《深入理解计算机系统》第二章 信息的表示与处理
在计算机中有三种重要的数字表示,无符号编码,补码编码和浮点数编码。在高级语言程序中需要定义所处理数据的类型以及存储的数据结构,比如我们所熟悉的C语言程序中有三种重要的数字表示:无符号整数类型 (unsigned int),带符号整数类型 (int) 浮点型类型 (float 、double)等等。
在计算机内部,这些数据都是如何体现的呢?拿我们每天使用的app来举例,高级语言编写出一个个的程序,这个程序需要转换成一条条指令,才能在微体系结构上执行,为了让app中的文字、图片、音频视频在计算机中处理、运作,这些文件都将变成01序列。
一. 进制及其转换
1. 十进制
生活中我们最常见的也最常用的数就是十进制计数
十进制数的每个数位用0,1,2,...,9来表示
其中,di可以是 0,1,2,3,4,5,6,7,8,9这10个数字符号中的任何一个;

“10”称为基数(base),它代表每个数位上可以使用的不同数字符号个数。10i 称为第i位上的权。
计算时, “逢十进一”
2. 二进制
C语言中,比如一个数int num=10,这个int型的数据在指令层面的体现,就是一串二进制01序列。那么为什么计算机内部、指令层面都要使用二进制编码呢?其实很好理解,我们可以使用0和1来表示许多内容,比如逻辑的真假、电平的高低等。再其次,二进制编码的计算很简单,0加1是1,1加1是进位之后的0.计算及内部有很多需要进行逻辑判断的地方,这个时候0和1的作用就体现出来了,1是真,0是假,计算机中的逻辑运算就可以直接使用二进制进行计算。

二进制数是机器级表示中最常用的数值表示,每个数位都用0或者1表示。
“2”称为基数(base),它代表每个数位上可以使用的不同数字符号个数。2i 称为第i位上的权。
运算时,“逢二进一”。
3. 八进制
看完二进制,我们再来看八进制数,
八进制数的每个数位用0,1,2,...,7来表示
其中,oi可以是 0,1,2,3,4,5,6,7这8个数字符号中的任何一个;

“8”称为基数(base),它代表每个数位上可以使用的不同数字符号个数。8i 称为第i位上的权。
计算时, “逢八进一”
4. 十六进制
在计算机中,二进制和十进制都不算是最方便的数值表示法,
因为表示某个数会过于冗长,十进制表示法又无法体现“位”的概念。
于是在计算机中,十六进制成了二进制的Plus版。

十六进制每个数位用0,1,2…,A,B,C,D,E,F来表示。
运算时,逢16进1。
5. 进制转换
- 十进制与二进制之间的转换:
先看整数部分:
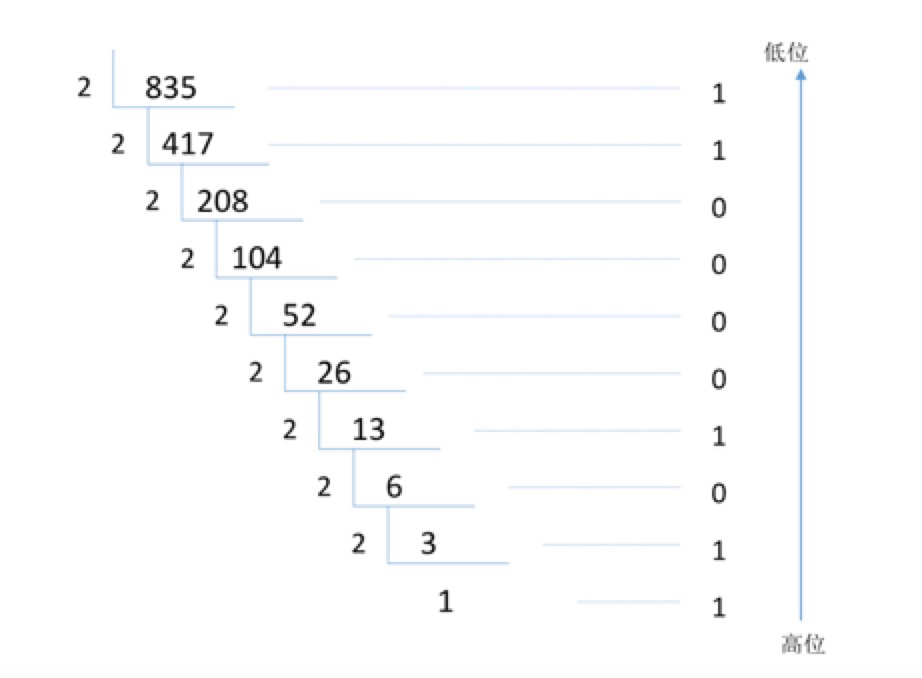
整数部分除以2,余数为权位上的数,得到的商值继续除以2,依此步骤继续向下运算直到商为0为止。
对于小数部分使用乘法,把一个十进制数的小数部分不断地乘2,记录结果的整数部分,并从上至下排列,就是小数部分的二进制表示。如0.1011表示0.6875.
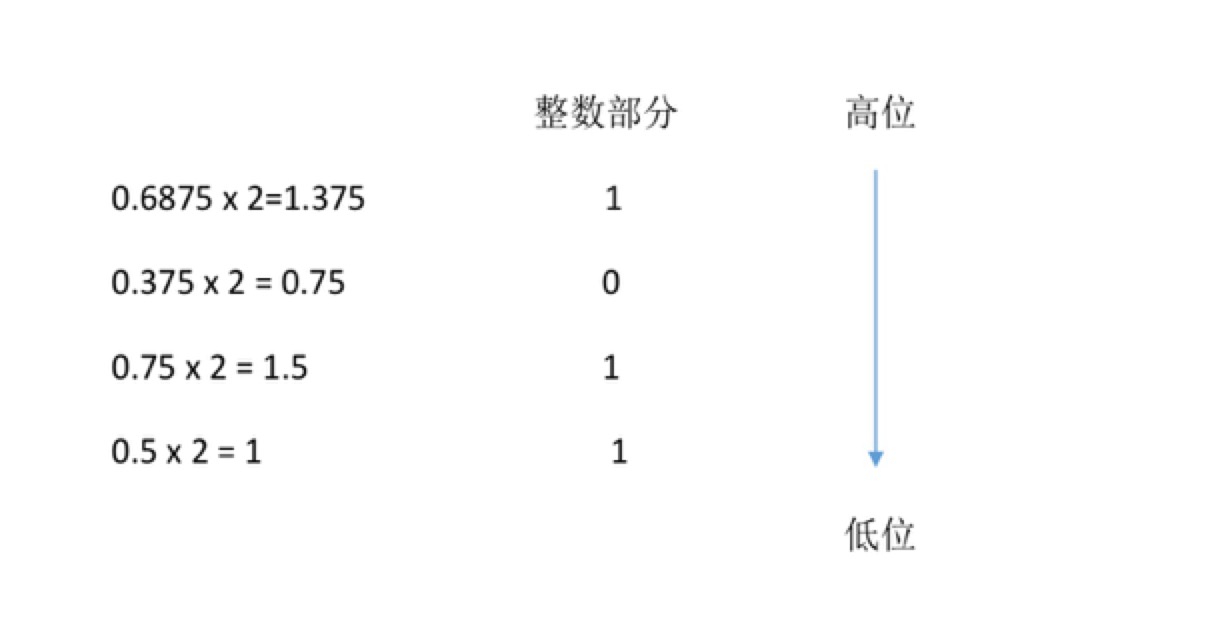
那么835.6875的二进制表示就是1101000011.1011
C语言代码:
#include<stdio.h>
int main()
{
int b,i,c=0,a[30];
scanf("%d",&b);
while(b!=0)
{
i=b%2;
a[c]=i;
c++;
b=b/2;
}
c--; //因为c代表存入数据的长度而下表范围是0~c-1
for(;c>=0;c--)//倒序输出即为这个数字对应的二进制
{
printf("%d",a[c]);
}
printf("
");
return 0;
}
- 十进制与八进制之间的转换:
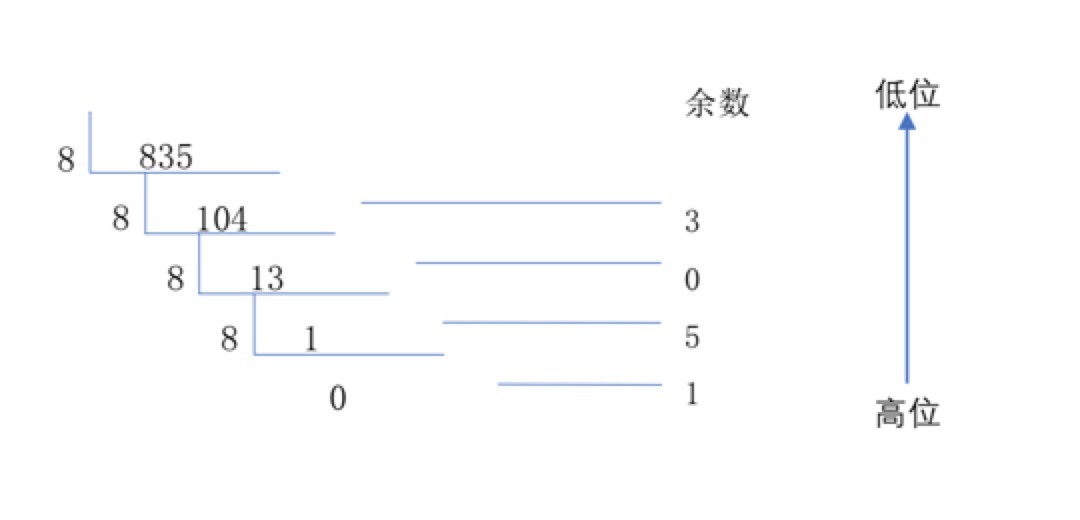
同样的,在十进制与八进制转换过程中,整数部分除以8,余数为权位上的数,得到的商值继续除以8,依此步骤继续向下运算直到商为0为止。
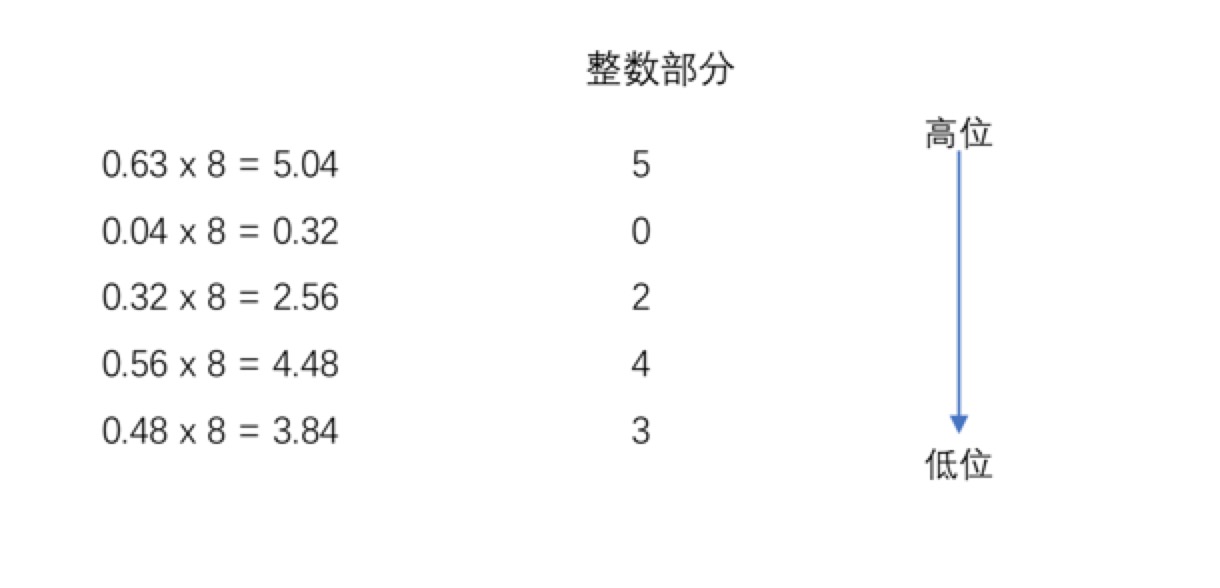
对于小数部分使用乘法,把一个十进制数的小数部分不断地乘8,记录结果的整数部分,并从上至下排列,就是小数部分的八进制表示。
-
十进制与R进制转换:
我们看一个普遍情况,R进制,这里的R可以是任何正整数。
同样的操作,对整数部分除以R,余数为权位上的数,得到的商值继续除以R,依此步骤继续向下运算直到商为0为止。将余数从低到高记录,就是R进制数的整数部分。
对于小数部分使用乘法,把一个十进制数的小数部分不断地乘R,记录结果的整数部分,并从上至下排列,就是小数部分的R进制表示。
-
二进制与十进制的转换:
二进制转换为十进制的时候就简单的多,只要按照权乘以数位的运算就好了。
为大家举一个二进制转换十进制的例子:
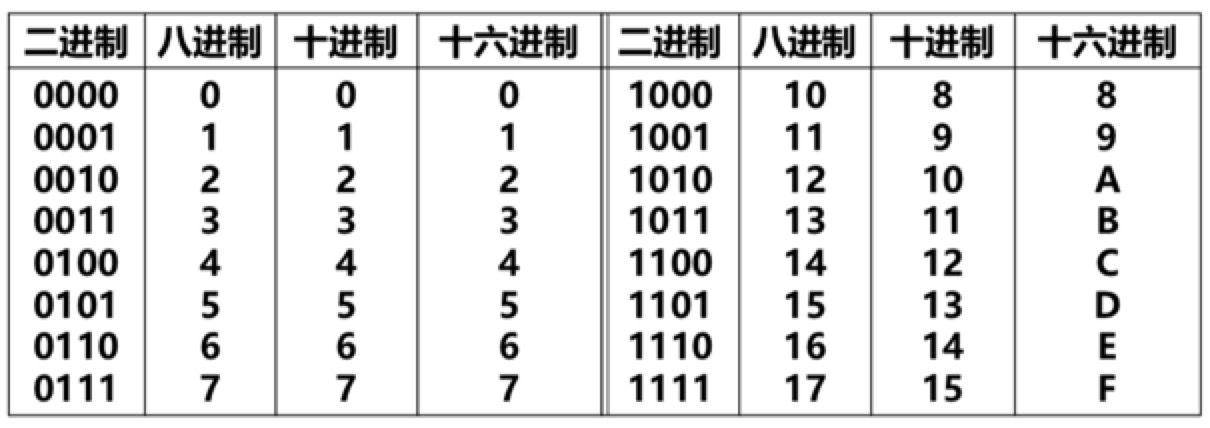
1101000011.1011转换为十进制的值是
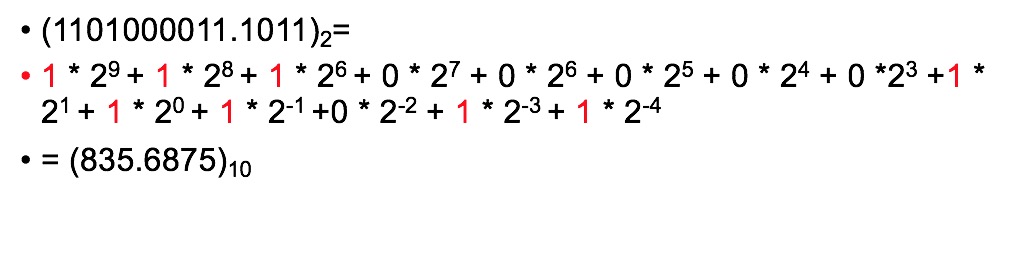
-
二进制与八进制之间的转换:
计算机中通常用三位二进制数来表示一位八进制数,不足的在最高位补0。
比如二进制的101,十进制表示是5,八进制中就是5。八进制的0对应二进制的000,7对应111.
在机器内部用二进制表示数值,在屏幕或者其他设备上表示时,转换为八进制或者十六进制数,可缩短长度。 -
二进制转十六进制:
为什么说十六进制是二进制的plus版?二进制和十六进制有很方便的转化方式,其主要原因是2 ^ 4=16。
十六进制使用'0''9'和'A''F'来表示十进制中的0~16,同时对应每4位二进制数。十六进制和二进制的转换过程是这样的:十进制的15用二进制表示是
[1111]=(2^3+2^2+2^1+2^0)
,十六进制中对应的数是F。以下列出十六进制、十进制、二进制的对应转换:

二、 位向量的引入
位向量就是固定长度为w、由0和1组成的串。在计算机中,许多运算是发生在位级别上的,包括位级运算和逻辑运算,还有移位运算等。
1. 位级运算
位级运算也称为按位布尔运算。布尔运算中使用的与或非和异或符号,对应在C语言中就是&(与),|(或),~(取反),^(异或)。这些运算能运用到任何“整型”数据类型上。
-
(&)与运算
- 与运算,即当两个数据或多个数据的同一位都是1时,与完的结果是1,其余情况都为0。
- [0110 1001] & [0101 0101] = [0100 0001]
-
(|)或运算
- 或运算,当多个数据的同一位中至少有一个1,或运算后的结果是1,当全为0时结果为0。
- [0110 1001] | [0101 0101] = [0111 1101]
-
(~)取反运算
- 取反运算即数据的每一位取反,0取反为1,1取反为0。
- ~[0110 1001] = [1001 0110]
-
(^)异或运算
- 异或运算即多个数据的同一位上,相同为0,不同为1。
- [0110 1001] ^ [0101 0101] = [0011 1100]
-
位级运算还有一个应用,就是可以取出某些数据中的一部分。比如说0x69这个数,如果我只想要高位6或者低位的9,该怎么办?这里我们先介绍取低位的操作,取高位我们要结合后面课程的内容。
- 我们知道,位上和1相与,结果是这个位本身,而和0相与,结果置0。
- 想要取出0x69的低位0x09,我们只需要保留9,去掉6。
- 这里我们通过把0x69和0x0F相与,以保证6被置0,而9保留。
-
我们可以想到更广泛的使用,想要保留的位置1,想去掉的置0,只要把想要操作的数和一个这样位模式的数相与就可以得到你想要保留的位。
0x69 = [0110 1001]
0x09 = 0x69 & 0x0F
= [0110 1001] & [0000 1111]
= [0000 1001]
2. 逻辑运算
C语言中还有一组和位级运算中很像的运算符,&&,||,!,他们是逻辑运算符,分别对应命题逻辑中的OR、AND、和NOT运算。
逻辑运算符号看起来容易和位级运算混淆,但要注意的是,它们的功能是完全不同的。
逻辑运算认为所有非零参数都表示TRUE,0表示FALSE,返回1或者0。
- (&&)AND
- 逻辑与:将&&前后的参数视作0或者1,1代表非零参数非零参数。同样的,参数全为1时结果为1,即使有一个参数为0时结果为0。
- 0x69 && 0x55 = 0x01
- 0x69 && 0x00 = 0x00
- (||)OR
- 逻辑或:同上,参数中有一个为1,整体结果为1。
- 0x69 || 0x00 = 0x01
- (!)NOT
- 逻辑非,更好理解,TRUE的 非是FALSE,FALSE的非是TRUE。
- !0x69 = 0x00
- !0x00 = 0x01
3. 移位运算
移位运算即向左或者向右移动位模式。
-
左移:对于一个位表示为[xw-1,xw-2,…,x0]的操作数,x << k(0 ≤ k ≤ w-1)会生成一个值,其位表示为[xw-k-1,xw-k-2,…,x0,0,…(共k个0)…,0]。
x向左移动k位,丢弃最高的k位,并在最低位后补k个0。 -
我们来看一个例子:数x的位模式是[0101 0111]
我们将x左移两位,x << 2,最末端补0变成[0101 0111 00]
然后高两位抛弃,x左移两位的结果就是[0101 1100] -
右移:右移跟左移不一样的是,机器支持两种形式的右移:逻辑右移和算术右移。
- 逻辑右移在最高位左端补k个0,得到的结果是[0,…,0,xw-1,xw-2,…,xk]
- 算术右移是在最高位左端补最高有效位的值,得到的结果是[xw-1,…,xw-1,xw-2,…,xk]
-
之所以区分逻辑右移与算术右移是因为,如果不区分,代码的可移植性问题上无法解决。
-
几乎所有的编译器和机器组合都对有符号数使用算术右移,这样才能保证数值的正负不发生变化;
-
对于无符号数,右移必须是逻辑右移。
-
我们来看一个逻辑右移:数x的位模式是[0101 0111]我们对x进行逻辑右移两位的操作,最高位补0变成[00 0101 0111]然后将低两位抛弃,x逻辑右移两位的结果就是[0001 0101]
-
再看算数右移:这里我们拿两个数对比着看
数x的位模式是[0101 0111] 和[1101 0111],区别在于他们的最高位不同。之前我们说过,算术右移会在位的最高位左端补上最高有效位的值。 -
先看第一个数,在x的左端补上最高位,也就是0,变成[00 0101 0111]
然后低两位抛弃,此时x算术右移两位的结果就是[0001 0101]。 -
再看[1101 0111]这个数的算术右移过程,按照约定我们在x的左端补上的是最高位也就是1,变成[11 0101 0111]同样的,可以看到x算术右移的结果是[1101 0101]。
-
刚刚我们看了取出0x69中低位9的方法,那么如何取出高位6呢?这就要用到移位知识了。按照之前的知识,我们先将0x69这个数高位保留,低位置0,那么我们需要将0x69和0xF0相与,这样的到了0x60这个结果。
-
我们想要得到的是0x06,那么我们只需要把这个数进行右移,注意是逻辑右移,我们需要高位保持0。将0x60右移4位,我们得到0x06,这个结果也就是0x69的高位数。
由此看来,我们可以通过移位运算和位级运算来得到某个数据的我们需要的一部分。
0x69 = [0110 1001]
0x60 = [0110 1001] & [1111 0000] = [0110 0000]
0x60 -> 0x06
[0110 0000] >>> 4 =[0000 0110]
三、计算机中的无符号整数、有符号整数和浮点数
刚才提到小数点,计算机里面只有0和1,小数点是无法表示的,那么我们约定小数点的位置,计算机硬件和计算机指令明确小数点的位置在哪,只要约定好了以后,按照约定来解释这个小数点,小数的问题就可以解决了。
小数点的位置约定在固定位置的小数,称为定点数, 小数点的位置约定的是可浮动的,称为浮点数,定点数有两种,一种是定点小数,一种是定点整数, 定点小数通常是用来表示浮点数的尾数部分,定点整数用来表示整数,这个整数可以是带符号的,也可以是无符号的。
1. 有符号整数:
定点数的编码通常通过原码补码来表示。
先来看定点数中的有符号整数:
最容易理解的是原码表示:B2S4([])
一个有符号的整数,“正”号用0表示,“负”号用1表示,数值部分同二进制。
比如:
B2S4([1010])=(-1) * [0*2 ^ 0+ 1 * 2^1 + 0 * 2^2]
(加粗部分表示符号位)
| 十进制 | 二进制 |
|---|---|
| 0 | 0 000 |
| 1 | 0 001 |
| 2 | 0 010 |
| 3 | 0 011 |
| 4 | 0 100 |
| 5 | 0 101 |
| 6 | 0 110 |
| 7 | 0 111 |
| 十进制 | 二进制 |
|---|---|
| -0 | 1 000 |
| -1 | 1 001 |
| -2 | 1 010 |
| -3 | 1 011 |
| -4 | 1 100 |
| -5 | 1 101 |
| -6 | 1 110 |
| -7 | 1 111 |
补码表示:
在计算机中,有符号数最常见的表示方式就是补码形式,在补码编码中,字的最高有效位解释为负权。
例如:
B2T4([0101])=-0*2^3+1*2^2+0*2^1+1*2^0=5
B2T4([1011])=-1*2^3+0*2^2+1*2^1+1*2^0=-5
也就是说,最高位虽然还是符号位,但还要乘上它的权重。
2. 无符号整数
定点数中的无符号整数编码:
B2U4([1011])=1*2^3+0*2^2+1*2^1+1*2^0=11
每一位的权重*数码(0/1)即可。
3. c语言中的整数
计算机中的无符号整数:
计算机中有两种位排序方式:大端法和小端法。
比如0011 1011,小端法在机器中的记录就是0011 1011,而在大端法机器中的记录会是1101 1100。目前大多数机器都是小端法表示数据了。
一般在全都是正数运算(排除相减后结果是负数的情况)的时候,使用无符号数的表示。比如地址的运算。
c语言中整数分为无符号整数和有符号整数,下面看一段程序示例:
#include <stdio.h>
int main(int argc, const char * argv[]) {
int x = -1;
unsigned u=2147483648;
printf("x = %u = %d
",x,x);
printf("u = %u = %d
",u,u);
}
运行结果是
x = 4294967295 = -1
u = 2147483648 = -2147483648
那么这个数值是怎么算出来的呢?首先,int和unsigned int在计算机中的存储长度都是32位。
-1在计算机中是以1000 0000 0000 0000 0000 0000 0000 0001的补码形式1111 1111 1111 1111 1111 1111 1111 1111存储的,直接打印无符号数值就会把无符号补码形式打印出来,也是就是十进制的4294967295。无符号数2147483648在计算机中以1000 0000 0000 0000 0000 0000 0000 0000存储,转换为有符号补码形式是1111 1111 1111 1111 1111 1111 1111 1111,补码转换成有符号数是2147483647-4294967295=-2147483648。
明白转换原理后,我们可以采用便捷一点的记忆方法:
补码转换为无符号数:
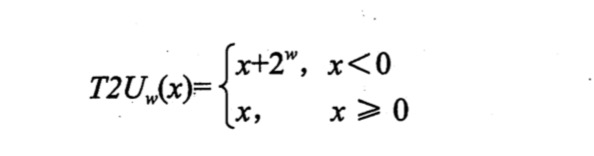
无符号数转换为补码:

如果一个表达式中同时出现int和unsigned int,C编译器会将带符号整数强制转换为无符号整数,也就是从-1到4294967295的过程。
比如:2147483647U和-2147483647-1比较大小,可以看到2147483647U是一个无符号整数,所以要把-2147483647-1转换成无符号整数2147483648,所以最终结果2147483647U < -2147483647-1。
4. 浮点数
介绍完定点数,下面我们来看看浮点数在计算机中是如何存储的:

以32位浮点数格式举例:
第0位数符S。第1-8位为8位移码表示阶码E(偏置常数为128);第9~31位为24位二进制原码小数表示的尾数M。
规格化尾数的小数点后第一位总是1,故规定第一位默认的“1”不表示出来。这样可用23个数位表示24位的尾数。
下面我们看一个书上的例子,8位的浮点格式:其中k=4的阶码位,n=3的小数位。
首先计算阶码偏置量
Bias=2^(k-1)-1=2^(4-1)-1=2^3-1=7
下面给出一个总的计算过程:
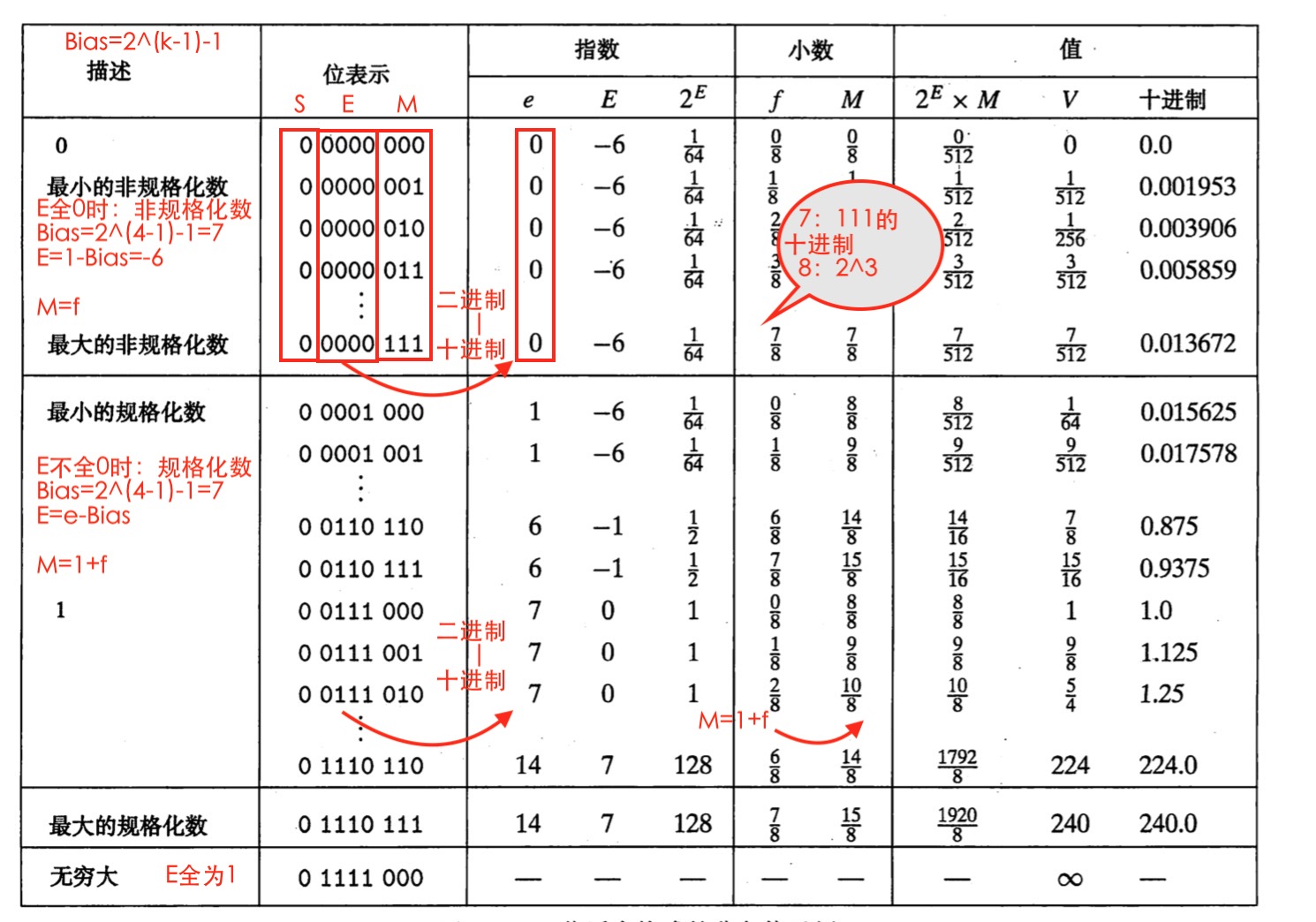
为大家举两个例子:
非规格化数0 0000 011:
指数部分:
e=[0000]=0
E=1-Bias=1-7=-6
2^E=2^(-6)=1/64
小数部分:
f=[011]/(2^3)=3/8
M=f=3/8
值:
2^E * M=1/64*3/8=3/512
十进制:0.005859
规格化数0 0111 010:
指数部分:
e=[0111]=7
E=e-Bias=7-7=0
2^E=2^0=1
小数部分:
f=[010]/(2^3)=2/8
M=1+f=10/8
值:
2^E * M=1*10/8=10/8
十进制:1.25
四、数值运算
看完计算机数的三个大头无符号整数、有符号整数和浮点数之后,我们来了解一下他们的运算是如何实现的。
1. 无符号整数运算
-
无符号整数的加法:
考虑两个无符号整数x,y,且0<x,y<2w(x和y都能表示成w位的无符号整数)。但如果计算x+y的值,所得结果是有可能大于2w的,也就是我们常说的溢出情况。
当发生溢出情况时,我们所采取的处理办法是:简单丢弃所溢出的最高位,所得到的结果是x+y mod 2^w。
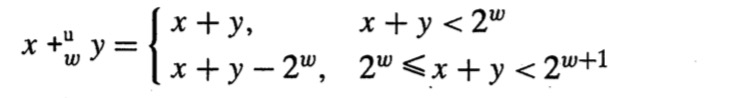
-
无符号整数的乘法:
两个无符号整数x,y,且0<x,y<2w。但如果计算x*y的值,所得结果0<x*y<(2w-1)^2之间,这个结果至少需要2w位来表示。C语言中的无符号乘法被定义为产生w位的值,实际上也是x*y mod 2^w。
在大多数机器上,整数乘法指令相当慢,需要10个或更多的时钟周期,而加法、减法、位级运算和移位运算只需要1个时钟周期。因此,编译器尝试用移位和加法运算的组合来代替乘法运算。
先来看一个特殊的乘法:
当x,y中有一个数为2的幂,比如说x=11=[1011],y=4=2^2。我们发现,令[1011]左移两位得到一个6位的结果(末尾补0)(x << 2):[101100],这个数是44=11*4。
原理是这样的:
11=[1011]=1*2^3+1*2^1+1*2^0=2^3+2^1+1
11*4=(2^3+2^1+1)*2^2=2^5+2^3+2^2=[101100]
那么当y不是4这样的很“顺眼”的数,而是一个普普通通的比如说5,7这样的数,我们该怎么处理呢?
很简单,5=4+1=2^2+2^0,x * 5可以表达为(x << 2) + (x << 0)=[101100]+[001011]=[110111]=55。还有一种方法,比如说y=31=2^5-1,编译器在处理x*y时会处理成(x << 5) - (x << 0)。
- 无符号整数的除法
既然乘法可以用移位和加减法来替代,是不是除法也可以呢?
我们先明确一个概念:整数除法总是舍入到零,我们这里采用的舍入是向下取整。我们拿一个稍微大一点的数x=12340举例:
x=12340=[0011 0000 0011 0100]
x/2=(x >> 1)=[0001 1000 0001 1010]=12340/2=6170
x/16=(x >> 4)=[0000 0011 0000 0011]=771,而12340/16=771.25,771就是向下取整的结果了。
2. 补码运算
看完无符号运算,下面我们来看看补码运算是如何处理的:
- 补码加法
对于-2(w-1)<=x,y<=2(w-1),他们的和-2w<=x+y<=2w-2之间,我们还是通过截断到w位来表示运算结果。
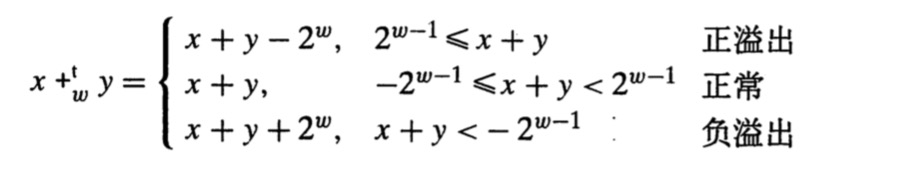
无论是正溢出还是负溢出,得到的运算结果都是(x+y) mod 2^w

-
补码的乘法:
范围在-2^(w-1)<=x,y<=2^(w-1)-1的整数x,y,他们的乘积-2^(w-1)*(2^(w-1)-1)<=x*y<=-2^(w-1)*(-2^(w-1))之间,同样的,C语言中的有符号乘法通过将2w位的乘积截断为w位来实现的。我们的计算方法是:先计算该值x*y mod 2^w,再把无符号转换为补码。
若想把补码的乘法运算也转换成加法和移位运算的结合,参考无符号数的转换过程,注意补码和无符号数之间的转换。

-
补码的除法:
对于补码的除法右移,应该使用算术右移而不是逻辑右移,不过算术右移也会有个问题,就是结果是向下取整的,比如-12340/16=-771.25,但结果是-772。想要使得向上取整,我们可以在执行算术右移之前加上一个适当的偏置量。
其中Bias=2^k-1。

五、计算机中的信息存储
计算机和编译器支持多种不同方式的编码数字格式,如不同长度的整数和浮点数。
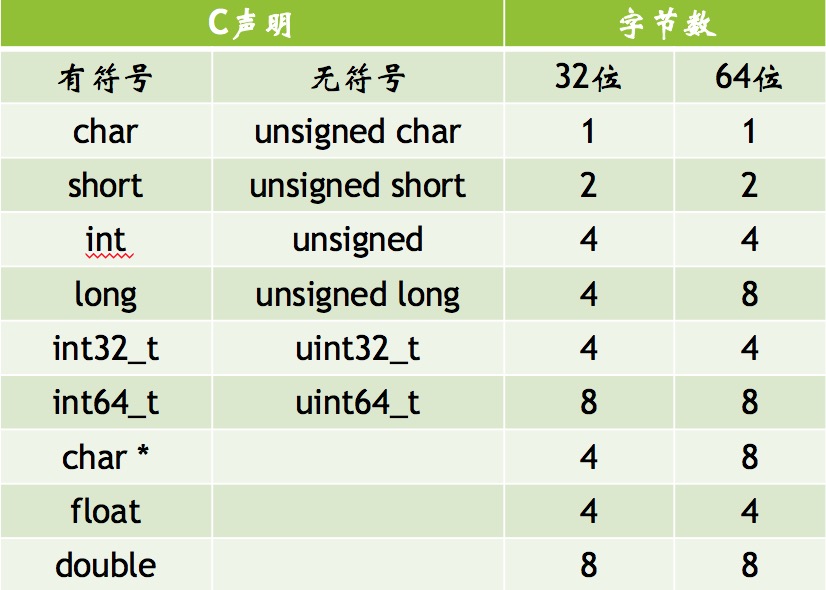
对于跨越多字节的程序对象,必须明确这个对象的地址是什么,以及在内存中如何排列。
排列表示一个对象的字节有两个通用的规则。一个w位的整数,其位表示为[xw-1,xw-2,…,x1,x0]。假设w是8的倍数,这些位就能被份组成字节,最高有效字节包含位[xw-1,xw-2,…,xw-7],最低有效字节包含位[x7,…,x0].
某些机器选择在内存中按照从最低到最高有效字节的顺序存储对象(小端法),而另一些机器则按照从最高到最低有效字节的顺序存储(大端法)。
假设变量x的类型为int,十六进制值为0x01234567,位于地址0x100处,地址范围0x100 ~ 0x103的字节顺序依赖于机器的类型。

目前大部分机器都采用的是小端法存储。
那么有没有办法可以看一下自己的电脑到底是大端法还是小端法呢?当然,只要能够看出数据在存储是逆序还是顺序的就OK啦!
我们给出一段程序示例:
#include <stdio.h>
int main(int argc, const char * argv[]) {
union NUM{
int a;
char b;
}num;
num.a=0x01234567;
if(num.b==0x01)
printf("该机器是大端!
");
else
printf("该机器是小端!
");
}
这段代码在我的电脑上运行结果是

可以看到,num.b是0x01而不是0x67,所以该机器是小端机器。
小结:
计算机将所有的信息按位编码成字节序列,整数、浮点数和字符串的编码方式是不同的。目前大多数机器使用的是32位字长的编码,大多数机器对整数使用补码编码,对浮点数使用IEEE编码;理解这些编码是怎么来的、这些编码如何转换(比如C语言中对有符号整数和无符号整数之间的转换),还有这些数值之间的加减乘除运算是很重要的一关。掌握了全部内容,才能对数值有更深的理解,也能够为后续的学习打下良好的基础。
以上就是我学习教材第二章中的全部内容,如果有什么问题欢迎指出,一起讨论一起学习~