本次配置单节点的Flume NG
1、下载flume安装包
下载地址:(http://flume.apache.org/download.html)

apache-flume-1.6.0-bin.tar.gz安装包上传解压到集群上的/usr/hadoop/目录下。
[hadoop@centpy hadoop]$ pwd usr/hadoop [hadoop@centpy hadoop]$ ls hadoop-2.6.0 zookeeper-3.4.6 hbase-0.98.19 jdk1.8.0_60 [hadoop@centpy hadoop]$ rz [hadoop@centpy hadoop]$ ls apache-flume-1.8.0-bin.tar.gz jdk1.8.0_60 hbase-0.98.19 zookeeper-3.4.6 hadoop-2.6.0 [hadoop@centpy hadoop]$ tar -zxf apache-flume-1.8.0-bin.tar.gz [hadoop@centpy hadoop]$ ls apache-flume-1.8.0-bin hadoop-2.6.0 apache-flume-1.8.0-bin.tar.gz jdk1.8.0_60hbase-0.98.19 zookeeper-3.4.6 [hadoop@centpy hadoop]$ rm -f apache-flume-1.8.0-bin.tar.gz [hadoop@centpy hadoop]$ mv apache-flume-1.8.0-bin/ flume-1.8.0 [hadoop@centpy hadoop]$ ls jdk1.8.0_60 flume-1.8.0 hbase-0.98.19 zookeeper-3.4.6 hadoop-2.6.0
2、配置flume
[hadoop@centpy hadoop]$ cd flume-1.8.0/conf/ [hadoop@centpy conf]$ ls flume-conf.properties.template flume-env.ps1.template flume-env.sh.template log4j.properties [hadoop@centpy conf]$ cp flume-conf.properties.template flume-conf.properties //需要通过flume-conf.properties.template复制一个flume-conf.properties配置文件 [hadoop@centpy conf]$ ls flume-conf.properties flume-conf.properties.template flume-env.ps1.template flume-env.sh.template log4j.properties [hadoop@centpy conf]$ vi flume-conf.properties
#Define sources, channels, sinks agent1.sources = spool-source1 agent1.channels = ch1 agent1.sinks = hdfs-sink1 #Define and configure an Spool directory source agent1.sources.spool-source1.channels = ch1 agent1.sources.spool-source1.type = spooldir agent1.sources.spool-source1.spoolDir = /home/hadoop/test agent1.sources.spool-source1.ignorePattern = event(_d{4}-d{2}-d{2}_d{2}_d{2})?.log(.COMPLETED)? agent1.sources.spool-source1.deserializer.maxLineLength = 10240 #Configure channels agent1.sources.ch1.type = file agent1.sources.ch1.checkpointDir = /home/hadoop/app/flume/checkpointDir agent1.sources.ch1.dataDirs = /home/hadoop/app/flume/dataDirs #Define and configure a hdfs sink agent1.sinks.hdfs-sink1.channels = ch1 agent1.sinks.hdfs-sink1.type = hdfs agent1.sinks.hdfs-sink1.hdfs.path = hdfs://centpy:9000/flume/%Y%m%d agent1.sinks.hdfs-sink1.hdfs.useLocalTimeStamp = true agent1.sinks.hdfs-sink1.hdfs.rollInterval = 30 agent1.sinks.hdfs-sink1.hdfs.rollSize = 67108864 agent1.sinks.hdfs-sink1.hdfs.rollCount = 0 #agent1.sinks.hdfs-sink1.hdfs.codeC = snappy
修改集群上的flume-conf.properties配置文件,这里收集日志文件到收集端。配置参数的详细说明可以参考官方文档(https://cwiki.apache.org/confluence/display/FLUME/Getting+Started)。
3、启动并测试Flume
1)首先启动Hadoop集群
[hadoop@centpy hadoop]$ cd hadoop-2.6.0 [hadoop@centpy hadoop-2.6.0]$ sbin/start-all.sh This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh Starting namenodes on [centpy] centpy: starting namenode, logging to /usr/hadoop/hadoop-2.6.0/logs/hadoop-hadoop-namenode-centpy.out centpy: starting datanode, logging to /usr/hadoop/hadoop-2.6.0/logs/hadoop-hadoop-datanode-centpy.out Starting secondary namenodes [0.0.0.0] 0.0.0.0: starting secondarynamenode, logging to /usr/hadoop/hadoop-2.6.0/logs/hadoop-hadoop-secondarynamenode-centpy.out starting yarn daemons starting resourcemanager, logging to /usr/hadoop/hadoop-2.6.0/logs/yarn-hadoop-resourcemanager-centpy.out centpy: starting nodemanager, logging to /usr/hadoop/hadoop-2.6.0/logs/yarn-hadoop-nodemanager-centpy.out [hadoop@centpy hadoop-2.6.0]$ jps 2597 ResourceManager 2454 SecondaryNameNode 2167 NameNode 2698 NodeManager 2267 DataNode 3006 Jps
2)启动Flume
[hadoop@centpy hadoop-2.6.0]$ cd ../flume/ [hadoop@centpy flume]$ bin/flume-ng agent -n agent1 -f conf/flume-conf.properties
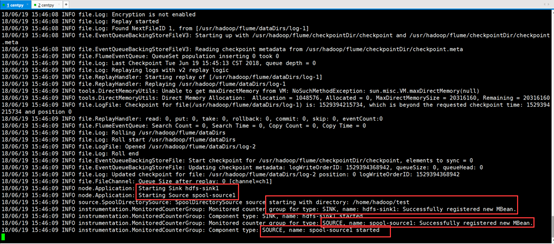
如上图,我们已经成功启动Flume。
3)测试Flume
先上传一个测试文件到我们配置的测试目录中(/home/hadoop/test)
[hadoop@centpy conf]$ cd /home/hadoop/test/ [hadoop@centpy test]$ ls [hadoop@centpy test]$ rz [hadoop@centpy test]$ ls template.log
此时Flume会收集日志信息如下:
8/06/19 15:55:15 INFO hdfs.BucketWriter: Creating hdfs://centpy:9000/flume/20180619/FlumeData.1529394914599.tmp (此处会先在数据收集过程中先生成一个.tmp文件用于记录,等到30秒过后数据收集完成则会生成最终文件FlumeData.1529394914599) 18/06/19 15:55:38 INFO file.EventQueueBackingStoreFile: Start checkpoint for /usr/hadoop/flume/checkpointDir/checkpoint, elements to sync = 200 18/06/19 15:55:38 INFO file.EventQueueBackingStoreFile: Updating checkpoint metadata: logWriteOrderID: 1529394369347, queueSize: 0, queueHead: 198 18/06/19 15:55:38 INFO file.Log: Updated checkpoint for file: /usr/hadoop/flume/dataDirs/log-2 position: 24645 logWriteOrderID: 1529394369347 18/06/19 15:55:47 INFO hdfs.BucketWriter: Closing hdfs://centpy:9000/flume/20180619/FlumeData.1529394914599.tmp 18/06/19 15:55:47 INFO hdfs.BucketWriter: Renaming hdfs://centpy:9000/flume/20180619/FlumeData.1529394914599.tmp to hdfs://centpy:9000/flume/20180619/FlumeData.1529394914599 18/06/19 15:55:47 INFO hdfs.HDFSEventSink: Writer callback called.
我们也可以在Web浏览器查看文件信息

4、Flume 案例分析
下面我们看一下flume的实际应用场景,其示例图如下所示。
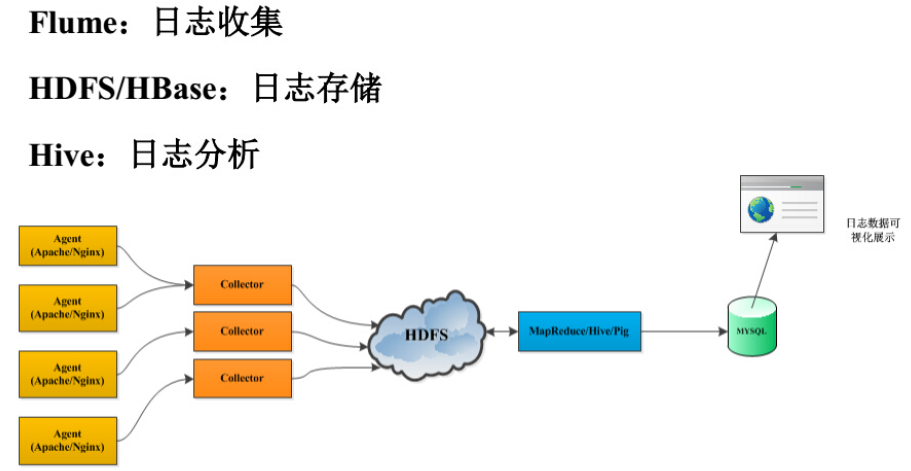
在上面的应用场景中,主要可以分为以下几个步骤。
1、首先采用flume进行日志收集。
2、采用HDFS进行日志的存储。
3、采用MapReduce/Hive进行日志分析。
4、将分析后的格式化日志存储到Mysql数据库中。
5、最后前端查询,实现数据可视化展示。
flume的实际应用场景,相信大家有了一个初步的认识,大家可以根据复杂的业务需求,实现flume来收集数据。这里就不一一讲述,希望大家在以后的学习过程中,学会学习、学会解决实际的问题。
以上就是博主为大家介绍的这一板块的主要内容,这都是博主自己的学习过程,希望能给大家带来一定的指导作用,有用的还望大家点个支持,如果对你没用也望包涵,有错误烦请指出。如有期待可关注博主以第一时间获取更新哦,谢谢!