在遍历list,删除符合条件的数据时,总是报异常,代码如下:
1 num_list = [1, 2, 3, 4, 5] 2 print(num_list) 3 4 for i in range(len(num_list)): 5 if num_list[i] == 2: 6 num_list.pop(i) 7 else: 8 print(num_list[i]) 9 10 print(num_list)
会报异常:IndexError: list index out of range
原因是在删除list中的元素后,list的实际长度变小了,但是循环次数没有减少,依然按照原来list的长度进行遍历,所以会造成索引溢出。
修改代码如下:
1 num_list = [1, 2, 3, 4, 5] 2 print(num_list) 3 4 for i in range(len(num_list)): 5 if i >= len(num_list): 6 break 7 8 if num_list[i] == 2: 9 num_list.pop(i) 10 else: 11 print(num_list[i]) 12 13 print(num_list)
这回不会报异常了,但是打印结果如下:
[1, 2, 3, 4, 5] 1 4 5 [1, 3, 4, 5]
虽然最后,list中的元素[2]确实被删除掉了,但是,在循环中的打印结果不对,少打印了[3]。
思考了下,知道了原因,当符合条件,删除元素[2]之后,后面的元素全部往前移,于是[3, 4, 5]向前移动,那么元素[3]的索引,就变成了之前[2]的索引(现在[3]的下标索引变为1了),后面的元素以此类推。可是,下一次for循环的时候,是从下标索引2开始的,于是,取出了元素[4],就把[3]漏掉了。
再次修改代码,结果一样,丝毫没有改观:
1 num_list = [1, 2, 3, 4, 5] 2 print(num_list) 3 4 for item in num_list: 5 if item == 2: 6 num_list.remove(item) 7 else: 8 print(item) 9 10 print(num_list)
找出问题的根本原因所在,想要找到正确的方法,也并不难,再次修改代码:
1 num_list = [1, 2, 3, 4, 5] 2 print(num_list) 3 4 i = 0 5 while i < len(num_list): 6 if num_list[i] == 2: 7 num_list.pop(i) 8 i -= 1 9 else: 10 print(num_list[i]) 11 12 i += 1 13 14 print(num_list)
执行结果,完全正确:
[1, 2, 3, 4, 5] 1 3 4 5 [1, 3, 4, 5]
我的做法是,既然用for循环不行,那就换个思路,用while循环来搞定。每次while循环的时候,都会去检查list的长度(i < len(num_list)),这样,就避免了索引溢出,然后,在符合条件,删除元素[2]之后,
手动把当前下标索引-1,以使下一次循环的时候,通过-1后的下标索引取出来的元素是[3],而不是略过[3]。
当然,这还不是最优解,所以,我搜索到了通用的解决方案:
1、倒序循环遍历;
2、遍历拷贝的list,操作原始的list。
1、倒序循环:
1 num_list = [1, 2, 3, 4, 5] 2 print(num_list) 3 4 for i in range(len(num_list)-1, -1, -1): 5 if num_list[i] == 2: 6 num_list.pop(i) 7 else: 8 print(num_list[i]) 9 10 print(num_list)
执行结果完全正确
解释正序循环时删除就有问题,而倒序循环时删除就ok
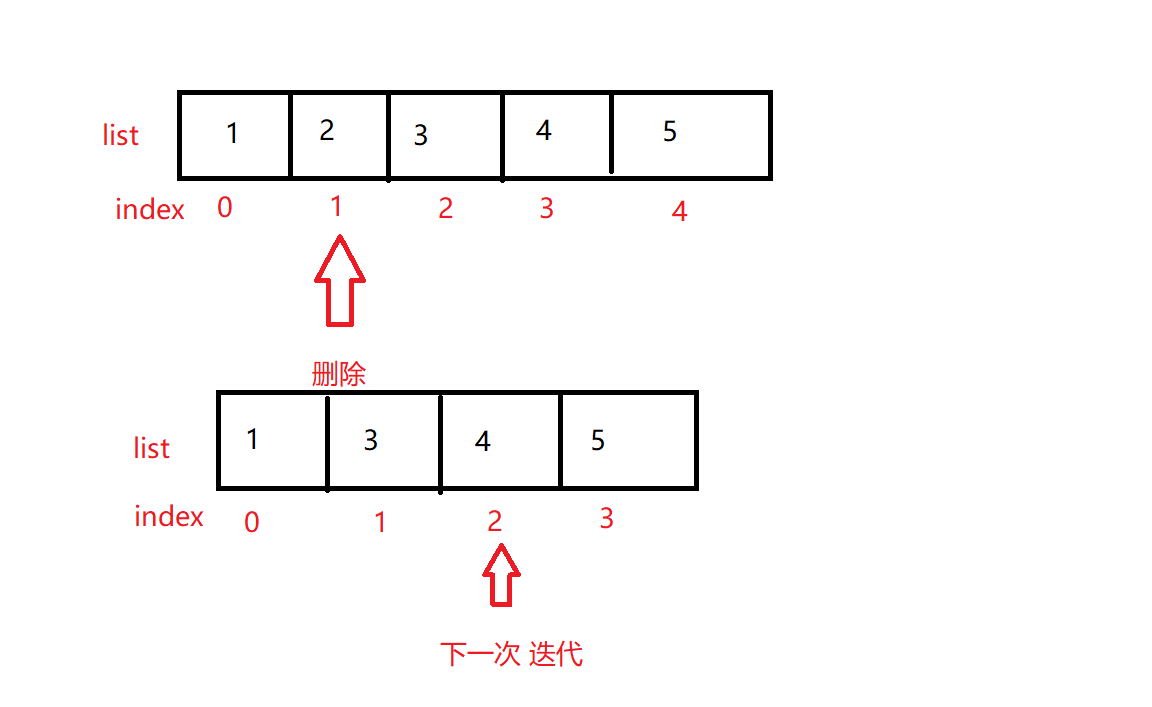
删除元素[2]之后,下一次循环的下标索引为2,但此时,里面存放的是[4],于是就把[3]给漏了。
2)倒序循环时删除

删除元素[2]后,[3, 4, 5]往前挤,但是没关系,因为下一次循环的下标索引为0,里面存放的是[1],所以正是我们所期望的正确的元素值。
2、遍历拷贝的list,操作原始的list
1 num_list = [1, 2, 3, 4, 5] 2 print(num_list) 3 4 for item in num_list[:]: 5 if item == 2: 6 num_list.remove(item) 7 else: 8 print(item) 9 10 print(num_list)
原始的list是num_list,那么其实,num_list[:]是对原始的num_list的一个拷贝,是一个新的list,所以,我们遍历新的list,而删除原始的list中的元素,则既不会引起索引溢出,最后又能够得到想要的最终结果。此方法的缺点可能是,对于过大的list,拷贝后可能很占内存。那么对于这种情况,可以用倒序遍历的方法来实现