废话不多说,直接上笔记,先来看下参考链接GitHub: https://github.com/alibaba/DataX。此链接有较详细的安装使用方法,还有json参数编写的文档说明,建议多看。
First,从上面的参考链接中下载datax,解压完成后datax/bin目录中就有了现成的可执行文件。但是还不能直接用,因为运行依赖于其他软件,所以下面来看看运行要求和安装步骤:
datax运行环境要求
Linux
JDK(1.8以上,推荐1.8)
Python(推荐Python2.6.X)
Apache Maven 3.x (Compile DataX)
所以第一步我们先要安装上面这些软件。
安装步骤
安装JDK
参考链接:https://www.cnblogs.com/xuliangxing/p/7066913.html
1、从官网下载系统对应JDK安装包。
过期示例:wget http://download.oracle.com/otn-pub/java/jdk/8u171-b11/512cd62ec5174c3487ac17c61aaa89e8/jdk-8u171-linux-x64.tar.gz (下载前可能会提示你让你Accept License Agreement,点击同意就好)
截至2020/3/4,官网已经改成“要求登陆”后才能下载,不过新增了RPM资源包,如果选择rpm包,下载完成后直接执行如下命令即可进行安装(跳过2、3、4步骤)
rpm -iv jdk-8u241-linux-x64.rpm
2、解压
tar -zxvf jdk-8u171-linux-x64.tar.gz (免编译安装)
3、修改环境变量
vim /etc/profile
用vim编辑器来编辑profile文件,在文件末尾添加以下内容:
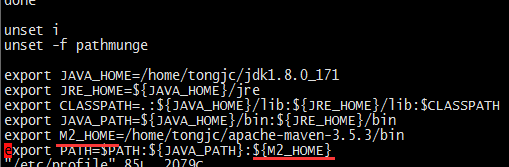
export JAVA_HOME=${你的解压路径}/jdk1.8.0_171
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib:$CLASSPATH
export JAVA_PATH=${JAVA_HOME}/bin:${JRE_HOME}/bin
export PATH=$PATH:${JAVA_PATH} ###(与windows类似多个系统变量需要用符号分隔;只不过这里用":", 而win用";")
保存退出。
4、重新执行修改后的配置,使配置生效
source /etc/profile
5、测试安装结果
java -version
javac
以上两个命令都能正确输出提示才是成功安装。
安装Python
我的机器上已经自带了Python2.6.6,而且很多的unix机器也都带有Python,此处略过。如果没有的或版本不够的请自行安装升级。
安装Apache Maven 3.x
1、从官网下载系统对应压缩包(注意:Binary tar包适用于unix系统;Source tar包适用于windows系统)
2、安装 - 官方参考文档
官网下载的包也是免编译安装的,只要配置环境变量就行。这里我只翻译unix系统下的设置方法,window类似。
-------------------------------------------------------------------------------------------------------------------------------------------
Unix-based Operating System (Linux, Solaris and Mac OS X) Tips
- Check environment variable value
echo $JAVA_HOME /Library/Java/JavaVirtualMachines/jdk1.8.0_45.jdk/Contents/Home
- Adding to PATH
export PATH=/opt/apache-maven-3.5.3/bin:$PATH
----------------------------------------------------------------------------------------------------------------------------------------------
第一步检查环境。没啥用,因为咱们在前面的步骤已经安装过jdk了。
第二步将apache-maven的执行文件路径加入到系统环境变量中,以便全局调用。操作方法参考安装jdk的第四、五步
最后附上我的配置
以上是个人总结的安装步骤, 下面进入datax的使用介绍。
datax的使用方法简单
python {用户目录}/datax/bin/datax.py ./stream2stream.json
即可。
难的是如何配置json文件。在https://github.com/alibaba/DataX网页中“Support Data Channels”板块有各个数据库的读、写的json参数编写说明,请多加阅读,只有多各个参数的解释有了一定理解才能配制出符合业务场景的json。
json主要有两个配置参数:content.reader和content.writer,这两个的配置决定了读、写数据库的所有配置,余下的属于连接设置。文档中参数说明理解起来稍微有点费劲,在编写json过程中需要注意几点,我以截图划重点方式展示:

下面附上我的测试配置和建表DDL
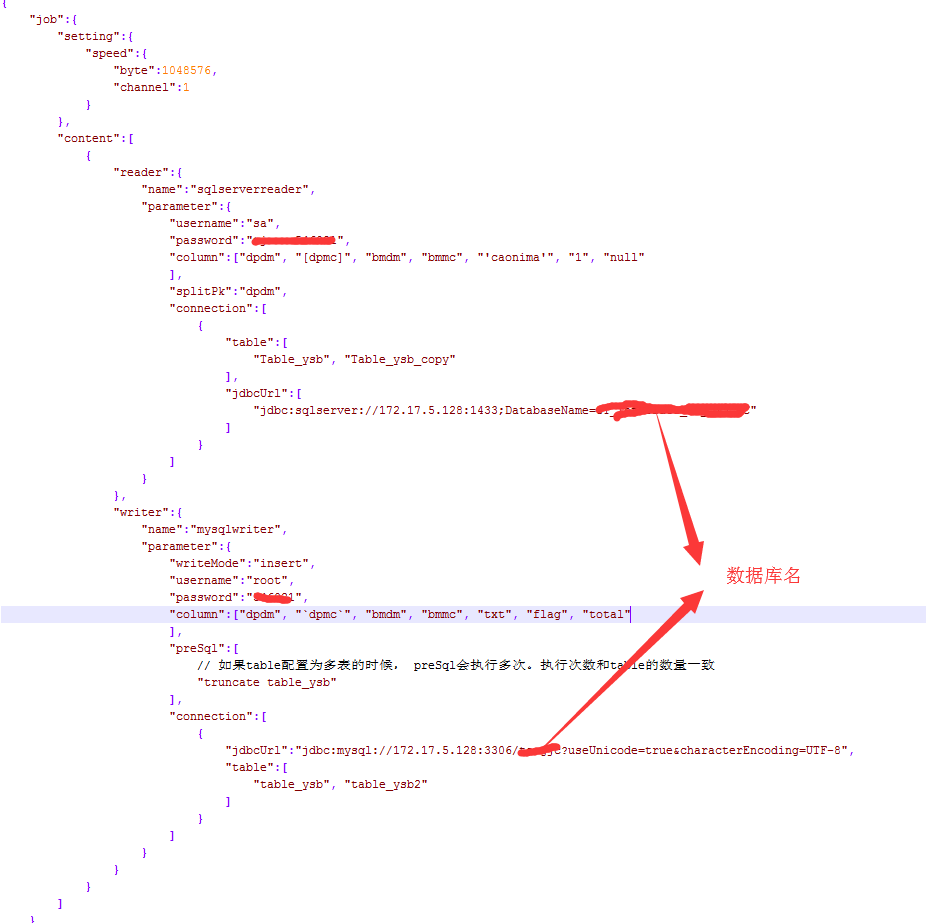
SQL server 测试表:
CREATE TABLE [dbo].[Table_ysb] (
[dpdm] nvarchar(50) COLLATE Chinese_PRC_CI_AS NOT NULL ,
[dpmc] nvarchar(50) COLLATE Chinese_PRC_CI_AS NOT NULL ,
[bmdm] nvarchar(50) COLLATE Chinese_PRC_CI_AS NOT NULL ,
[bmmc] nvarchar(50) COLLATE Chinese_PRC_CI_AS NOT NULL
)
ON [PRIMARY]
Mysql 测试表:
CREATE TABLE `table_ysb` (
`dpdm` varchar(50) NOT NULL,
`dpmc` varchar(50) NOT NULL,
`bmdm` varchar(50) NOT NULL,
`bmmc` varchar(50) NOT NULL,
`txt` varchar(255) DEFAULT NULL,
`flag` tinyint(1) DEFAULT '0',
`total` int(11) DEFAULT '0'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
Table_ysb 和Table_ysb_copy表结构一致,table_ysb和table_ysb2表结构一致。
PS: 注意,writer的connection.jdbcUrl只能配置一个,而reader允许多个,且必须[]起来。