八爪鱼 爬取微博中的图片到本地
批量爬取大量的好看的图片 到自己的本地电脑 哈哈哈哈哈哈
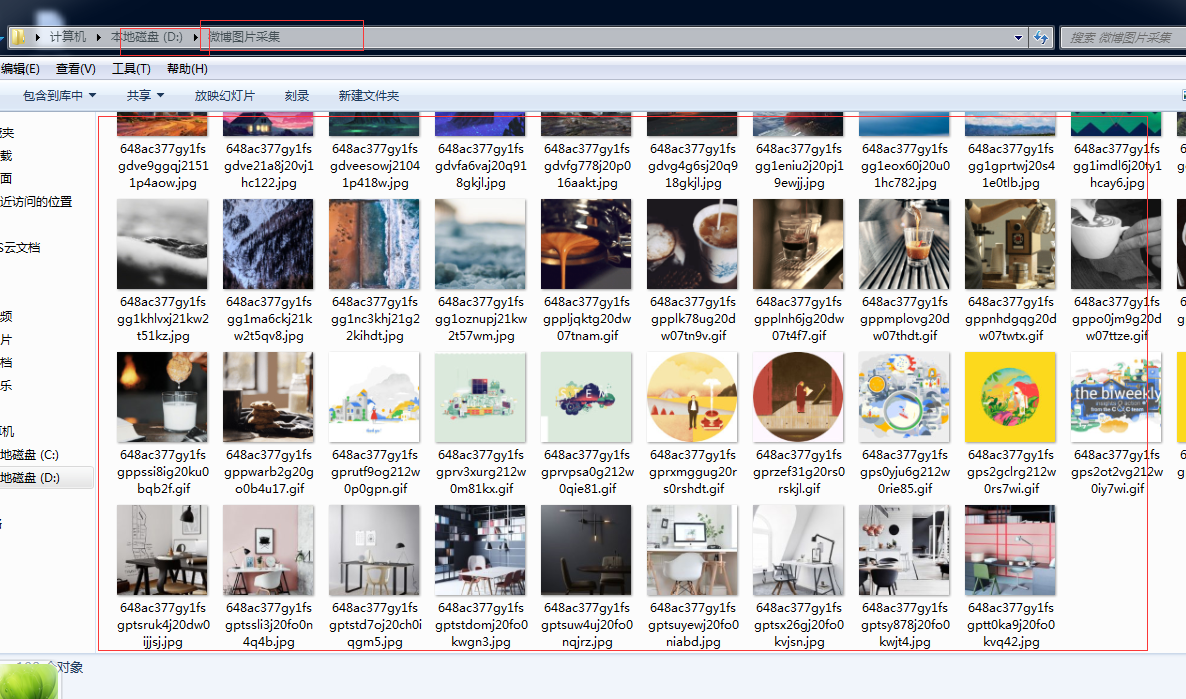
抓取的微博图片

详细步骤:http://www.bazhuayu.com/tutorial/wbpiccj
微博图片采集
本文介绍使用八爪鱼采集微博图片的方法。
微博上有很多博主,会发布很多高质量的图片。很多时候,我们想把这些高质量的图片保存下来,怎么办,一张一张另存为?使用八爪鱼采集器,只需做好规则,即可全自动地将我们的想要的图片采集下来。主要经过两大步:先将图片URL采集下来;再通过八爪鱼提供的图片批量下载工具,将URL批量转化为图片。
采集网站:
https://weibo.com/mdabao?refer_flag=1001030101_&is_all=1#_rnd1516333013843
本文仅以采集某博主的发布的图片为例。在实际操作过程中,大家可根据需要,更换要采集的博主。还可使用URL列表循环,批量采集多个微博博主发布的全部图片。本文采集的微博图片,具体字段为:博主ID、发博时间、微博URL、微博发送方式、微博内容、图片地址、图片保存文件夹。
在开始之前,请大家注意,如果没有在八爪鱼中登录过,需先建立一个登录流程。微博登录教程请参考:
http://mp.weixin.qq.com/s/n9-wRnC5GqcBfi2KOfOs6g
使用功能点:
l AJAX滚动教程
步骤1:创建微博图片采集任务
1)进入主界面,选择“自定义模式”,点击“立即使用”
2)将要采集的网址复制粘贴到网站输入框中,点击“保存网址”
步骤2:创建翻页循环
1)系统自动打开网页,进入微博。观察网页结构,当把页面下拉至底部的时候,会出现“正在加载中,请稍后”的字样,随着我们的下拉,页面会有新的数据加载出来。经过2次下拉加载,此页面达到最底部,出现“下一页”按钮
此网页涉及Ajax下拉加载,需要对其进行一些高级选项的设置。打开“高级选项”,勾选“页面加载完成后向下滚动”,设置滚动次数为“3次”,每次间隔“3秒”,滚动方式为“直接滚动到底部”,最后点击“确定”
注意: 这里的滚动次数及间隔时间,需要针对网站情况进行设置,并不是绝对的。一般情况下,间隔时间>网站加载时间即可。有时候网速较慢,网页加载很慢,还需根据具体情况进行调整。
具体请看:八爪鱼7.0教程——AJAX滚动教程
2)将页面下拉到底部,点击“下一页”按钮,在右侧的操作提示框中,选择“循环点击下一页”
与“打开网页”类似,此步骤同样涉及Ajax下拉加载。打开“高级选项”,勾选“页面加载完成后向下滚动”,设置滚动次数为“次”,每次间隔“3秒”,滚动方式为“直接滚动到底部”,最后点击“确定”
注意事项同上
步骤3:创建列表循环
1)移动鼠标,选中页面里的第一条微博链接。选中后,系统会自动识别页面里的其他相似链接。在右侧操作提示框中,选择“选中全部”
2)选择“循环点击每个链接”,以创建一个列表循环
步骤4:提取微博文本和图片
1)系统会自动点击进入第一条微博的详情页。微博详情页中,我们首先采集博主ID、发博时间、微博内容、微博URL、微博发送方式。点击要采集的字段,在右侧的操作提示框中,选择“采集该元素的文本”(采集微博URL,则选择“采集该链接地址”)
2)字段信息选择完成后,选中相应的字段,可以进行字段的自定义命名。完成后,点击“确定”
3)点击页面中第一张图片,在操作提示框中,选择“选中全部”
4)选择“循环点击每个图片”
由于此网页涉及Ajax技术,我们需要进行一些高级选项的设置。选中“点击元素”步骤,打开“高级选项”,勾选“Ajax加载数据”,设置时间为“2秒”
注:AJAX即延时加载、异步更新的一种脚本技术,通过在后台与服务器进行少量数据交换,可以在不重新加载整个网页的情况下,对网页的某部分进行更新。
表现特征:a、点击网页中某个选项时,大部分网站的网址不会改变;b、网页不是完全加载,只是局部进行了数据加载,有所变化。
验证方式:点击操作后,在浏览器中,网址输入栏不会出现加载中的状态或者转圈状态。
5)点击第一张图片,在弹出的操作提示框中,选择“采集该图片的地址”。图片的地址已经被采集下来,将此字段修改为“图片地址”
6)接下来为将图片URL批量导出为图片做准备。点击“添加特殊字段”,选择“添加固定字段”,输入“D:微博图片采集”,其中“D:\”为图片存储盘,“微博图片采集”为图片保存文件夹名
步骤5:数据采集及导出
1)点击左上角的“开始采集”,选择启动“本地采集”
注:本地采集占用当前电脑资源进行采集,如果存在采集时间要求或当前电脑无法长时间进行采集可以使用云采集功能,云采集在网络中进行采集,无需当前电脑支持,电脑可以关机,可以设置多个云节点分摊任务,10个节点相当于10台电脑分配任务帮你采集,速度降低为原来的十分之一;采集到的数据可以在云上保存三个月,可以随时进行导出操作。
2)采集完成后,会跳出提示,选择“导出数据”。选择“合适的导出方式”,将采集好微博发博数据导出,这里我们选择excel作为导出为格式
3)数据导出后如下图所示
步骤6:将图片URL批量转换为图片
经过如上操作,我们已经得到了要采集的图片的URL。接下来,再通过八爪鱼专用的图片批量下载工具,将采集到的图片URL中的图片,下载并保存到本地电脑中。
图片批量下载工具:https://pan.baidu.com/s/1c2n60NI
1)下载八爪鱼图片批量下载工具,双击文件中的MyDownloader.app.exe文件,打开软件
2)打开File菜单,选择从EXCEL导入(目前只支持EXCEL格式文件)
3)进行相关设置,设置完成后,点击OK即可导入文件
选择EXCEL文件:导入你需要下载图片地址的EXCEL文件
EXCEL表名:对应数据表的名称
文件URL列名:表内对应URL的列名称
保存文件夹名:EXCEL中需要单独一个列,列出图片想要保存到文件夹的路径,可以设置不同图片存放至不同文件夹
如果要把文件保存到文件夹,则路径需要以“”结尾,例如:“D:同步”,如果要下载后按照指定的文件名保存,则需要包含具体的文件名,例如“D:同步1.jpg”
如果下载的文件路径和文件名完全一样,则原先存在的文件会被删除
3)点击OK后,界面如图所示,再点击“开始下载”
4)页面下方会显示图片下载状态
5)找到自己设定的图片保存文件夹,可以看到,图片URL已经批量转换为图片了
注意 :必须安装软件 不然就会报错的啦 (自己试了很长时间才搞对的)
之后就可以导出到本地啦

本地位置: