AB Test 介绍:
AB Test 的意义:
数据分析告诉我们要不要去做一件事情,ab 实验反馈告诉我们我们做得好不好,哪里有问题,以及衡量可以带来多少确定性的增长。
一、理论基础
1、中心极限定理:
大量相互独立的随机变量,其均值(或者和)的分布以正态分布为极限(意思就是当满足某些条件的时候,比如Sample Size比较大,采样次数区域无穷大的时候,就越接近正态分布)。而这个定理amazing的地方在于,无论是什么分布的随机变量,都满足这个定理。
2、大数定理
简单的可以描述为,如果有一个随机变量X,你不断的观察并且采样这个随机变量,得到了n个采样值,然后求得这n个采样值得平均值,当n趋向于正无穷的时候,这个平均值就收敛于这个随机变量X的期望。
3、置信区间和统计显著性
参考:
https://zhuanlan.zhihu.com/p/22987913
概念:样本、总体
置信区间是(用来对一个概率样本的总体参数进行区间估计的) 样本均值范围,它展现了这个均值范围包含总体参数的概率,这个概率称为置信水平;
置信水平代表了估计的可靠度,一般而言,我们采用95% 的置信水平进行区间估计。
置信区间在ABtest中的意义:(两个总体的均值之差的置信区间)
由t检验大样本检验公式计算得出Z值(由均值、样本量、方差计算出来的统计值,通过这个统计值再结合分布公式,也可以计算出p value从而作出是否拒绝原假设的决策),再根据两个总体的均值、标准差和样
本大小,利用以下公式即可求出两个总体均值差的95%置信区间:
本大小,利用以下公式即可求出两个总体均值差的95%置信区间:
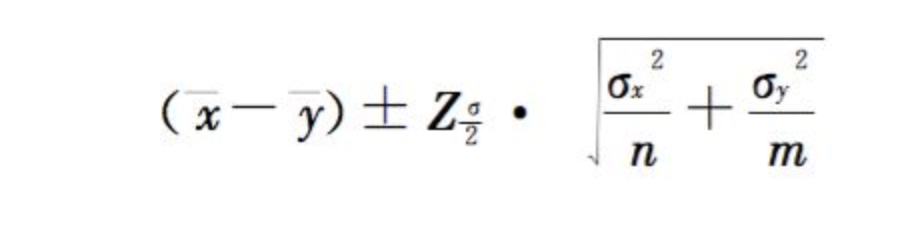
值得注意的是,置信区间的上下限同为正或负,只能说明试验是统计显著的(也就是试验版本和对照版本有差异),但是这个差异有可能是非常小的,在实际应用中微不足道的。因此,只有兼备统计显著和效果显著两个特征的结果,才能说明该版本是可用,值得发布的。
二、AB testing的实验注意点
1、时间一致性;
2、数据分布的一致性;
3、统计显著的结果才可以引导决策;
4、实验分组设计上(流量分布要均匀):
算法对用户的偏差没有反映到实验分桶上,会放大算法之间效果的差距,从而产生辛普森悖论;
5、置信
要获得一个可信的试验结果需要一定的流量(样本)和时间,如果流量(样本)太小或者分不均匀,试验结果会存在偶然性,可能无法得出可信的结果;试验运行时间太短的话同理;
6、时间
实验周期中也要避免外部因素的影响,尽量在平稳时期进行,减少外部因素的干扰;
有时候为了保证实验效果的置信,防止小流量分布不均匀,可以在试验过程中,逐步增大流量分配,同时监控关键指标的数据走势,从而得到置信的结论;
三、分流及分桶原理
需要保证:
(1)同一实验中不同分桶之间是随机的;
(2)不同的场景、实验,分桶会被重新打散;
(3)实验设计时,需要考虑验证哪个因子,则可以按照那个因子来进行分桶;
分桶和分流之间的关系:
分流是指,从总体中随机抽样百分之几来做实验;
分桶是指,在实验的流量里面根据某个需要验证的因子随机分桶;
四、分桶不平衡的验证办法
1、AA testing
A/A测试可以理解成对两个相同版本进行的A/B测试。通常,这样做的目的是为了验证正在使用的工具运行试验在统计上是公平的。在A/A测试中,如果测试正确进行,控制组和实验组应该没有任何区别。
如果说A/B测试用来测试比较几个方案的优劣,那么A/A测试就是验证A/B测试及工具置信度的有效方式。
应该考虑运行A/A测试的唯一种情况:
(1)你刚安装了一个新的测试工具或更改了测试工具设置;
(2)你发现了A/B测试与数据分析工具结果之间存在差异;
一般在AB测试之前进行AA测试,或者在ab测试中同时进行A/A/B测试,观察两个相同的A组之间是否有统计显著的不同,从而确定分桶规则是否靠谱。一些分析表明,这种方式还不如直接让控制桶(a桶)是实验桶(b桶)的两倍大(所谓的 池化)
2、多项检验的统计方法;
五、分桶不平衡的解决办法
1、由AA实验演变的A:B=2:1的流量大小分配方式;
2、通过逐步放大流量做对比的方式;
六、AB test的应用
1、方案优选;
2、系统测试;
3、因果推断;
AB test和离线评估的优缺点和使用场景:
1、AB test 系统搭建和维护需要一定成本,对技术也有一定要求,如果该系统做得不好,用了反而有害;ab系统更多是用于方便衡量算法/产品优化带来的效果,对于用人紧缺的创业公司其实不是必要的;
2、离线评估最重要是模拟真实线上场景,如果模拟不好,离线测试的结果也不可信;
但是,当公司的ab test系统还没有搭建好的时候,离线评估还是很有必要,起码有一些明显的算法问题可以通过离线测试看出来,模型选择和调优也需要离线测试,而且离线测试不会对线上造成影响,ab实验则会;
3、当产品在市场上的竞争环境激烈,项目上线需要争取有利时机时,往往凭借战略决策来决定上线与否而不是ab实验,ab实验有一段观察期而且需要外部条件相对稳定才能得出客观的结论,适用于产品的发展期处于相对比较平稳的时候,防止决策错误导致数据下降;
因此,实时数据分析是有必要的,实时ab test必要性不是很强;
4、多数的ab test系统并不具备决策推全后仍然持续观察的能力,有一些关乎实现公司或者产品长期战略目标的功能/算法,可能短期内会导致指标下降或者没有明显增长,但是也必须要上线;
5、AB test 帮助你在现有流量中获取更多的收益,或者在现有流量中提升ROI,或者说在现有用户基础上提升活跃度,但是在衡量对用户量增长或者获取新流量是否有帮助上,ab test或者所起作用不大。
6、AB test还有一个缺点,就是只能做小范围的效果比较,比如作用于同一个场景使用不同算法的效果比较;比如它不能告诉我们,A业务的推荐算法是否比B业务的推荐算法做得好;也就是说它不能衡量一个模型的迁移和泛化能力;
算法ab test 与数据分析的关联:
1、使用deep模型做算法,ab test衡量算法end-to-end的效果;然后用统计分析方法或者ml的方法做模型解释,或者是建模前的特征分析。
其他:
1、验证达尔文系统流量分配不均的问题解决办法:设置AA testing
2、对照组的设置要和优化baseline一致,实验设计要和我们需要验证的结论相一致才行;
3、模型到底是否需要 fine tuning?(权衡模型调优与新算法尝试之间的选择:看目标到底是要精准还是要召回高?其实是准确率和召回率的平衡。抛开业务需求,一个好的模型,是在准确率和召回率趋向接近的基础上,两者还能达到一个比较高的值;那如果是有业务需求,那么就根据业务需求使用相应特点的模型)
4、在线模型里面到底是抽样训练还是全量样本训练比较好?(训练样本抽样方面的优化)(需要实验验证)
5、特征优化包括特征的全面性完善和特征加工方式的多样性完善;
数据分析->基础特征加工->模型设计->平台工具(特征工程、模型训练及预测)->实验设计及验证->(反馈到前面任意步骤再顺序执行)
附:
具体计算方法及工具:
贾俊平 《统计学》5~8章