PART ONE 编码常识
前两天已经初步了解了一下编码的知识,现在先简单进行回顾:
ASCII码:包含英文字母,数字,特殊字符与01010101对应关系。
1个字符8位(1个字节)
A 00000010
gbk:只包含本国文字(以及英文字母,数字,特殊字符)与0101010对应关系。
A 00001001 8位(1个字节)
中 00000001 00010010 16位(2个字节)
Unicode:包含全世界所有的文字与二进制0101001的对应关系。
A 00000000 00000000 00001000 10001000 4字节
中 00000000 01001000 00001000 01000000 4字节
utf-8:包含全世界所有的文字与二进制0101001的对应关系(最少用8位一个字节表示一个字符)。
A 0010 0000 8位(1个字节)
中 00001000 00000100 01001000 24位(3个字节)
PS:
1、各个编码的二进制是不能互相识别的额,会产生乱码
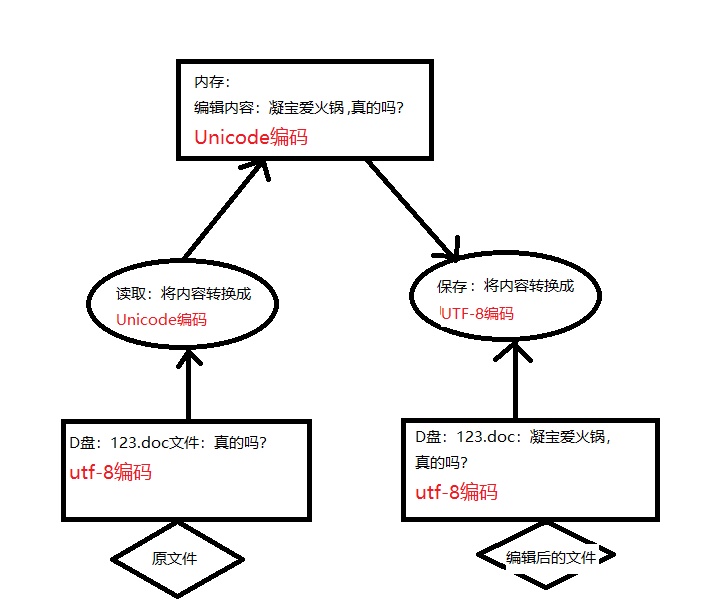
2、文件的储存、传输,不能是Unicode(只能是utf-8、utf-16、gbk、GB2312等)
3、在计算机内存中,统一使用Unicode编码,当需要将数据保存到硬盘或者需要网络传输的时候,就转换为非Unicode编码比如:UTF-8编码。
python3:str在内存中是用Unicode编码的
bytes类型:
对于英文:str:表现形式:s='alex'
编码方式 01010100 Unicode
bytes:表现形式:s=b'alex'
编码方式 00100010 utf-8 gbk...
对于中文:str:表现形式:s='中国'
编码方式 01010100 Unicode
bytes:表现形式:s=b'xe91e91eD1e21e31e32'
编码方式 00100010 utf-8 gbk...
str-->bytes的转换
s1='alex' #encode 编码,如何将str-->bytes 可设置编码方式 s11=s1.encode('utf-8') print(s11) #b'alex' s2='中国' s22=s2.encode('utf-8') print(s22) #b'xe4xb8xadxe5x9bxbd' s3='中国' s33=s3.encode('gbk') print(s33) #b'xd6xd0xb9xfa'
bytes-->str的转换
# decode称作解码, 将 bytes 转化成 str类型 b1 = b'xe4xb8xadxe5x9bxbd' s1 = b1.decode('utf-8') print(s1) # 中国
注意:bytes类型他叫字节文本,他的编码方式是非Unicode的编码,非Unicode即可以是gbk,可以是UTF-8,可以是GB2312.....
那么gbk编码的bytes如何转化成utf-8编码的bytes呢?
不同编码之间,不能直接互相识别。
上面我说了,不同编码之间是不能直接互相是别的,这里说了不能直接,那就可以间接,如何间接呢? 现存世上的所有的编码都和谁有关系呢? 都和万国码Unicode有关系,所以需要借助Unicode进行转换。通俗的讲就是先将文件encode成Unicode的文件,在decode成想要的文件。
PART TWO 文件
1、文件路径:
绝对路径:从磁盘根目录开始一直到文件名
相对路径:用一个文件夹下的文件,相对于当前这个程序所在的文件而言.如果在同一个文件中,则相对路劲就是这个文件名.如果再上一层文件夹则要使用../相对路径下,你就可以直接写文件名即可。
2、编码方式:utf-8 gbk 。。。
注意:以什么编码方式储存的就得以什么编码方式打开
文件用不同的工具编辑存储时可能采用不同的编码方式,比如Word软件默认的编码为utf-8,但是用python代码打开的时候用的gbk就会报错

3、操作方式:只读r、只写w、追加、读写、写读。。。
f = open('e:Python测试.txt', mode='r', encoding='gbk') content = f.read() print(content) #床前明月光,疑是地上霜。举头望明月,低头思故乡。 f.close()
代码解释:
f: 就是一个变量,一般都会将它写成f,f_obj,file,f_handler,fh,等,它被称作文件句柄。
open:是Python调用的操作系统(windows,linux,等)的功能。
'e:Python测试.txt': 这个是文件的路径。
mode: 就是定义你的操作方式:r为读模式。
encoding: 不是具体的编码或者解码,他就是声明:此次打开文件使用什么编码本。一般来说:你的文件用什么编码保存的,就用什么方法打开,一般都是用utf-8(有些使用的是gbk)。
f.read():你想操作文件,比如读文件,给文件写内容,等等,都必须通过文件句柄进行操作。
f.close(): 关闭文件句柄(可以把文件句柄理解成一个空间,这个空间存在内存中,必须要主动关闭)
只读:r --> 以只读方式打开文件,文件的指针将会放在文件的开头。是文件操作最常用的模式,也是默认模式,如果一个文件不设置mode,那么默认使用r模式操作文件。
ps:read()、readline()、readlines()、for循环读取
read()读取的时候指定读取到什么位置。在r模式下,n按照字符读取。
readline()读取每次只读取一行,注意点:readline()读取出来的数据在后面都有一个 (若要解决这个问题,只需在我们读取的文件后面加一个strip()就可以了)
readlines() 返回一个列表,列表里面每个元素是原文件的每一行,如果文件很大,占内存,容易崩盘
for循环:通过for循环去读取,文件句柄是一个迭代器,他的特点就是每次循环只在内存中占一行的数据,非常节省内存。
二进制读:rb-->以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。记住下面讲的也是一样,带b的都是以二进制的格式操作文件,他们主要是操作非文字文件:图片,音频,视频等,并且如果你要是带有b的模式操作文件,那么不用声明编码方式。
#二进制读 f = open('123', mode='rb') content = f.read() print(content) #b'xe5xbax8axe5x89x8dxe6x98x8exe6x9cx88xe5x85x89xefxbcx8cxe7x96x91xe6x98xafxe5x9cxb0xe4xb8x8axe9x9cx9cxe3x80x82' f.close()
只写:w -->如果文件不存在,利用w模式操作文件,那么它会先创建文件,然后写入内容.如果文件存在,利用w模式操作文件,先清空原文件内容,在写入新内容。
二进制写:wb-->以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如:图片,音频,视频等。
#对于W,没有此文件就会创建
f = open('log', mode='w', encoding='utf-8')
f.write('柳柳爱火锅')
f.close()
#对于W,有此文件会先清除原文件的内容,再写
f = open('log', mode='w', encoding='utf-8')
f.write('凝宝也爱火锅')
f.close()
f = open('log', mode='wb')
f.write('凝宝也爱火锅'.encode('utf-8'))
f.close()
追加:a-->打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。如果文件不存在,利用a模式操作文件,那么它会先创建文件,然后写入内容。 如果文件存在,利用a模式操作文件,那么它会在文件的最后面追加内容。
f=open('log',mode='a',encoding='utf-8') f.write('真的吗?') f.close()
读写:r+ --> 打开一个文件用于读写。文件指针默认将会放在文件的开头。
注意:如果你在读写模式下,先写后读,那么文件就会出问题,因为默认光标是在文件的最开始,你要是先写,则写入的内容会讲原内容覆盖掉,直到覆盖到你写完的内容,然后在后面开始读取。
二进制形式读写r+b#r+:先读后加
f = open('log', mode='r+', encoding='utf-8')
print(f.read())
f.write('柳柳爱火锅')
f.close()
#r+:先加再读
f = open('log', mode='r+b')
print(f.read())
f.write('柳柳爱火锅'.encode('utf-8'))
f.close()
seek():seek(n)光标移动到n位置,注意: 移动单位是byte,所有如果是utf-8的中文部分要是3的倍数
通常我们使用seek都是移动到开头或者结尾
移动到开头:seek(0)
移动到结尾:seek(0,2) seek的第二个参数表示的是从哪个位置进行偏移,默认是0,表示开头,1表示当前位置,2表示结尾
tell(): 使用tell()可以帮我们获取当前光标在什么位置
#功能详解 f=open('log',mode='r+',encoding='utf-8') # content=f.read(3) #读规定字符数 f.seek(3)#按字节去定光标 1个字符3个字节 f.tell()#告诉你光标的位置 print(f.tell()) content=f.read() print(content) f.close()
f=open('log',mode='r+',encoding='utf-8') # line=f.readline() #一行一行的读 # print(line) #柳柳爱火锅 lines=f.readlines() #每一行当做列表中的一个元素,追加到list中 print(lines) #['柳柳爱火锅 ', '凝宝也爱火锅'] f.close()
打开文件的另一种方式:with open()as ...
# 1,利用with上下文管理这种方式,它会自动关闭文件句柄。 with open('t1',encoding='utf-8') as f1: f1.read() # 2,一个with 语句可以操作多个文件,产生多个文件句柄。 with open('t1',encoding='utf-8') as f1, open('Test', encoding='utf-8', mode = 'w') as f2: f1.read() f2.write('柳柳爱火锅')
这里要注意一个问题,虽然使用with语句方式打开文件,不用你手动关闭文件句柄,比较省事儿,但是依靠其自动关闭文件句柄,是有一段时间的,这个时间不固定,所以这里就会产生问题,
如果你在with语句中通过r模式打开t1文件,那么你在下面又以a模式打开t1文件,此时有可能你第二次打开t1文件时,第一次的文件句柄还没有关闭掉,可能就会出现错误,他的解决方式只能在
你第二次打开此文件前,手动关闭上一个文件句柄。