数据查询语言
关键字 select
where 条件
order by 排序
asc(升序)、desc(降序)
排序语法:order by 字段1 [asc]|desc [,字段2 [asc]|desc,....]
MySQL中中文排序规则
注意:在utf—8编码集下排序并不是按照中文拼音进行排序,需要改为GBK编码集
修改为按照拼音排序方法:
SELECT * FROM teachers ORDER BY CONVERT(tName USING GBK),tage DESC;
limit
取前多少条-limit
limit语法:limit m[,n]
说明: 当limit后只有M一个数字是时,表示在结果集中取前m条数据
当limit后有两个数字时,表是在结果集中从M+1开始取n条数据
例子:
SELECT * FROM teachers ORDER BY tage DESC LIMIT 2;
取前面两条
SELECT * FROM teachers ORDER BY tage DESC LIMIT 1,1;
从第二条开始取一条
使用limit分页
limit (页码-1)*每页显示信息数,每页显示信息数
SELECT * FROM ta ORDER BY id DESC LIMIT 0,2;
第一页信息,每页两条数据
SELECT * FROM ta ORDER BY id DESC LIMIT 1,2;
第二页信息,每页两条数据
聚合函数
max():最大值
min():最小值
avg():平均值
sum():求和
count():求数目(符合条件的数据的数量)
注意:
#聚合函数不能嵌套使用
#对于聚合函数:空值(null)不参与统计计算
例:
SELECT COUNT(*) FROM elogs
count()括号里可以跟星号,主键字段,数字1。但是建议跟主键字段
统计elogs表有多少条记录
错例:
SELECT COUNT(tage),tage FROM teachers;-- 在普通sql语句中不允许这样书写(count()返回一条数据,而tage代表一列数据)
having子句
与where字句类似,都是进行数据的筛选,只不过它是在分组之后;而where是在分组之后被执行
having与where的不同
1、执行顺序不同(having子句是在分组之后执行;而where子句是在分组之前执行)
2、聚合函数的使用不同(having子句可直接使用聚合函数,而where不行)
Group by子句
分组技术的语法:
SELECT 字段列表 FROM 表名 [WHERE 条件表达式] GROUP BY 字段1[,字段2] [HAVING 条件表达式
ORDER BY 排序字段] [LIMIT m[,n]]
例子:
统计在选修记录信息表中,已登记同学每人选修课程门数
select * from ELogs
select count(*) from ELogs group by sID;
去重--distinct
用法实例:
去除cid重复的记录再统计条数
SELECT COUNT(DISTINCT cid) FROM elogs
合并结果集--union
注意:默认情况下对重复值去重,如不想去重,则需要在其后加ALL
SELECT sname FROM students
UNION
SELECT tname FROM teachers;
(表或列)重命名
方式1:oldname as newname
方式2:oldname newname
SELECT COUNT(*) AS '学生人数' FROM students
SELECT COUNT(*) '学生人数' FROM students
子查询
例:
SELECT * FROM ta;

SELECT * FROM te;
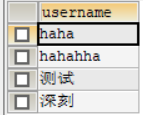
SELECT * FROM ta WHERE NAME IN (SELECT * FROM te);
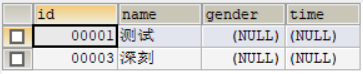
多表联合查询
SELECT * FROM Courses INNER JOIN teachers ON tNo=tID;
将Courses表和teachers表通过tNo、tID属性连接起来
外连接outer join
左外连接:left outer join/left join
右外连接:right outer join/ right join
拓展链接:https://blog.csdn.net/u012410733/article/details/63684663