近期在做kafka metrics. 参考了几个开源的项目,诸如kafka manager, Burrow, kafkaOffsetMonitor,东西都很不错,可惜没有一个是用java编写的,最终自己去仿照kafka源码写了个java版的adminclient,拿到了自己需要的metrics数据。这个功能开发完,也对kafka有了些许的了解。遂记录如下。
基本概念:
producer:数据发送方。producer可以把消息以K-V的格式发送到某个topic。K是任意的表示,可string,可int;V可string,可byte[]。
consumer:数据接收方,或使用方。一个consumer可订阅一个或多个topic。每个consumer都属于一个consumer group.
group:某一类consumer的集合,有一个groupId,一个group中可以有多个consumer,发送到topic中的消息,只会被一个group中的某一个consumer消费。
Topic:一类消息的总称。Topic可以被分成多个partition存放在kafka集群的不同server上。发到topic中的数据以append的形式存储在log文件中,每条数据有一个唯一标示(offset)。
Partition:实际存储data的分区。一个topic的数据可以分布在多个分区,每个分区也可以定义备份的个数。每个分区有一个leader partition,在别的broker上有对应的多个follow partitions。Topic只从leader partition消费消息。当leader partition坏掉之后,kafka会自动从follow partitions中选出重新选出一个leader partition。
logSize:某个parition上log的总长度。
offset:数据在parition中的偏移量。这个offset不是该数据在partition文件中的实际偏移量,而是一个逻辑值用于确定一条message数据。比如有100条数据,offset为0~99,根据数据内容的大小,物理上可能分成5个segment文件,offset分别为0~15,16~20,21~55,55~80,81~99,每个segment的名字以最小offset命名,分别为0,16,21,55,81,这样根据某个offset定位数据的时候,就比较容易了。为了进一步方便定位,kafka还为每个segment建立了index,index包含两个部分:offset和position,position代表数据再segment文件中的绝对位置。
Lags: logSize - currentOffset.
kafka使用方式:
kafka可以有多种使用方法,比如作为常规的message bus, log日志集中通道,网站访问信息收集通道等等。特殊一点的,可以作为一个分布式的多线程库,消息分发到同一个group的不同的consumer上,进行并行处理。
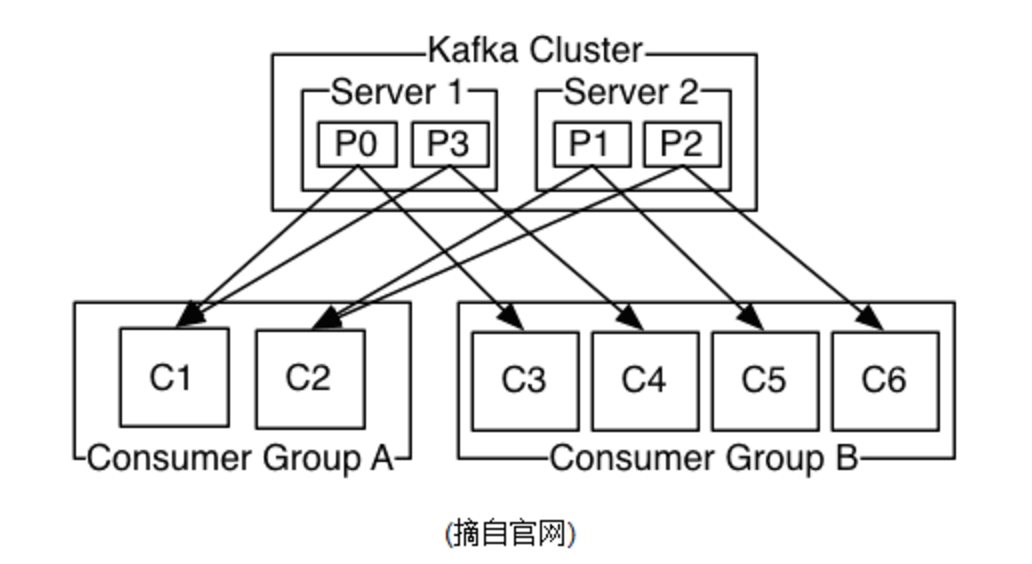
kafka工作机制
kafka的消息传送机制:
- at most once: 消费者fetch消息,然后保存offset,然后处理消息。当client保存offset之后,但是在消息处理过程中出现了异常,导致部分消息未能继续处理.那么此后”未处理”的消息将不能被fetch到。
- at least once: 消费者fetch消息,然后处理消息,然后保存offset。如果消息处理成功之后,但是在保存offset阶段zookeeper异常导致保存操作未能执行成功,这就导致接下来再次fetch时可能获得上次已经处理过的消息。
通常情况下,选用at least once。
Kafka复制备份机制:
kafka把每个parition的消息复制到多个broker上,任何一个parition都有一个leader和多个follow,备份个数可以在创建topic的时候指定。leader负责处理所有read/write请求,follower像consumer一样从leader接收消息并把消息存储在log文件中。leader还负责跟踪所有的follower状态,如果follower“落后”太多或失效,leader将会把它从replicas同步列表中删除。当所有的follower都将一条消息保存成功,此消息才被认为是“committed”。
Kafka与Zookeeper的交互机制:
当一个kafka broker启动后,会向zookeeper注册自己的节点信息,当broker和zookeeper断开链接时,zookeeper也会删除该节点的信息。除了自身的信息,broker也会向zookeeper注册自己持有的topic和partitions信息。
当一个consumer被创建时,会向zookeeper注册自己的信息,此作用主要是为了“负载均衡”。一个group中的多个consumer可以交错的消费一个topic的所有partitions。简而言之,保证此topic的所有partitions都能被此group所消费,且消费时为了性能的考虑,让partition相对均衡的分撒到每个consumer上。每一个consumer都有一个唯一的ID(host:uuid,可以通过配置文件指定,也可以由系统生成),此ID用来标记消费者信息,主要是topic+partition信息。
Producer端使用zookeeper用来”发现”broker列表,以及和Topic下每个partition leader建立socket连接并发送消息。
zookeeper上还存放partition被哪个consumer所消费的信息,以及每个consumer目前所消费的partition中的最大offset。
在kafka 0.9版本之后,kafka为了减少与zookeeper的交互,减少network data transfer,也自己实现了在kafka server上存储consumer,topic,partitions,offset信息。
kafka metrics:
对kafka的metrics主要是对lags的分析,lags是topic/partition的logSize与consumer消费到的offset之间的差值,即producer产生数据的量与consumer消费数据的量的差值,差值越来越大,说明消费数据的速度小于产生数据的速度。一般可以认定是consumer出了问题。当然也不能只看某一点的lags大小,更重要的是关注lags的变化的趋势,当趋势越来越大时,可推断consumer的performance越来越差。
在kafka 0.8.1版本之后,可以通过配置选择把topic/partition的logsize,offset等信息存储在zookeeper上或存储在kafka server上。在做metrics时,注意可能需要分别从两边获取数据。
获取zookeeper上的kafka数据比较简单,可以通过SimpleConsumer配合zookeeper.getChildren方法获取consumerGroup, topic, paritions信息,然后通过SimpleConsumer的getOffsetsBefore方法获取logSize,fetchOffsets获取topic parition的currentOffsets。
获取kafka server上的数据比较麻烦,目前kafka 0.10提供的kafkaConsumer类主要还是关注topic消费,对consumerGroup及Group和topic关系的获取,还没有提供API。不过我们知道可以通过kafka-consumer-groups.sh得到group,topic等信息的,这个shell文件里面调用了kafka.admin.ConsumerGroupCommand类,这个类确实提供了一个listGroup方法,可惜这个方法的返回值是void,shell文件的输出是打印到控制台的,并没有返回值。再去研究ConsumerGroupCommand是怎么拿到group的,发现它通过AdminClient对象的listAllConsumerGroup获取的group list,所以只要new出来一个AdminClient就能解决问题。
Java实现AdminClient(for kafka 0.9)
private static AdminClient getAdminClient(){ if(null != adminClient){ return adminClient; }else{ Time time = new SystemTime(); Metrics metrics = new Metrics(time); Metadata metadata = new Metadata(); ConfigDef configs = new ConfigDef(); configs.define( CommonClientConfigs.BOOTSTRAP_SERVERS_CONFIG, Type.LIST, Importance.HIGH, CommonClientConfigs.BOOSTRAP_SERVERS_DOC) .define( CommonClientConfigs.SECURITY_PROTOCOL_CONFIG, ConfigDef.Type.STRING, CommonClientConfigs.DEFAULT_SECURITY_PROTOCOL, ConfigDef.Importance.MEDIUM, CommonClientConfigs.SECURITY_PROTOCOL_DOC) .withClientSslSupport() .withClientSaslSupport(); HashMap<String, String> originals = new HashMap<String, String>(); originals.put(CommonClientConfigs.BOOTSTRAP_SERVERS_CONFIG, KAFKA_METRICS_BOOTSTRAP_SERVERS); AbstractConfig abstractConfig = new AbstractConfig(configs, originals); ChannelBuilder channelBuilder = org.apache.kafka.clients.ClientUtils.createChannelBuilder(abstractConfig.values()); List<String> brokerUrls = abstractConfig.getList(CommonClientConfigs.BOOTSTRAP_SERVERS_CONFIG); List<InetSocketAddress> brokerAddresses = org.apache.kafka.clients.ClientUtils.parseAndValidateAddresses(brokerUrls); Cluster bootstrapCluster = Cluster.bootstrap(brokerAddresses); metadata.update(bootstrapCluster, 0); Long DefaultConnectionMaxIdleMs = 9 * 60 * 1000L; int DefaultRequestTimeoutMs = 5000; int DefaultMaxInFlightRequestsPerConnection = 100; Long DefaultReconnectBackoffMs = 50L; int DefaultSendBufferBytes = 128 * 1024; int DefaultReceiveBufferBytes = 32 * 1024; Long DefaultRetryBackoffMs = 100L; String metricGrpPrefix = "admin"; Map<String, String> metricTags = new LinkedHashMap<String, String>(); //Selector selector = new Selector(DefaultConnectionMaxIdleMs, metrics, time, metricGrpPrefix, channelBuilder); Selector selector = new Selector(DefaultConnectionMaxIdleMs, metrics, time, metricGrpPrefix, metricTags, channelBuilder); AtomicInteger AdminClientIdSequence = new AtomicInteger(1); NetworkClient client = new NetworkClient(selector, metadata, "admin-" + AdminClientIdSequence.getAndIncrement(), DefaultMaxInFlightRequestsPerConnection, DefaultReconnectBackoffMs, DefaultSendBufferBytes, DefaultReceiveBufferBytes, DefaultReceiveBufferBytes, time); ConsumerNetworkClient highLevelClient = new ConsumerNetworkClient(client, metadata, time, DefaultRetryBackoffMs); //ConsumerNetworkClient highLevelClient = new ConsumerNetworkClient(client, metadata, time, DefaultRetryBackoffMs, DefaultRequestTimeoutMs); scala.collection.immutable.List<Node> nList = scala.collection.JavaConverters.asScalaBufferConverter(bootstrapCluster.nodes()).asScala().toList(); adminClient = new AdminClient(time, DefaultRequestTimeoutMs, highLevelClient, nList); return adminClient; } }