集成学习
一、理论部分
1. 集成学习
- bagging 通过降低方差的方式减少预测误差
- boosting 最终的预测效果是通过不断减少偏差的形式
- Adaptive Boosting
- Gradient Boosting
- 变体
- Xgboost
- LightGBM
- Catboost
2.Boosting思想
- 弱学习
把准确率不高但在50%以上(比如60%)的算法称为弱学习。 - 强学习
识别准确率很高并能在多项式时间内完成的学习算法 - 思想:
从弱学习算法出发,反复学习,得到一些列弱分类器(基本分类器),然后组合这些弱分类器构成一个强分类器。通过改变训练数据及的概率分布,针对不同概率分布的数据调用弱分类算法学习一系列的弱分类器。- 如何改变数据的概率分布
- 如何将各个弱分类器组合
3. Adaboost算法介绍
- Adaboost是一种boosting算法。属于ensemble learning集成学习。
- 弱分类器
把准确率不高但在50%以上(比如60%)的分类器称为弱分类器,弱分类器可以是一些基础的ML算法比如单层决策树等。 - 基分类器
对于同一数据可能有多种弱分类器,adaboost就是将这些弱分类器结合起来,称为基分类器,从而有效提高整体的准确率。 - 如何解决上述boosting算法两个问题:
- 1)提高那些被前一轮分类器错误分类的样本的权重,而降低被正确分类的样本的权重
- 2)各个弱分类器的组合是通过采用加权多数表决的方式:加大分类错误率低的弱分类器的权重,因为这些分类器能更好地完成分类任务,是他在表决中起到较大作用。
但是要想获得好的结合或者集成,对基分类器的要求是“好而不同”,即有一定的准确率,而且弱分类器之间要有“多样性”,比如一个判断是否为男性的任务,弱分类器1侧重从鼻子、耳朵这些特征判断是否是男人,分类器2侧重脸和眼睛等等,把这些分类器结合起来就有了所有用来判断是否男性的特征,并且adaboost还可以给每个基分类器赋值不同的权重,比如从脸比鼻子更能判断是否为男性,就可以把分类器2的权重调高一些,这也是adaboost需要学习的内容。
4.数学推导
AdaBoost可以表示为基分类器的线性组合:
其中\(h_i(x),i=1,2,...\)表示基分类器,\(\alpha_i\)是每个基分类器对应的权重,表示如下:
其中\(\epsilon_{i}\)是每个弱分类器的错误率。
二、实践部分
1.数据集
UCI机器学习库的开源数据集:葡萄酒数据集
该数据集包含了178个样本和13个特征,对三个不同品种的葡萄酒进行化学分析的结果,结果包含在三种类型的葡萄酒中发现的13中成分的含量。我们的任务是根据这些数据预测红酒属于哪一类别。
2.使用sklearn对Adaboost算法进行建模
引入数据科学相关工具包
import pandas as pd
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.model_selection import GridSearchCV
import matplotlib.pyplot as plt
加载数据集,并按照8:2的比例分割成训练集和测试集
wine = load_wine()
print(f"所有特征:{wine.feature_names}")
X = pd.DataFrame(wine.data, columns=wine.feature_names)
y = pd.Series(wine.target)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=1)
所有特征:['alcohol', 'malic_acid', 'ash', 'alcalinity_of_ash', 'magnesium', 'total_phenols', 'flavanoids', 'nonflavanoid_phenols', 'proanthocyanins', 'color_intensity', 'hue', 'od280/od315_of_diluted_wines', 'proline']
使用单一决策树建模
base_model = DecisionTreeClassifier(max_depth=1, criterion='gini',random_state=1).fit(X_train, y_train)
y_pred = base_model.predict(X_test)
print(f"决策树的准确率:{accuracy_score(y_test,y_pred):.3f}")
决策树的准确率:0.694
使用sklearn实现AdaBoost算法建模(基分类器是决策树)

from sklearn.ensemble import AdaBoostClassifier
model = AdaBoostClassifier(base_estimator=base_model,
n_estimators=50,
learning_rate=0.5,
algorithm='SAMME.R',
random_state=1)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
print(f"AdaBoost的准确率:{accuracy_score(y_test,y_pred):.3f}")
AdaBoost的准确率:0.972
结果分析
单层决策树对于训练数据欠拟合,而Adaboost模型正确地预测了训练数据的分类标签,准确率有了很大的提高。
3.测试估计器个数的影响(n_estimators)
x = list(range(2, 102, 2))
y = []
for i in x:
model = AdaBoostClassifier(base_estimator=base_model,
n_estimators=i,
learning_rate=0.5,
algorithm='SAMME.R',
random_state=1)
model.fit(X_train, y_train)
model_test_sc = accuracy_score(y_test, model.predict(X_test))
y.append(model_test_sc)
plt.style.use('ggplot')
plt.title("Effect of n_estimators", pad=20)
plt.xlabel("Number of base estimators")
plt.ylabel("Test accuracy of AdaBoost")
plt.plot(x, y)
plt.show()
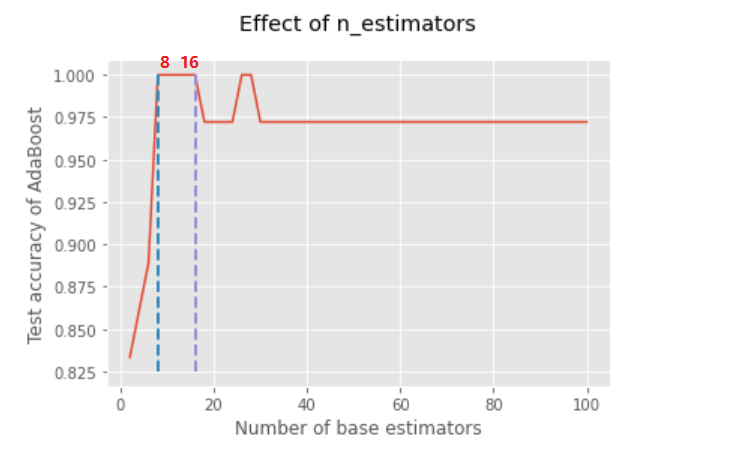
可以看出:随着迭代次数的升高,测试精度显示升高,后面保持不变,可以选择在精度最高且训练次数比较少的情况下进行。
这个点是(8,1)也就是迭代8次,精度为1
或者(16,1)
4.测试学习率的影响(learning_rate)
x = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1]
y = []
for i in x:
model = AdaBoostClassifier(base_estimator=base_model,
n_estimators=50,
learning_rate=i,
algorithm='SAMME.R',
random_state=1)
model.fit(X_train, y_train)
model_test_sc = accuracy_score(y_test, model.predict(X_test))
y.append(model_test_sc)
plt.title("Effect of learning_rate", pad=20)
plt.xlabel("Learning rate")
plt.ylabel("Test accuracy of AdaBoost")
plt.plot(x, y)
plt.show()
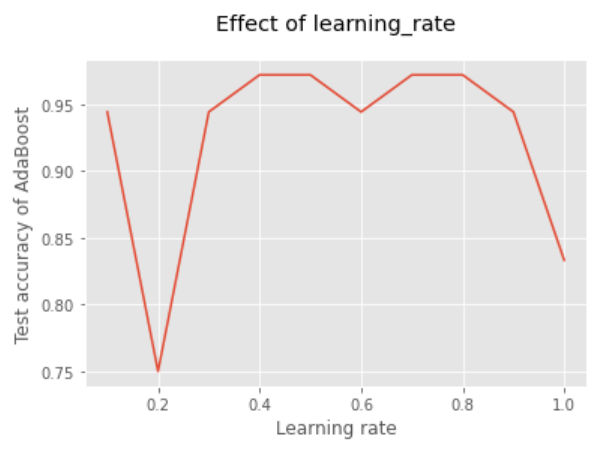
结果分析:学习率为0.4、0.5测试精度都是最高的
5.改进
选择 n_estimators=16,learning_rate=0.5得到预测精度为1