargs={'a':1, 'b':2} python example.py add --x=1 --y==2 # 执行add(x=1, y=2)
可见,只要在程序中运行fire.Fire(),即可使用命令行参数python file <function> [args,] {--kwargs,}。fire还支持更多的高级功能,具体请参考官方指南^4 。
在主程序main.py中,主要包含四个函数,其中三个需要命令行执行,main.py的代码组织结构如下:
def train(**kwargs): """ 训练 """ pass def val(model, dataloader): """ 计算模型在验证集上的准确率等信息,用以辅助训练 """ pass def test(**kwargs): """ 测试(inference) """ pass def help(): """ 打印帮助的信息 """ print('help') if __name__=='__main__': import fire fire.Fire()
根据fire的使用方法,可通过python main.py <function> --args=xx的方式来执行训练或者测试。
训练
训练的主要步骤如下:
- 定义网络
- 定义数据
- 定义损失函数和优化器
- 计算重要指标
- 开始训练
- 训练网络
- 可视化各种指标
- 计算在验证集上的指标
这里用到了PyTorchNet^5里面的一个工具: meter。meter提供了一些轻量级的工具,用于帮助用户快速统计训练过程中的一些指标。AverageValueMeter能够计算所有数的平均值和标准差,这里用来统计一个epoch中损失的平均值。confusionmeter用来统计分类问题中的分类情况,是一个比准确率更详细的统计指标。例如对于表格6-1,共有50张狗的图片,其中有35张被正确分类成了狗,还有15张被误判成猫;共有100张猫的图片,其中有91张被正确判为了猫,剩下9张被误判成狗。相比于准确率等统计信息,混淆矩阵更能体现分类的结果,尤其是在样本比例不均衡的情况下。
验证相对来说比较简单,但要注意需将模型置于验证模式(model.eval()),验证完成后还需要将其置回为训练模式(model.train()),这两句代码会影响BatchNorm和Dropout等层的运行模式。验证模型准确率的代码如下。
测试
测试时,需要计算每个样本属于狗的概率,并将结果保存成csv文件。测试的代码与验证比较相似,但需要自己加载模型和数据。
帮助函数
为了方便他人使用, 程序中还应当提供一个帮助函数,用于说明函数是如何使用。程序的命令行接口中有众多参数,如果手动用字符串表示不仅复杂,而且后期修改config文件时,还需要修改对应的帮助信息,十分不便。这里使用了Python标准库中的inspect方法,可以自动获取config的源代码。help的代码如下:
def help(): """ 打印帮助的信息: python file.py help """ print(""" usage : python {0} <function> [--args=value,] <function> := train | test | help example: python {0} train --env='env0701' --lr=0.01 python {0} test --dataset='path/to/dataset/root/' python {0} help avaiable args:""".format(__file__)) from inspect import getsource source = (getsource(opt.__class__)) print(source)
当用户执行python main.py help的时候,会打印如下帮助信息:
usage : python main.py <function> [--args=value,] <function> := train | test | help example: python main.py train --env='env0701' --lr=0.01 python main.py test --dataset='path/to/dataset/' python main.py help avaiable args: class DefaultConfig(object): env = 'default' # visdom 环境 model = 'AlexNet' # 使用的模型 train_data_root = './data/train/' # 训练集存放路径 test_data_root = './data/test1' # 测试集存放路径 load_model_path = 'checkpoints/model.pth' # 加载预训练的模型 batch_size = 128 # batch size use_gpu = True # user GPU or not num_workers = 4 # how many workers for loading data print_freq = 20 # print info every N batch debug_file = '/tmp/debug' result_file = 'result.csv' # 结果文件 max_epoch = 10 lr = 0.1 # initial learning rate lr_decay = 0.95 # when val_loss increase, lr = lr*lr_decay weight_decay = 1e-4 # 损失函数
使用:
正如help函数的打印信息所述,可以通过命令行参数指定变量名.下面是三个使用例子,fire会将包含-的命令行参数自动转层下划线_,也会将非数值的值转成字符串。所以--train-data-root=data/train和--train_data_root='data/train'是等价的
# 训练模型 python main.py train --train-data-root=data/train/ --lr=0.005 --batch-size=32 --model='ResNet34' --max-epoch = 20 # 测试模型 python main.py test --test-data-root=data/test1 --load-model-path='checkpoints/resnet34_00:23:05.pth' --batch-size=128 --model='ResNet34' --num-workers=12 # 打印帮助信息 python main.py help