简介
提升树与adaboost类似,也是boosting算法,它同样基于如下两点进行构建:
(1)训练方法:前向分步算法,根据前面树的结果对当前树进行调整训练,以提高精度
(2)组合方法:基于树的加法模型,可以表示如下:
这里,\(T(x,w_m)\)表示决策树,\(w_m\)为决策树的参数,\(M\)为树的个数,训练的前向分步算法可以表述如下:
(1)假设初始提升树\(f_0(x)=0\)
(2) 对\(m=1,2,...,M\):
(2.1) 根据定义,有:
(2.2) 这里\(f_{m-1}(x)\)表示上一轮已经训练好的模型,当前轮训练目标是通过使某损失函数极小化,求得当前决策树的最优参数:
(3)得到最终的组合模型:
从流程上,我们可以发现提升树与adaboost的最大不同:
(1)adaboost关注于错分的点,下一轮的目标更倾向于使错分的点得到矫正;
(2)而提升树关注于当前模型离目标的差距,下一轮模型的训练目的是去缩小与目标之间的差异
简单来说,它的流程可以表示如下:
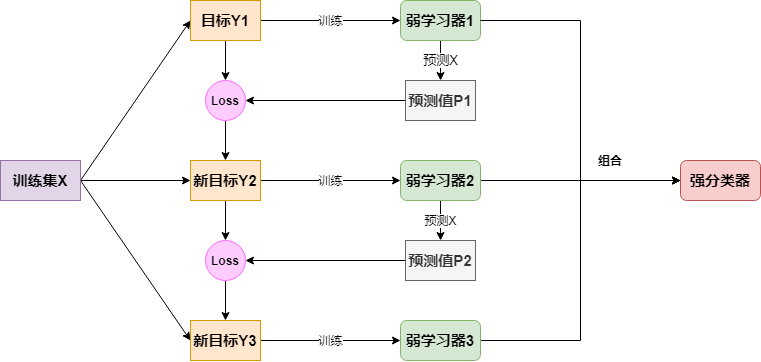
其实针对不同问题,其最大的不同是损失函数,接下来简单介绍损失函数为平方损失的回归提升树以及损失函数为指数的分类提升树:
回归提升树的前向分步算法
由于误差为平方损失,所以:
所以对于第\(m\)步更新,其损失函数:
由于\(y_i,f_{m-1}(x_i)\)均为已知量,所以使得下面等式成立的\(w_m\)便是最优参数:
所以对于第\(m\)步的训练,只需要将残差\(y-f_{m-1}(x)\)作为模型\(T(x,w_m)\)的\(y\)目标即可
分类提升树的前向分步算法
分类问题若使用如下的指数损失函数,其实就等价于上一节使用二叉树的adaboost算法:
接下来简单做个证明,由上一节的内容,知道,对于第\(m\)步:
所以:
这里,\(R_{mi}=exp(-y_if_{m-1}(x_i))\),接下来证明adaboost算法所得到的即是\(\alpha_m^*\)和\(G_m^*(x)\)
首先求\(G_m^*(x)\),对任意\(\alpha>0\),使上式成立的最小\(G_m(x)\)可以等价于:
这里\(R_{mi}\)与adaboost中的\(w_{mi}\)是成正比的,由adaboost中样本权重的迭代公式:\(w_{m+1}=\frac{w_{mi}}{Z_m}exp(-\alpha_my_iG_m(x_i))\),可以推出:
所以这里\(G_m^*(x)\)即是adaboost中求得的\(G_m(x)\),接下来看\(\alpha_m^*\):
对\(\alpha_m\)求导使其为0,可以求得:
对于更一般的损失函数如何更新?
前面介绍的两个损失函数都比较好操作,能很便捷的嵌入到每一步基模型的训练上,但对于更加一般的损失函数该如何处理呢?比如回归树的损失如果是绝对值\(L(y,f(x))=\mid y-f(x)\mid\),又该如何更新?显然这时的更新目标不再是残差了。其实,处理方法我们一直都在使用,那就是损失函数关于模型的负梯度,即:
则便是梯度提升树,上面的两个特例其实本质也是使用的梯度下降法:
(1)对于回归树有:
(2)对于分类树的情况,稍有些不同,它是对梯度下降法的近似,接下来简单说明下,对损失函数做一阶泰勒展开,可以表示如下为:
所以要使得损失函数下降,只要\(y_i\)与\(\Delta f(x_i)\)同号即可,而\(\Delta f(x_i)\)即是我们上面所求的\(\alpha_mG_m(x_i)\),这里\(\alpha_m>0\),而:
所以,\(G_m(x)\)的训练目标不仅仅是让损失函数下降,而且要让它下降的尽可能的多