一 什么是编码?
基本概念很简单。首先,我们从一段信息即消息说起,消息以人类可以理解、易懂的表示存在。我打算将这种表示称为“明文”(plain text)。对于说英语的人,纸张上打印的或屏幕上显示的英文单词都算作明文。
其次,我们需要能将明文表示的消息转成另外某种表示,我们还需要能将编码文本转回成明文。从明文到编码文本的转换称为“编码”,从编码文本又转回成明文则为“解码”。
编码问题是个大问题,如果不彻底解决,它就会像隐藏在丛林中的小蛇,时不时地咬你一口。 那么到底什么是编码呢? //ASCII 记住一句话:计算机中的所有数据,不论是文字、图片、视频、还是音频文件,本质上最终都是按照类似 01010101 的二进制存储的。 再说简单点,计算机只懂二进制数字! 所以,目的明确了:如何将我们能识别的符号唯一的与一组二进制数字对应上?于是美利坚的同志想到通过一个电平的高低状态来代指0或1, 八个电平做为一组就可以表示出 256种不同状态,每种状态就唯一对应一个字符,比如A--->00010001,而英文只有26个字符,算上一些特殊字符和数字,128个状态也够 用了;每个电平称为一个比特为,约定8个比特位构成一个字节,这样计算机就可以用127个不同字节来存储英语的文字了。这就是ASCII编码。 扩展ANSI编码 刚才说了,最开始,一个字节有八位,但是最高位没用上,默认为0;后来为了计算机也可以表示拉丁文,就将最后一位也用上了, 从128到255的字符集对应拉丁文啦。至此,一个字节就用满了! //GB2312 计算机漂洋过海来到中国后,问题来了,计算机不认识中文,当然也没法显示中文;而且一个字节所有状态都被占满了,万恶的帝国主义亡 我之心不死啊!我党也是棒,自力更生,自己重写一张表,直接生猛地将扩展的第八位对应拉丁文全部删掉,规定一个小于127的字符的意 义与原来相同,但两个大于127的字符连在一起时,就表示一个汉字,前面的一个字节(他称之为高字节)从0xA1用到0xF7,后面一个字节 (低字节)从0xA1到0xFE,这样我们就可以组合出大约7000多个简体汉字了;这种汉字方案叫做 “GB2312”。GB2312 是对 ASCII 的中文扩展。 //GBK 和 GB18030编码 但是汉字太多了,GB2312也不够用,于是规定:只要第一个字节是大于127就固定表示这是一个汉字的开始,不管后面跟的是不是扩展字符集里的 内容。结果扩展之后的编码方案被称为 GBK 标准,GBK 包括了 GB2312 的所有内容,同时又增加了近20000个新的汉字(包括繁体字)和符号。 //UNICODE编码: 很多其它国家都搞出自己的编码标准,彼此间却相互不支持。这就带来了很多问题。于是,国际标谁化组织为了统一编码:提出了标准编码准 则:UNICODE 。 UNICODE是用两个字节来表示为一个字符,它总共可以组合出65535不同的字符,这足以覆盖世界上所有符号(包括甲骨文) //utf8: unicode都一统天下了,为什么还要有一个utf8的编码呢? 大家想,对于英文世界的人们来讲,一个字节完全够了,比如要存储A,本来00010001就可以了,现在吃上了unicode的大锅饭, 得用两个字节:00000000 00010001才行,浪费太严重! 基于此,美利坚的科学家们提出了天才的想法:utf8. UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码,它可以使用1~4个字节表示一个符号,根据 不同的符号而变化字节长度,当字符在ASCII码的范围时,就用一个字节表示,所以是兼容ASCII编码的。 这样显著的好处是,虽然在我们内存中的数据都是unicode,但当数据要保存到磁盘或者用于网络传输时,直接使用unicode就远不如utf8省空间啦! 这也是为什么utf8是我们的推荐编码方式。 Unicode与utf8的关系: 一言以蔽之:Unicode是内存编码表示方案(是规范),而UTF是如何保存和传输Unicode的方案(是实现)这也是UTF与Unicode的区别。
补充:utf8是如何节约硬盘和流量的
s="I'm 许二"
你看到的unicode字符集是这样的编码表:
I 0049 ' 0027 m 006d 0020 许 82d1 二 660a
每一个字符对应一个十六进制数字。
计算机只懂二进制,因此,严格按照unicode的方式(UCS-2),应该这样存储:
I 00000000 01001001 ' 00000000 00100111 m 00000000 01101101 00000000 00100000 许 10000010 11010001 二 01100110 00001010
这个字符串总共占用了12个字节,但是对比中英文的二进制码,可以发现,英文前9位都是0!浪费啊,浪费硬盘,浪费流量。怎么办?UTF8:
I 01001001 ' 00100111 m 01101101 00100000 许 11101000 10001011 10010001 二 11100110 10011000 10001010
utf8用了10个字节,对比unicode,少了两个,因为我们的程序英文会远多于中文,所以空间会提高很多!
记住:一切都是为了节省你的硬盘和流量。
二 py2的string编码
在py2中,有两种字符串类型:str类型和unicode类型;注意,这仅仅是两个名字,python定义的两个名字,关键是这两种数据类型在程序运行时存在内存地址的是什么?
我们来看一下:
#coding:utf8 s1='许' print type(s1) # <type 'str'> print repr(s1) #'xe8x8bx91 s2=u'许' print type(s2) # <type 'unicode'> print repr(s2) # u'u82d1'
内置函数repr可以帮我们在这里显示存储内容。原来,str和unicode分别存的是字节数据和unicode数据;那么两种数据之间是什么关心呢?如何转换呢?这里就涉及到编码(encode)和解码(decode)了
s1=u'许' print repr(s1) #u'u82d1' b=s1.encode('utf8') print b print type(b) #<type 'str'> print repr(b) #'xe8x8bx91' s2='许二' u=s2.decode('utf8') print u # 许二 print type(u) # <type 'unicode'> print repr(u) # u'u82d1u660a' #注意 u2=s2.decode('gbk') print u2 #鑻戞槉 print len('许二') #6
无论是utf8还是gbk都只是一种编码规则,一种把unicode数据编码成字节数据的规则,所以utf8编码的字节一定要用utf8的规则解码,否则就会出现乱码或者报错的情况。
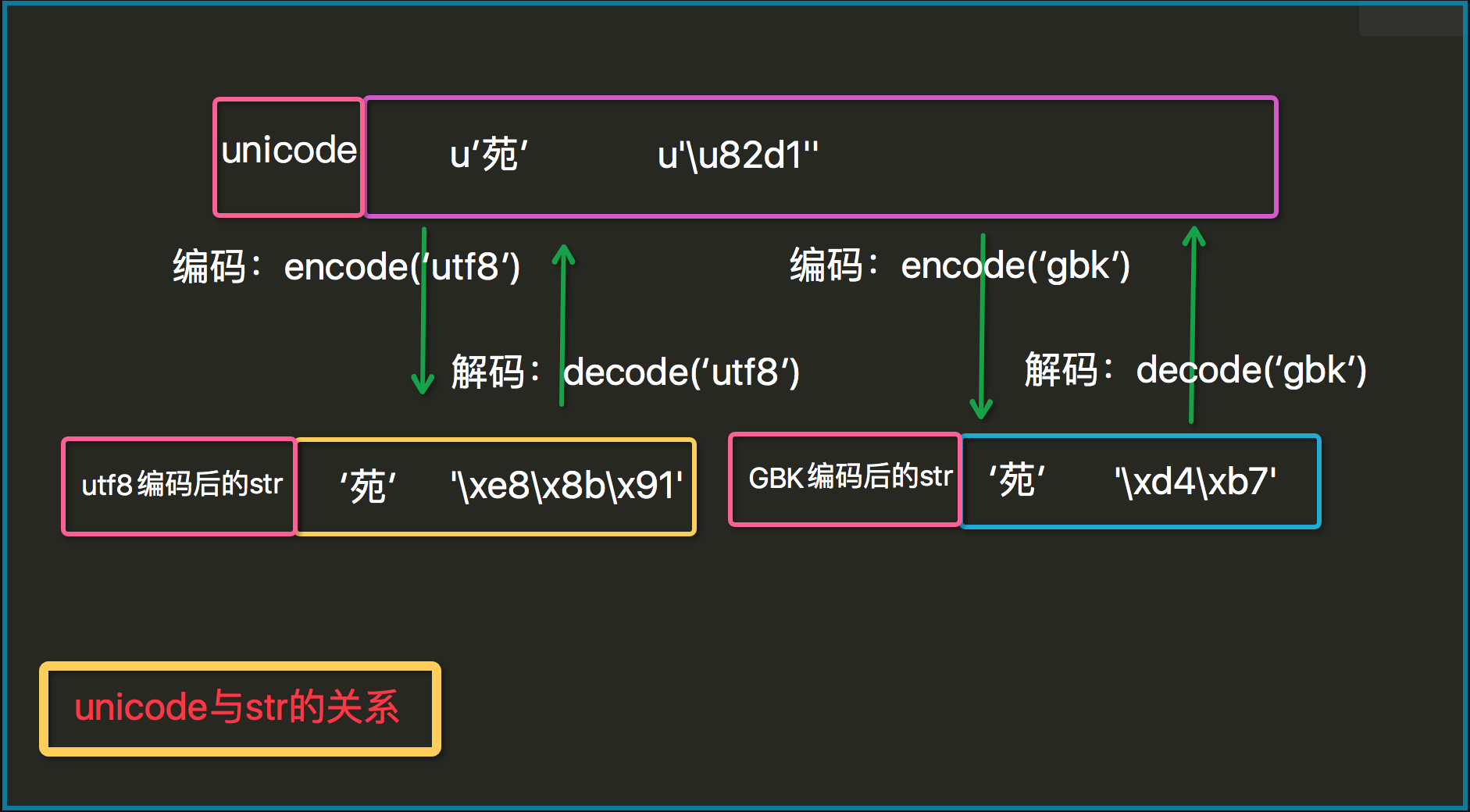
py2编码的特色:
#coding:utf8 print '许二' # 许二 print repr('许二')#'xe8x8bx91xe6x98x8a' print (u"hello"+"yuan") #print (u'许二'+'最帅') #UnicodeDecodeError: 'ascii' codec can't decode byte 0xe6 # in position 0: ordinal not in range(128)
Python 2 悄悄掩盖掉了 byte 到 unicode 的转换,只要数据全部是 ASCII 的话,所有的转换都是正确的,一旦一个非 ASCII 字符偷偷进入你的程序,那么默认的解码将会失效,从而造成 UnicodeDecodeError 的错误。py2编码让程序在处理 ASCII 的时候更加简单。你复出的代价就是在处理非 ASCII 的时候将会失败。
三 py3的string编码
python3 renamed the unicode type to str ,the old str type has been replaced by bytes.
py3也有两种数据类型:str和bytes; str类型存unicode数据,bytse类型存bytes数据,与py2比只是换了一下名字而已。
import json s='许二' print(type(s)) #<class 'str'> print(json.dumps(s)) # "u82d1u660a" b=s.encode('utf8') print(type(b)) # <class 'bytes'> print(b) # b'xe8x8bx91xe6x98x8a' u=b.decode('utf8') print(type(u)) #<class 'str'> print(u) #许二 print(json.dumps(u)) #"u82d1u660a" print(len('许二')) # 2
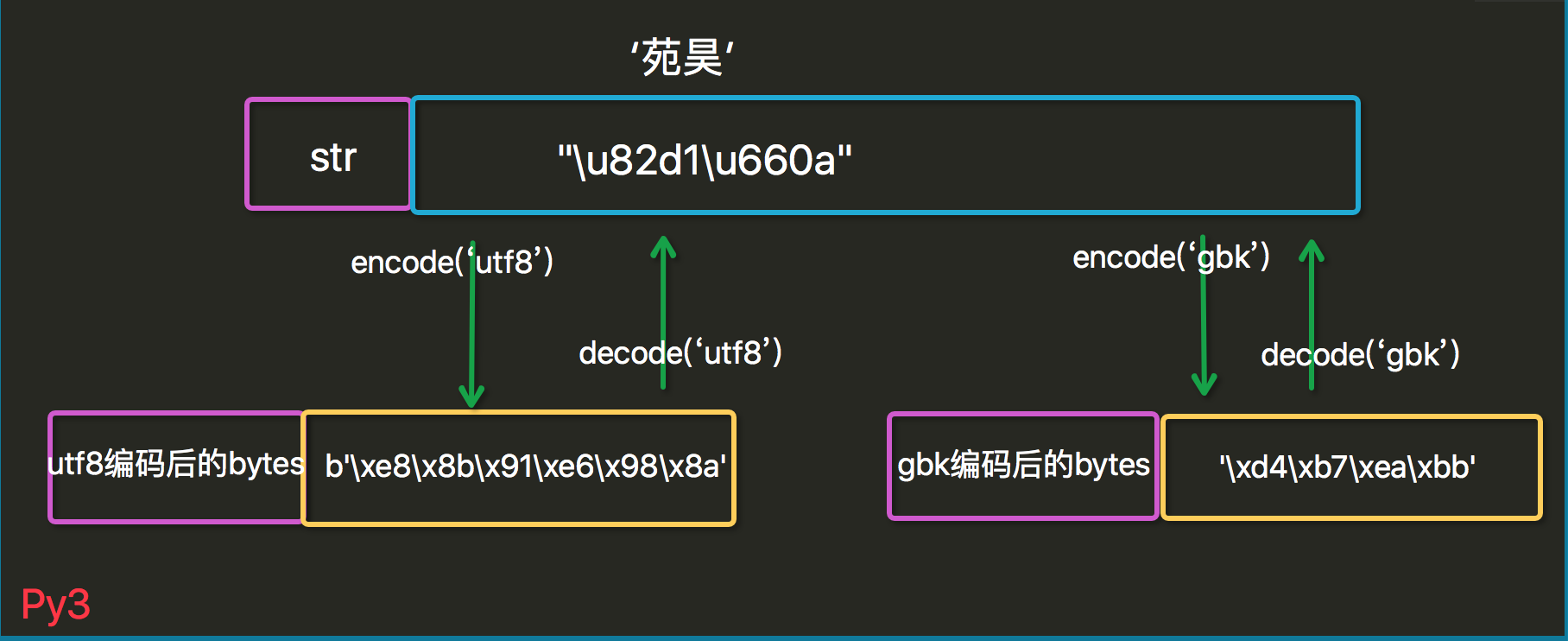
py3的编码哲学:
Python 3最重要的新特性大概要算是对文本和二进制数据作了更为清晰的区分,不再会对bytes字节串进行自动解码。文本总是Unicode,由str类型表示,二进制数据则由bytes类型表示。Python 3不会以任意隐式的方式混用str和bytes,正是这使得两者的区分特别清晰。你不能拼接字符串和字节包,也无法在字节包里搜索字符串(反之亦然),也不能将字符串传入参数为字节包的函数(反之亦然)。
#print('alvin'+u'yuan')#字节串和unicode连接 py2:alvinyuan print(b'alvin'+'yuan')#字节串和unicode连接 py3:报错 can't concat bytes to str
注意:无论py2,还是py3,与明文直接对应的就是unicode数据,打印unicode数据就会显示相应的明文(包括英文和中文)
四 文件从磁盘到内存的编码(******)
说到这,才来到我们的重点!
抛开执行执行程序,请问大家,文本编辑器大家都是用过吧,如果不懂是什么,那么word总用过吧,ok,当我们在word上编辑文字的时候,不管是中文还是英文,计算机都是不认识的,那么在保存之前数据是通过什么形式存在内存的呢?yes,就是unicode数据,为什么要存unicode数据,这是因为它的名字最屌:万国码!解释起来就是无论英文,中文,日文,拉丁文,世界上的任何字符它都有唯一编码对应,所以兼容性是最好的。
好,那当我们保存了存到磁盘上的数据又是什么呢?
答案是通过某种编码方式编码的bytes字节串。比如utf8---一种可变长编码,很好的节省了空间;当然还有历史产物的gbk编码等等。于是,在我们的文本编辑器软件都有默认的保存文件的编码方式,比如utf8,比如gbk。当我们点击保存的时候,这些编辑软件已经"默默地"帮我们做了编码工作。
那当我们再打开这个文件时,软件又默默地给我们做了解码的工作,将数据再解码成unicode,然后就可以呈现明文给用户了!所以,unicode是离用户更近的数据,bytes是离计算机更近的数据。
说了这么多,和我们程序执行有什么关系呢?
先明确一个概念:py解释器本身就是一个软件,一个类似于文本编辑器一样的软件!
现在让我们一起还原一个py文件从创建到执行的编码过程:
打开pycharm,创建hello.py文件,写入
ret=1+1 s='许二' print(s)
当我们保存的的时候,hello.py文件就以pycharm默认的编码方式保存到了磁盘;关闭文件后再打开,pycharm就再以默认的编码方式对该文件打开后读到的内容进行解码,转成unicode到内存我们就看到了我们的明文;
而如果我们点击运行按钮或者在命令行运行该文件时,py解释器这个软件就会被调用,打开文件,然后解码存在磁盘上的bytes数据成unicode数据,这个过程和编辑器是一样的,不同的是解释器会再将这些unicode数据翻译成C代码再转成二进制的数据流,最后通过控制操作系统调用cpu来执行这些二进制数据,整个过程才算结束。
那么问题来了,我们的文本编辑器有自己默认的编码解码方式,我们的解释器有吗?
当然有啦,py2默认ASCII码,py3默认的utf8,可以通过如下方式查询
import sys print(sys.getdefaultencoding())
大家还记得这个声明吗?
#coding:utf8
是的,这就是因为如果py2解释器去执行一个utf8编码的文件,就会以默认地ASCII去解码utf8,一旦程序中有中文,自然就解码错误了,所以我们在文件开头位置声明 #coding:utf8,其实就是告诉解释器,你不要以默认的编码方式去解码这个文件,而是以utf8来解码。而py3的解释器因为默认utf8编码,所以就方便很多了。
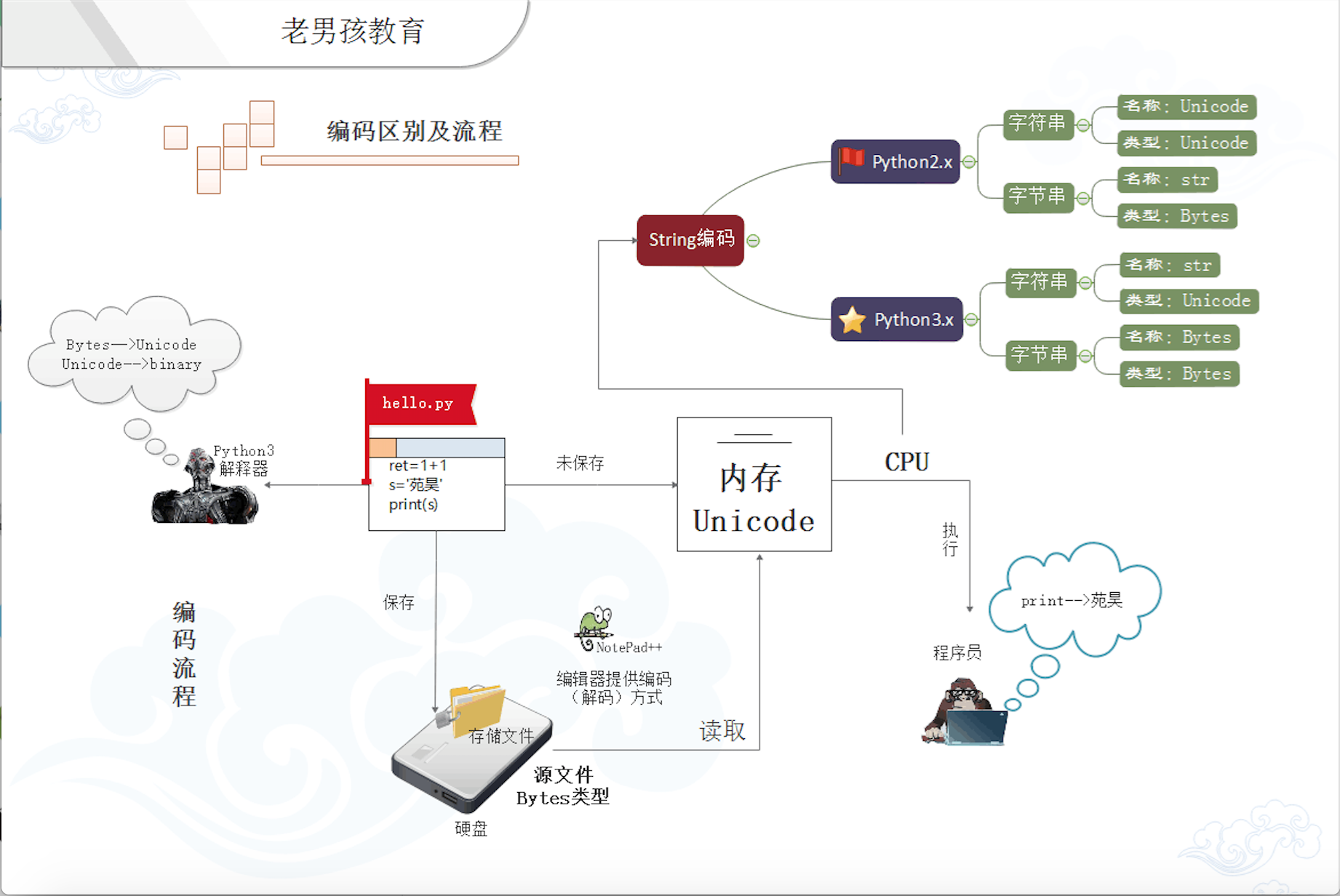
注意:我们上面讲的string编码是在cpu执行程序时的存储状态,是另外一个过程,不要混淆!
五 常见的编码问题
1 cmd下的乱码问题
hello.py
#coding:utf8 print ('许二')
文件保存时的编码也为utf8。
思考:为什么在IDE下用2或3执行都没问题,在cmd.exe下3正确,2乱码呢?
我们在win下的终端即cmd.exe去执行,大家注意,cmd.exe本身也一个软件;当我们python2 hello.py时,python2解释器(默认ASCII编码)去按声明的utf8编码文件,而文件又是utf8保存的,所以没问题;问题出在当我们print'苑昊'时,解释器这边正常执行,也不会报错,只是print的内容会传递给cmd.exe用来显示,而在py2里这个内容就是utf8编码的字节数据,可这个软件默认的编码解码方式是GBK,所以cmd.exe用GBK的解码方式去解码utf8自然会乱码。
py3正确的原因是传递给cmd的是unicode数据,cmd.exe可以识别内容,所以显示没问题。
明白原理了,修改就有很多方式,比如:
print (u'许二')
改成这样后,cmd下用2也不会有问题了。
2 open()中的编码问题
创建一个hello文本,保存成utf8:
许二,你最帅!
同目录下创建一个index.py
f=open('hello') print(f.read())
为什么 在linux下,结果正常:许二,在win下,乱码:鑻戞槉(py3解释器)?
因为你的win的操作系统安装时是默认的gbk编码,而linux操作系统默认的是utf8编码;
当执行open函数时,调用的是操作系统打开文件,操作系统用默认的gbk编码去解码utf8的文件,自然乱码。
解决办法:
f=open('hello',encoding='utf8') print(f.read())
如果你的文件保存的是gbk编码,在win 下就不用指定encoding了。
另外,如果你的win上不需要指定给操作系统encoding='utf8',那就是你安装时就是默认的utf8编码或者已经通过命令修改成了utf8编码。
注意:open这个函数在py2里和py3中是不同的,py3中有了一个encoding=None参数。