python强大之处在于各种功能完善的模块。合理的运用可以省略很多细节的纠缠,提高开发效率。
用python实现一个功能较为完整的爬虫,不过区区几十行代码,但想想如果用底层C实现该是何等的复杂,光一个网页数据的获得就需要字节用原始套接字构建数据包,然后解析数据包获得,关于网页数据的解析,更是得喝一壶。
下面具体分析分析用python如何构建一个爬虫。
0X01 简单的爬虫主要功能模块
URL管理器:管理待抓取URL集合和已抓取URL集合,防止重复抓取、防止循环抓取。主要需要实现:添加新URL到待爬取集合中、判断待添加URL是否在容器中、判断是否还有待爬取URL、获得爬取URL、将URL从带爬取移动到已爬取。URL实现方式可以采用内存set()集合、关系数据库、缓存数据库。一般小型爬虫数据保存内存中已经足够了。
网页下载器:通过URL获得HTML网页数据保存成文本文件或者内存字符串。在python中提供了urlllib2模块、requests模块来实现这个功能。具体的代码实现在下面做详细分析。
网页解析器:通过获取的HTML文档,从中获得新的URL以及关心的数据。如何从HTML文档中获得需要的信息呢? 可以分析信息的结构,然后通过python正则表达式模糊匹配获得,但这种方法再面对复杂的HTML时就有点力不从心。可以通过python自带的html.parser来解析,或者通过第三方模块Beautiful Soup、lxml等来结构化解析。什么是结构化解析? 就是把把网页结构当做一棵树形结构,官方叫DOM(Document Object Model)。
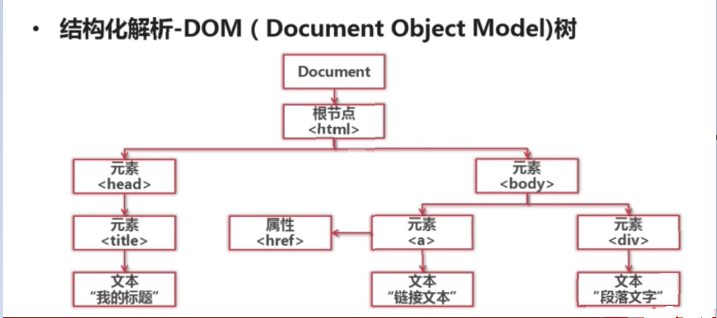
然后通过搜索节点的方式来获得关心的节点数据。
运行流程:调度程序询问URL是否有带爬取的URL,如果有就获得一个,然后送到下载器获得HTML内容,然后再将内容送到解析器进行解析,得到新的URL和关心的数据,然后把新增加的URL放入URL管理器。
0X02 urllib2模块的使用
urllib2的使用有很多种方法。
第一种:
直接通过urlopen的方式获得HTML。
url = "http://www.baidu.com" print 'The First method' response1 = urllib2.urlopen(url) print response1.getcode() print len(response1.read())
第二种:
这个方法是自己构建HTTP请求头,伪装成一个浏览器,可以绕过一些反爬机制,自己构造HTTP请求头更加灵活。
url = "http://www.baidu.com" print 'The Second method' request = urllib2.Request(url) request.add_header("user-agent", "Mozilla/5.0") response2 = urllib2.urlopen(request) print response2.getcode() print len(response2.read())
第三种:
增加cookie处理,可以获得需要登录的页面信息。
url = "http://www.baidu.com" print 'The Third method' cj = cookielib.CookieJar() opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj)) urllib2.install_opener(opener) response3 = urllib2.urlopen(url) print response3.getcode() print cj print len(response3.read())
当然这几种方法的使用都需要导入urllib2,第三种还需要导入cookielib。
0X03 BeautifulSoup的实现
下面简单说说BeautifulSoup的用法。大致也就是三步走:创建BeautifulSoup对象,寻找节点,获得节点内容。
from bs4 import BeautifulSoup import re html_doc = """ <html><head><title>The Dormouse's story</title></head> <body> <p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> """ soup = BeautifulSoup(html_doc, 'html.parser', from_encoding='utf-8') print 'Get all links' links = soup.find_all('a') for link in links: print link.name,link['href'],link.get_text() print 'Get lacie link' link_node = soup.find('a',href='http://example.com/lacie') print link_node.name,link_node['href'],link_node.get_text() print 'match' link_node = soup.find('a', href=re.compile(r'ill')) print link_node.name, link_node['href'], link_node.get_text() print 'p' p_node = soup.find('p', class_="title") print p_node.name, p_node.get_text()
0X04 爬虫的简单实现
在此不再累赘,具体代码已上传到github : github.com/zibility/spider