最近学习了TensorFlow,发现一个模型叫vgg16,然后搭建环境跑了一下,觉得十分神奇,而且准确率十分的高。又上了一节选修课,关于人工智能,老师让做一个关于人工智能的试验,于是觉得vgg16很不错,可以直接用。
但发现vgg16是训练好的模型,拿来直接用太没水平,于是网上发现说可以用vgg16进行迁移学习。
我理解的迁移学习:
迁移学习符合人们学习的过程,如果要学习一样新东西,我们肯定会运用或是借鉴之前的学习经验,这样能够快速的把握要点,能够快速的学习。迁移学习也是如此。
vgg16模型是前人训练出的能够识别1000种物品的模型,而且识别率很高,它的模型如图:
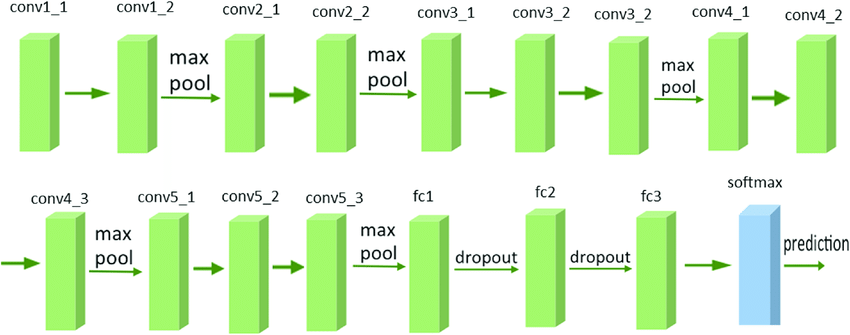
可以数出绿色的模块一共有16层,通过多层的卷积和池化,会提取图片特征值,然后把图片压缩成一个一维数组输入到全连接层中,图中有三层全连接层fc1,fc2,fc3,再经过softmax输出概率分布的预测结果。
进过试验,这个模型能够很好的识别花,但是如果要在此基础上识别多种花,还需要在此基础上进行训练,但是训练的过程将简化很多。接下来通过代码来讲解
项目:
Transfer_learning:
--checkpoint #用来保存模型
-- #自动生成的四个文件
--flower_photos #图片
--daisy
--dandeline
--roses
--sunflowers
--tulips
#vgg16模型
--utils.py
--vgg16.npy
--vgg16.py
--app.py
--ftrain.py
--get_features.py
--transfer_test.py
--transfer_train.py
--codes.npy #存储图片特征值
--labels #存储图片的标签
--1.jpg #检测图片
--.......
第一步获取图片的特征,对于vgg16模型,fc1层之前所做的就是提取图片特征,我们无需再费事去训练模型去提取图片的特征,而是直接使用它提供的完善的模型去提取特征,并且它能够很好的把握图片的特征,然后它这些特征存储起来,用于下面的训练。
get_features.py
#coding=utf-8 import os import numpy as np import tensorflow as tf import vgg16 import utils #接下来我们将 flower_photos 文件夹中的花朵图片都载入到进来,并且用图片所在的子文件夹作为标签值。 data_dir = 'flower_photos/' contents = os.listdir(data_dir) classes = [each for each in contents if os.path.isdir(data_dir + each)] #利用vgg16计算得到特征值 # 首先设置计算batch的值,如果运算平台的内存越大,这个值可以设置得越高 batch_size = 10 # 用codes_list来存储特征值 codes_list = [] # 用labels来存储花的类别 labels = [] # batch数组用来临时存储图片数据 batch = [] codes = None with tf.Session() as sess: # 构建VGG16模型对象 vgg = vgg16.Vgg16() input_ = tf.placeholder(tf.float32, [None, 224, 224, 3]) with tf.name_scope("content_vgg"): # 载入VGG16模型 vgg.build(input_) # 对每个不同种类的花分别用VGG16计算特征值 for each in classes: print ("Starting {} images".format(each)) class_path = data_dir + each files = os.listdir(class_path) for ii, file in enumerate(files, 1): # 载入图片并放入batch数组中 img = utils.load_image(os.path.join(class_path, file)) batch.append(img.reshape((1, 224, 224, 3))) labels.append(each) # 如果图片数量到了batch_size则开始具体的运算 if ii % batch_size == 0 or ii == len(files): images = np.concatenate(batch) feed_dict = {input_: images} # 计算特征值 codes_batch = sess.run(vgg.relu6, feed_dict=feed_dict) # 将结果放入到codes数组中 if codes is None: codes = codes_batch else: codes = np.concatenate((codes, codes_batch)) # 清空数组准备下一个batch的计算 batch = [] print ('{} images processed'.format(ii)) #code is a two-dimensional array including features of all pictures #这样我们就可以得到一个 codes 数组,和一个 labels 数组,分别存储了所有花朵的特征值和类别。 #可以用如下的代码将这两个数组保存到硬盘上: #with open('codes', 'w') as f: np.save("codes.npy",codes) #codes.tofile(f) #not good size of file is too big #pickle.dump(codes,f) import csv with open('labels', 'w') as f: writer = csv.writer(f, delimiter=' ') writer.writerow(labels) #pickle.dump(labels,f)
进过上面代码我们已经得到了图片的特征值和标签,接下来,我们需要设置一个全连接层来训练,下面代码中增加了一层256个节点和5个节点的全连接层。
ftrain.py
#coding=utf-8 import os import numpy as np import tensorflow as tf import matplotlib.pyplot as plt from sklearn.preprocessing import LabelBinarizer import vgg16 import utils from sklearn.model_selection import StratifiedShuffleSplit #模型保存的路径和名称 MODEL_SAVE_PATH="./checkpoints/" MODEL_NAME="flowers.ckpt" LABELS = "labels" CODES = "codes.npy" codes = None label = [] labels = [] if CODES: codes = np.load(CODES) else: print ("No such file,please run get_feature.py first") if LABELS: with open(LABELS,"r") as f: label = f.readlines() for line in label: line = line.strip() labels.append(line) else: print ("No such file,please run get_feature.py first") #准备训练集,验证集和测试集 #首先我把 labels 数组中的分类标签用 One Hot Encode 的方式替换 lb = LabelBinarizer() lb.fit(labels) labels_vecs = lb.transform(labels) #return codes,labels,labels_vecs ''' 接下来就是抽取数据,因为不同类型的花的数据数量并不是完全一样的, 而且 labels 数组中的数据也还没有被打乱, 所以最合适的方法是使用 StratifiedShuffleSplit 方法来进行分层随机划分。 假设我们使用训练集:验证集:测试集 = 8:1:1,那么代码如下: ''' ss = StratifiedShuffleSplit(n_splits=1, test_size=0.2) train_idx, val_idx = next(ss.split(codes, labels)) half_val_len = int(len(val_idx)/2) val_idx, test_idx = val_idx[:half_val_len], val_idx[half_val_len:] train_x, train_y = codes[train_idx], labels_vecs[train_idx] val_x, val_y = codes[val_idx], labels_vecs[val_idx] test_x, test_y = codes[test_idx], labels_vecs[test_idx] print ("Train shapes (x, y):", train_x.shape, train_y.shape) print ("Validation shapes (x, y):", val_x.shape, val_y.shape) print ("Test shapes (x, y):", test_x.shape, test_y.shape) #训练网络 ''' 分好了数据集之后,就可以开始对数据集进行训练了, 假设我们使用一个 256 维的全连接层, 一个 5 维的全连接层(因为我们要分类五种不同类的花朵), 和一个 softmax 层。当然,这里的网络结构可以任意修改, 你可以不断尝试其他的结构以找到合适的结构。 ''' # 输入数据的维度 # 标签数据的维度 labels_ = tf.placeholder(tf.int64, shape=[None, labels_vecs.shape[1]]) inputs_ = tf.placeholder(tf.float32, shape=[None, codes.shape[1]]) # 加入一个256维的全连接的层 fc = tf.contrib.layers.fully_connected(inputs_, 256) # 加入一个5维的全连接层 logits = tf.contrib.layers.fully_connected(fc, labels_vecs.shape[1], activation_fn=None) # 得到最后的预测分布 predicted = tf.nn.softmax(logits) # 计算cross entropy值 cross_entropy = tf.nn.softmax_cross_entropy_with_logits(labels=labels_, logits=logits) # 计算损失函数 cost = tf.reduce_mean(cross_entropy) # 采用用得最广泛的AdamOptimizer优化器 optimizer = tf.train.AdamOptimizer().minimize(cost) correct_pred = tf.equal(tf.argmax(predicted, 1), tf.argmax(labels_, 1)) accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32)) #为了方便把数据分成一个个 batch 以降低内存的使用,还可以再用一个函数专门用来生成 batch。 def get_batches(x, y, n_batches=10): """ 这是一个生成器函数,按照n_batches的大小将数据划分了小块 """ batch_size = len(x)//n_batches for ii in range(0, n_batches*batch_size, batch_size): # 如果不是最后一个batch,那么这个batch中应该有batch_size个数据 if ii != (n_batches-1)*batch_size: X, Y = x[ii: ii+batch_size], y[ii: ii+batch_size] # 否则的话,那剩余的不够batch_size的数据都凑入到一个batch中 else: X, Y = x[ii:], y[ii:] # 生成器语法,返回X和Y yield X, Y
经过上面的代码,已经把图片集分成三部分,而且也设置好全连接成,接下来需要把图片特征喂入,开始训练模型。
transfer_train.py
import os import numpy as np import tensorflow as tf import matplotlib.pyplot as plt import vgg16 import utils import ftrain #运行 # 运行多少轮次 epochs = 20 # 统计训练效果的频率 iteration = 0 # 保存模型的保存器 saver = tf.train.Saver() with tf.Session() as sess: sess.run(tf.global_variables_initializer()) coord = tf.train.Coordinator()#4 threads = tf.train.start_queue_runners(sess=sess, coord=coord)#5 for e in range(epochs): for x, y in ftrain.get_batches(ftrain.train_x, ftrain.train_y): feed = {ftrain.inputs_: x, ftrain.labels_: y} # 训练模型 loss, _ = sess.run([ftrain.cost, ftrain.optimizer], feed_dict=feed) print ("Epoch: {}/{}".format(e+1, epochs), "Iteration: {}".format(iteration), "Training loss: {:.5f}".format(loss)) iteration += 1 if iteration % 5 == 0: feed = {ftrain.inputs_: ftrain.val_x, ftrain.labels_: ftrain.val_y} val_acc = sess.run(ftrain.accuracy, feed_dict=feed) # 输出用验证机验证训练进度 print ("Epoch: {}/{}".format(e, epochs), "Iteration: {}".format(iteration), "Validation Acc: {:.4f}".format(val_acc)) # 保存模型 saver.save(sess, os.path.join(ftrain.MODEL_SAVE_PATH, ftrain.MODEL_NAME))
在控制台的输出结果中,我们可以看到随着迭代次数的增加,损失值在不断的降低,精确性也在提高。把训练好的模型保存起来,接下来用测试集来测试模型。
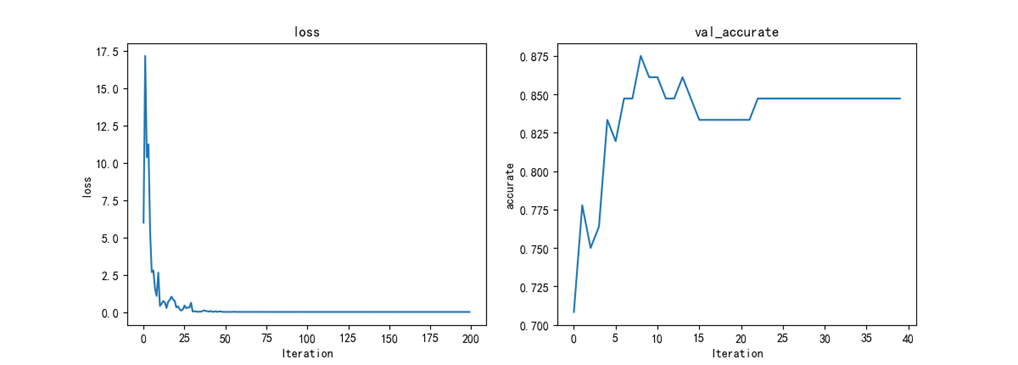
transfer_test.py
#coding=utf-8 import os import numpy as np import tensorflow as tf import ftrain import vgg16 import utils #用测试集来测试模型效果 saver = tf.train.Saver() with tf.Session() as sess: saver.restore(sess,tf.train.latest_checkpoint(ftrain.MODEL_SAVE_PATH)) feed = {ftrain.inputs_: ftrain.test_x, ftrain.labels_: ftrain.test_y} test_acc = sess.run(ftrain.accuracy,feed_dict=feed) print ("Test accuracy: {:.4f}".format(test_acc))
测试代码,加载训练好的模型,然后把测试集代码喂入,计算精确度,控制台可以看到结果,我的结果达到90%以上
然后可以应用这个模型,来识别图片了,这个模型可以识别5中话,可以自己增加。
app.py
#coding=utf-8 import numpy as np import tensorflow as tf import matplotlib.pyplot as plt import vgg16 import utils import ftrain def per_picture(): #deal with picture testPicArr = [] img_path = input('Input the path and image name:') img_ready = utils.load_image(img_path) testPicArr.append(img_ready.reshape((1,224,224,3))) images = np.concatenate(testPicArr) return images labels_vecs = ['daisy','dandelion','roses','sunflower','tulips'] labels_vecs = np.array(labels_vecs) fig=plt.figure(u"Top-5 预测结果") saver = tf.train.Saver() with tf.Session() as sess: #图片预处理 images = per_picture() #输入vgg16中计算特征值 vgg = vgg16.Vgg16() input_ = tf.placeholder(tf.float32, [None, 224, 224, 3]) with tf.name_scope("content_vgg"): # 载入VGG16模型 vgg.build(input_) feed_dict = {input_: images} # 计算特征值 codes_batch = sess.run(vgg.relu6, feed_dict=feed_dict) #返回y矩阵中最大值的下标,如果是二维的加1 preValue = tf.argmax(ftrain.predicted, 1) #加载训练好的新模型 saver.restore(sess, tf.train.latest_checkpoint(ftrain.MODEL_SAVE_PATH)) #计算预测值 preValue = sess.run(preValue, feed_dict={ftrain.inputs_:codes_batch}) print ("The prediction flower is:", labels_vecs[preValue]) probability = sess.run(ftrain.predicted, feed_dict={ftrain.inputs_:codes_batch}) top5 = np.argsort(probability[0]) print ("top5:",top5) values = [] bar_label = [] for n, i in enumerate(top5): print ("n:",n) print ("i:",i) values.append(probability[0][i]) bar_label.append(labels_vecs[i]) print (i, ":", labels_vecs[i], "----", utils.percent(probability[0][i])) ax = fig.add_subplot(111) ax.bar(range(len(values)), values, tick_label=bar_label, width=0.5, fc='g') ax.set_ylabel(u'probabilityit') ax.set_title(u'Top-5') for a,b in zip(range(len(values)), values): ax.text(a, b+0.0005, utils.percent(b), ha='center', va = 'bottom', fontsize=7) plt.show()
上面代码过程是,首先要通过vgg16提取该图片的特征值,然后进行图片预处理,加载训练好的模型,输入进去,获得结果。
结果展示如下:
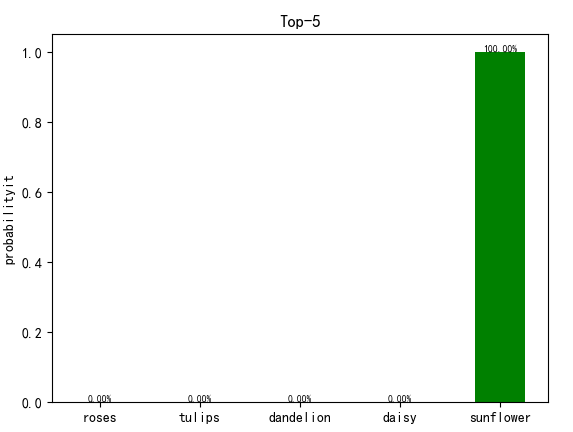
可以看到准确率很高,我每种图片只训练了144张,数据集有800多张。
以上代码可以在windows 下python3的环境运行。
代码和数据集参考自:https://cosx.org/2017/10/transfer-learning/
对于实现以上过程遇到的问题:
(1)首先对迁移学习的理解
对于这个简单的试验,迁移学习主要体现在使用训练好的vgg16模型(存储在vgg16.npy中)提取图片的特征值,然后再对这些特征值训练。
(2)模型的保存和加载
为了避免反复的去提取图片特征值(这个很耗时间),把特征值保存在codes.npy,把图片的标签存储在labels中。还有就是存储训练模型,这里因为对TensorFlow模型不太了解,所以出一个问题
存储模型后,在另一个文件中加载模型发现训练的模型和没训练的模型一样
原因是因为在另一个文件中使用的不是同一个saver,我又对saver进行了初始化,导致使用了一个崭新的模型。
(3)模型保存优化部分:
如果你不给tf.train.Saver()传入任何参数,那么saver将处理graph中的所有变量。其中每一个变量都以变量创建时传入的名称被保存。
有时候在检查点文件中明确定义变量的名称很有用。举个例子,你也许已经训练得到了一个模型,其中有个变量命名为"weights",你想把它的值恢复到一个新的变量"params"中。
有时候仅保存和恢复模型的一部分变量很有用。再举个例子,你也许训练得到了一个5层神经网络,现在想训练一个6层的新模型,可以将之前5层模型的参数导入到新模型的前5层中。
你可以通过给tf.train.Saver()构造函数传入Python字典,很容易地定义需要保持的变量及对应名称:键对应使用的名称,值对应被管理的变量。
增加:
对于代码中数据集增加,代码会报错,这里有同学发现了解决办法
