我们可以写一段简单的c代码(code/memory/segment_1.c):
#include <stdio.h>
int main()
{
int a = 1;
printf("Hello, World!");
return 0;
}
然后将其转为汇编,运行:
gcc -S segment_1.c
之后会生成一个.s 文件(code/memory/segment_1.s),不用细看内容。
我们发现,这个汇编代码中,有 .string main .text,反正分为不同的块。
.file "segment_1.c"
.text
.section .rodata
.LC0:
.string "Hello, World!"
.text
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
subq $16, %rsp
movl $1, -4(%rbp)
leaq .LC0(%rip), %rdi
movl $0, %eax
call printf@PLT
movl $0, %eax
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size main, .-main
.ident "GCC: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0"
.section .note.GNU-stack,"",@progbits
进程在内存中,主要是按照这种形式进行存储的。

为什么要分段呢?
我们看上面那张图片,分为不同段,每个段的读写属性是不同的。比如正文段存储代码,就像我们上面的.s文件中的main部分。它在内存中是始终不变的,我们CPU就是从main中去取指执行。所以,它是只读的。
而其他部分,也许是可读可写的。
通过分段,可以对不同的属性代码、数据进行更方便的管理。如果是打乱的放在内存中,那么读写属性就很难控制。
所以通过分段机制,我们可以更好得控制不同段的属性,这有利于内存的组织安排。更多的好处,可以后面慢慢体会。
分段机制与间接寻址
因为现在引入了分段机制,所以如果我们想要访问某个地方的数据,指令,我们会引入间接寻址。
比如说,程序现在运行在代码段(CS),然后呢,他想要访问数据段的某个数据(DS),那么就可以使用 DS的基地址+偏移量,就可以访问到数据段中的数据了。
就像我们下图一样,如果我们运行到某一条指令,他需要 DS:1 的数据,那么我们可以通过数据段开始的地址0x100 加上偏移量1,就可以直接访问到 int a = 1 了。
所以,我们只需要知道不同段的开始地址加上偏移量,就可以访问不同段的内容。

分段机制与LDT表
我们前面说到,因为分段机制,所以,如果我们想要去访问某个段中的内容,我们需要获得每个段的基址。所以,我们需要一个结构去储存每个段的基址。这就是 LDT (本地描述表/local descriptor table) 表。
(名字,有点。。。,至少本地两字说明,这个表是局部的,对于每个进程,都有一个LDT表)。
LDT 表
现在来说说 LDT 表,之前说了分段的好处,那么我们应该怎么设计 LDT 表呢?
我们需要用一些位来表示:可读/可写状态,不同段的基址以及段的长度。
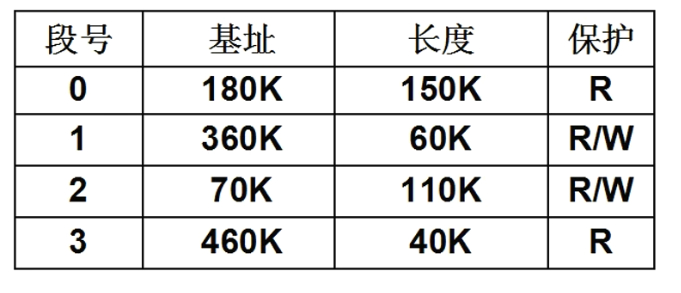
现在,我们可以通过每个进程的 LDT 表找到每个段所在的位置。
GDT 表
那么我们如何找到每个进程的 LDT 表呢?
这个,就轮到 GDT表了,与之前的 LDT 表,就差一个字母。G的意思,就是 global 全局的意思。
那意味着这张表,所有的进程都可以看到,进行访问。
在 GDT 表中,有着不同 LDT 表的地址。这里涉及到 LDTR寄存器,这个寄存器被赋值为 GDT表中的一个 LDT 表的位置,然后CPU 可以通过这个寄存器,找到对应的进程的 LDT表。
可以看下下图。

关于更多的 GDT 和 LDT 的介绍,可以看最后的参考部分。
分段机制与多进程
我们知道,CPU会采用某种策略,运行多个进程。这个时候,我们就需要保证不同的进程的内容,会存在不同的内存中,不能相互干扰。
这就要求,我们之前说的,每个进程都有一个 LDT表。可以将不同的进程内容映射到不同的内存地址。
总结
最后,就拿这张图来总结下吧,大家可以用这张图来回顾下前面的内容。

参考
《深入理解计算机系统》
- 7.9 加载可执行目标文件
《Linux 内核0.11完全注释》
- 4.3 分页机制(进阶)
操作系统(哈工大李治军老师)32讲(全)超清 P20 L20 内存使用与分段