
可以看到,我们的规范包括目录结构规范、git 分支规范、代码编写规范、开发规范、体验规范等等。

基于这些规范,项目初期,我们借助小程序开发者工具现有能力,再加上 gulp 的补充,形成了最初的开发模式。可以看到,gulp 的补充主要是 sass 的处理和打包文件的提取及压缩。以上规范和开发模式都是大家所常见的,那是不是有这些就够了?
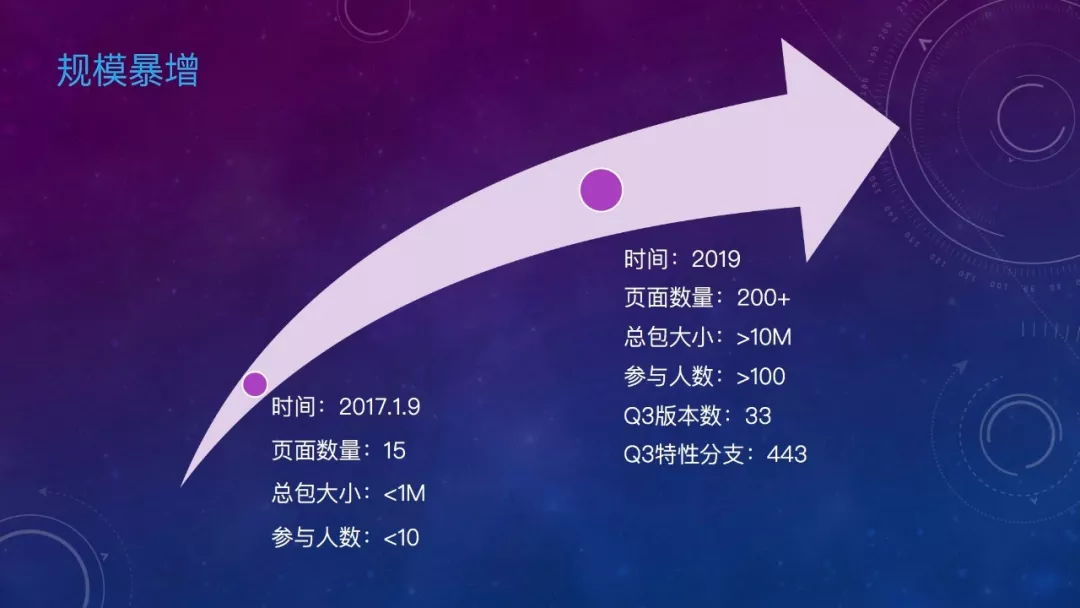
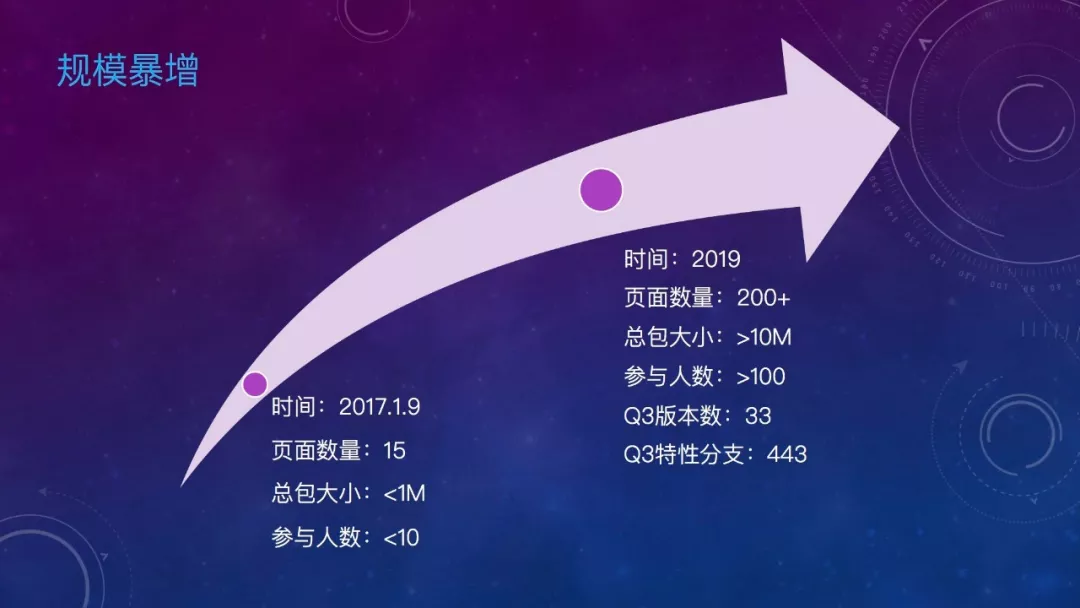
先看一组数据,2017年1月9号,随着微信宣布小程序上线,我们的京东购物小程序也发布了第一个版本。页面数量15个,总包小于1M,参与开发人员不到10人。而到今年,我们的小程序已经有超过200个页面。总包超过10M,参与人数超过100,平均一周2个版本。当初的小程序已长成了一个大程序。看看规模暴增后带来的问题。

可以看到,规模的暴增给开发、测试、打包、发布各个阶段都造成了问题。
开发阶段,开发者工具越来越卡,有时候想使用手机预览,等了2分钟,结果工具告诉我文件太多了,哎。另外一个问题就是出现了大量相同、相似代码,很难处理。
测试阶段,页面越来越多,很难覆盖全,有时候等到上线了才发现有个别页面功能有问题,只能重新发版。
打包阶段,第1个问题是代码包超限,这时不得不通过删代码或者调整业务的方式来处理,这是个很麻烦的事情。另一个问题是,我们有多个小程序,但代码很难复用。
发布阶段,流程繁琐,开发人员又比较多,导致效率低下。
先看看开发阶段调试越来越卡的问题
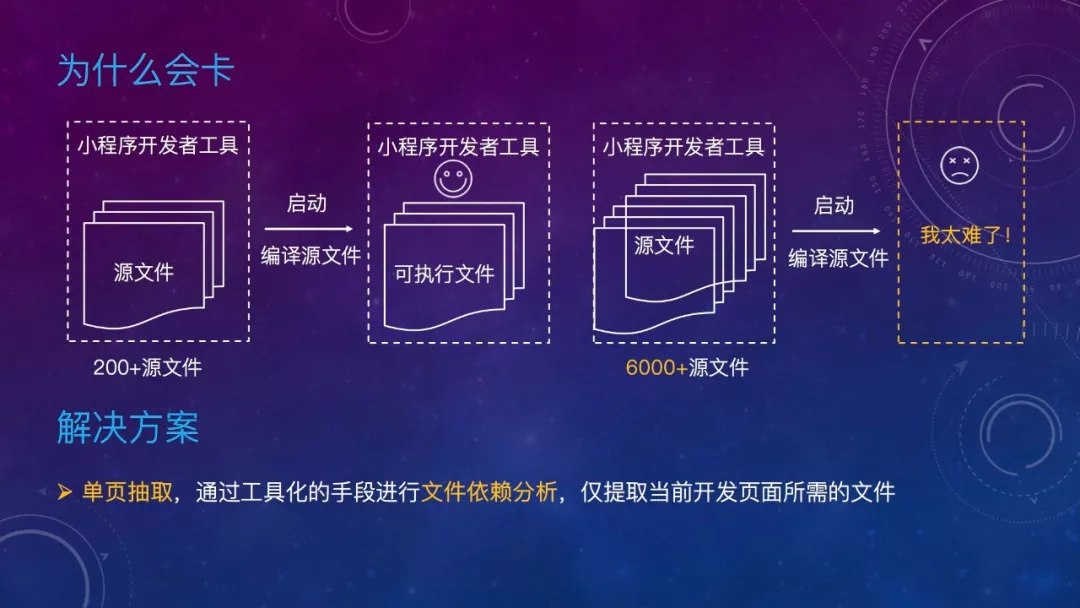
不管什么 IDE,什么语言,当项目过大,文件过多时,必然会卡,小程序开发者工具也同样存在这个问题,我们的小程序到现在已经有6000多个文件,这对 IDE 来说实在是太难了。
怎么办呢?其实我们平时业务开发往往只涉及到一两个页面,我能不能只加载这个页面相关的文件呢?答案是可以的,这个方案我们叫单页抽取,通过工具化的手段进行文件依赖分析,仅提取当前开发页面所需的文件。
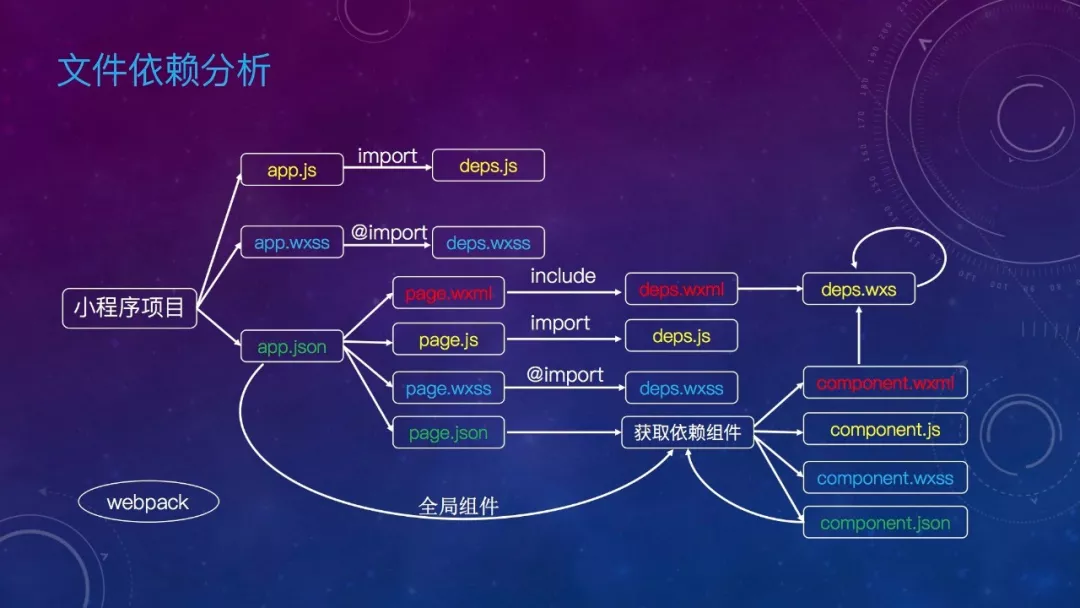
文件依赖分析如何做:可以看下这个图,app.json 里注册了小程序所有的页面路径,通过这个信息就可以拿到所有页面的文件依赖及组件的文件依赖。
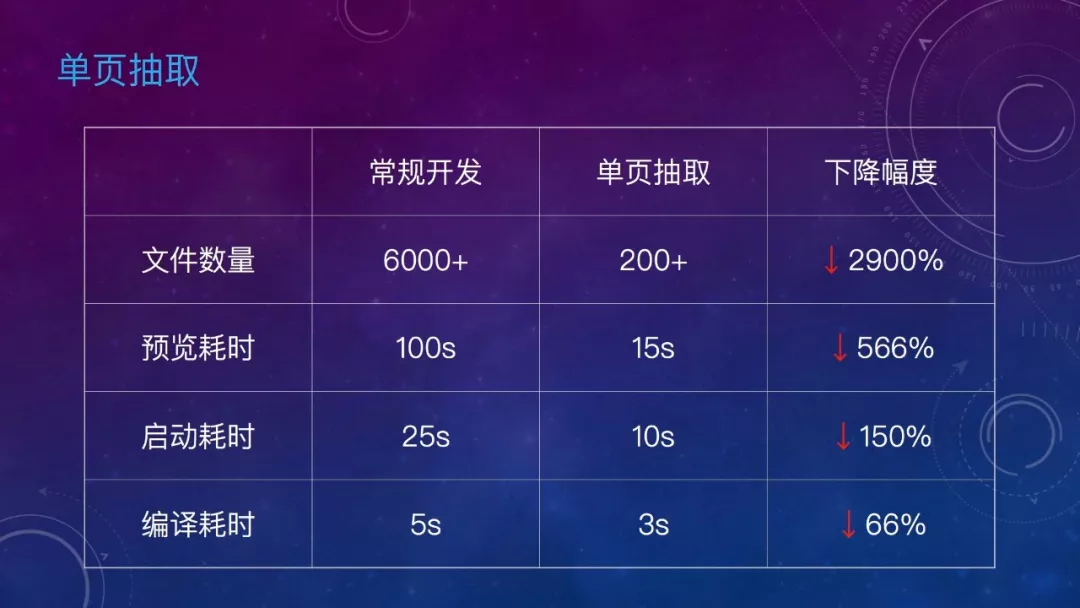
可以看到,通过单页抽取,加载的文件数量从6000多下降到200多,预览耗时从100s下降到15s,启动、编译等操作的耗时,都有很明显的下降。

好,开发调试卡的问题通过单页抽取解决了,接下来是大量相同、相似代码造成的冗余问题。
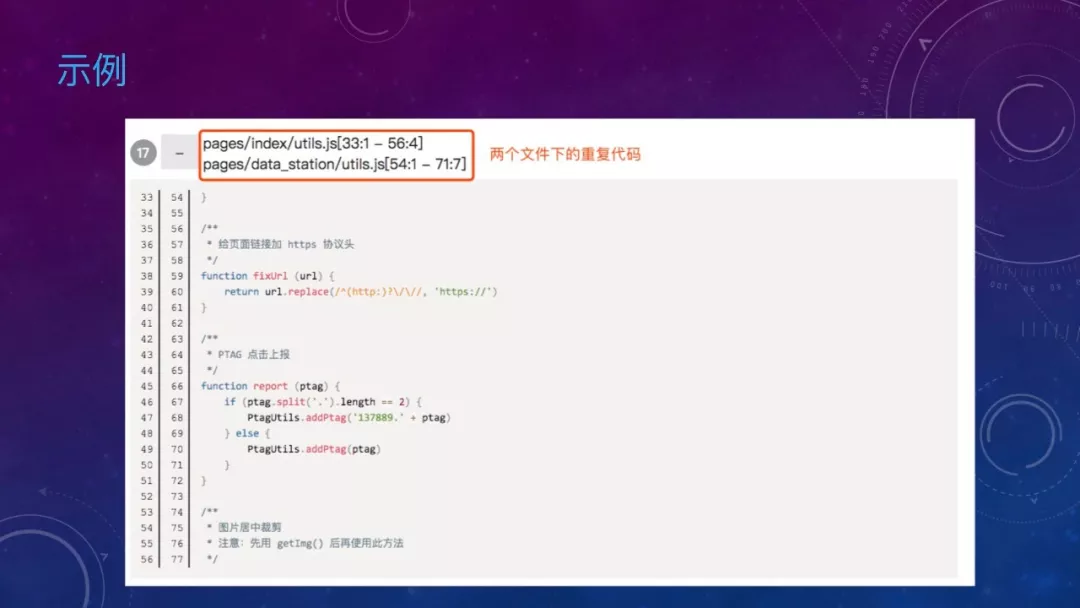
先看下例子,这是两个不同页面的文件,但是存在完全相同的两个函数,这显然是有问题的。

相同、相似代码形成的原因首先是复制粘贴,有相似功能的拷贝,也有跨小程序的拷贝。
然后是对项目不熟悉,新同学加入或业务交接等,会让开发人员面对一个全新的项目。这种陌生的情况下,许多开发人员就会产生重复造轮子的问题,只顾着自己开发的部分,完全没考虑到项目原先的代码状况。
这个怎么解决呢,一个是组件化,通过人工手段进行分析,提取 NPM 包,推动业务侧改造,减少重复代码。另一个是代码审计,通过工具化手段进行分析,给出建议,避免重复代码形成。
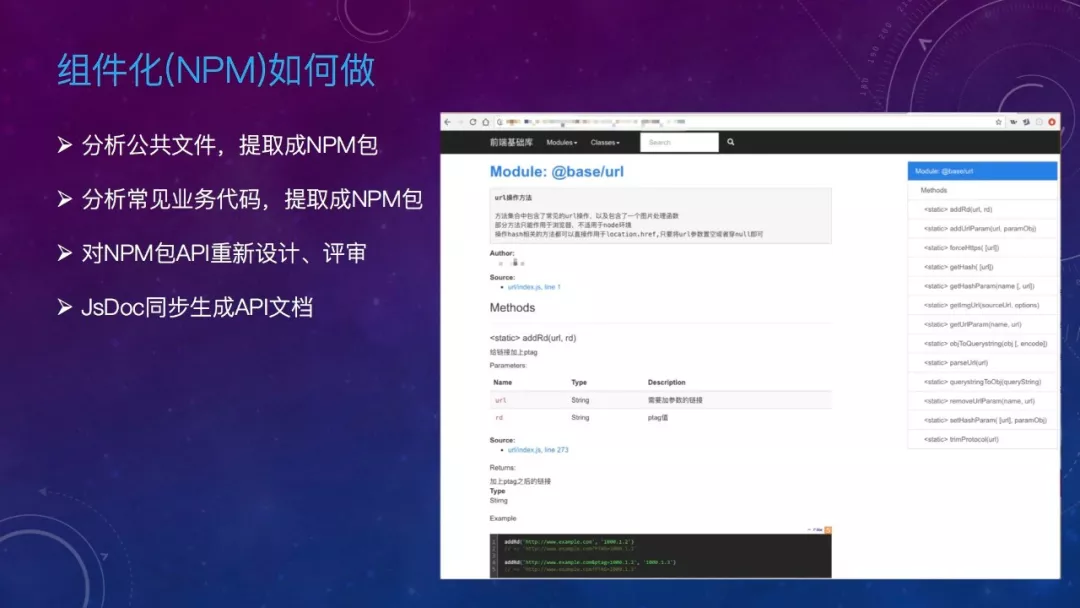
这里的组件化,其实是指 NPM 包的提取,怎么做呢,可以分析现有公共文件,分析常见业务代码,提取成 NPM 包。然后再对 NPM 包的 API重新设计、评审以保证它的合理性。最后使用 JsDoc 同步生成详细的 API 文档,推动业务侧改造。


也许有人会问为什么不一开始就使用 NPM,答案很简单,微信小程序初期并不支持,实际上他从基础库版本2.2.1开始支持 NPM,但到目前为止,我们小程序仍然有12.8%的用户低于此版本。这个问题可以在打包阶段处理,通过 CLI 将 NPM 包的引用修改为相对路径引用。
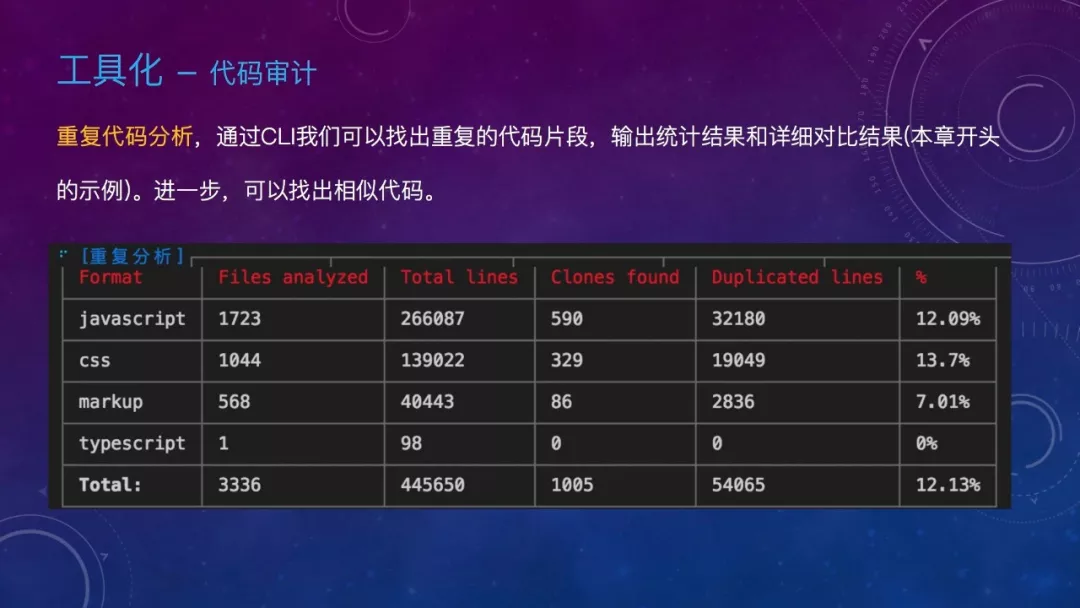
前面讲到通过 NPM 来减少重复代码。另外一个手段则是通过代码审计来避免重复代码的形成,通过 CLI 我们可以找出重复的代码片段,输出统计结果和详细对比结果(本章开头的示例)。进一步,可以找出相似代码。
可以看到,在改造前,我们 js 的重复率有12%,12%是什么概念?如果你只有两个一模一样的文件,重复率就是50%。12%意味着每8行代码代码里有2行是一样的。重复代码很多,那重复检测的依据是什么,常见的有基于 token 的对比和基于 AST 的对比。
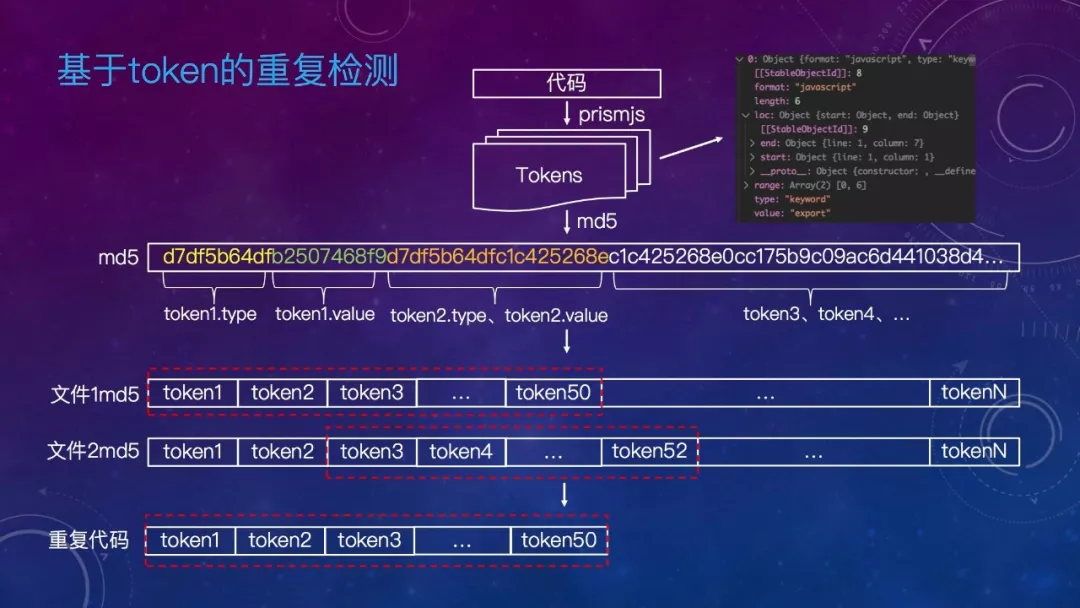
来看看基于 token 的重复检测原理,其实也很简单,就是将代码转换 token,然后再判断一定长度 token 的 md5 值是否相同。基于 AST 的重复及相似代码检测复杂一些,这里就不细讲了。

好,冗余问题我们通过组件化、代码审计的方式可以解决,接下来讲测试问题。
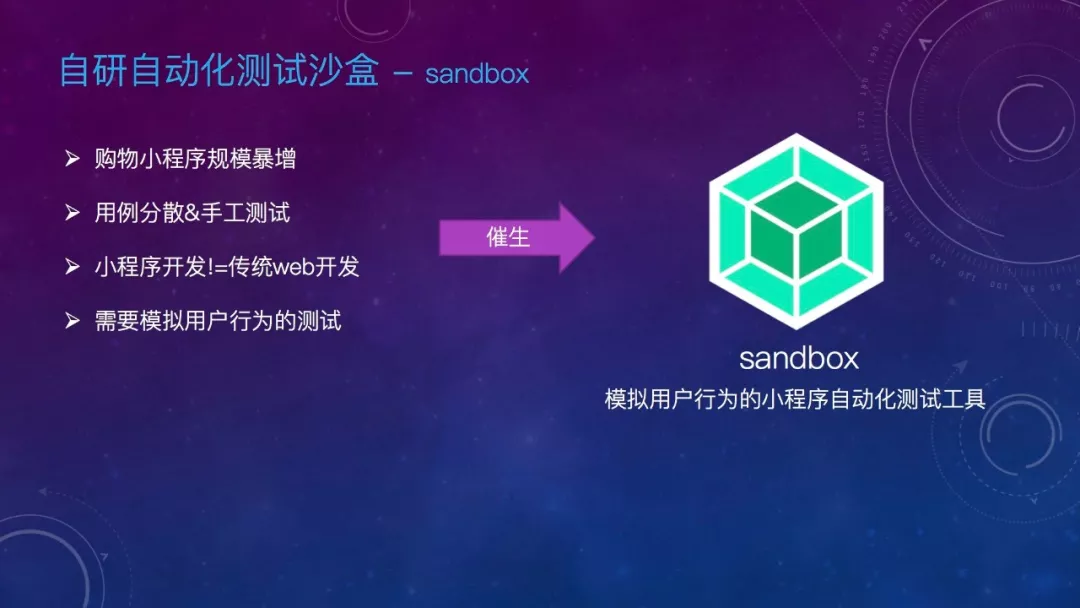
由于规模暴增,页面越来越多,有些公共文件的改动几乎会影响到所有页面,直接导致测试工作量飙升,质量无法保证。因此我们开发了一个模拟用户行为的小程序自动化测试工具 —— Sandbox。

Sandbox 架构分4层,第一层是测试用例层,第二层是用例步骤控制层,提供 api 供测试用例调用。第三层为沙盒环境,会预处理输入的小程序代码,创建小程序运行时,然后运行在 V8 引擎上,最后一层则是微信 api 的模拟供沙盒调用。需要提一下的是,今年6月份官方提供了小程序自动化 SDK,下一步我们对其进行整合。

这是结合 Mocha 编写的测试用例,可以看到测试用例调用沙盒 api 进行流程编排,有加载页面、模拟点击等。在最后的 check 方法中可以拿到当前页面的 data 和路由来检查是否符合预期。
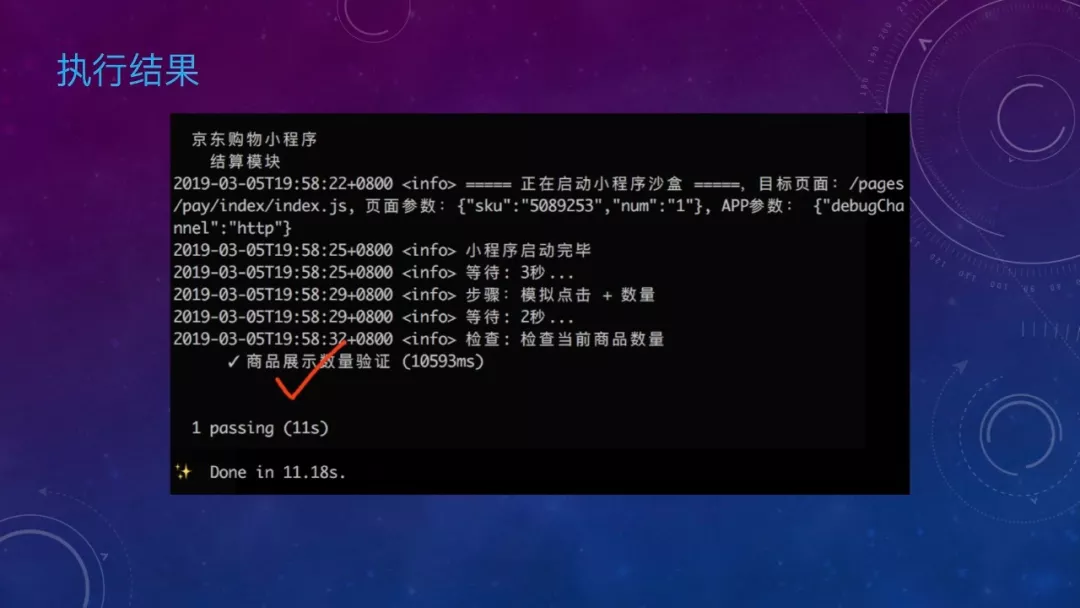
执行结果如图,这样就完成了对用户行为的模拟以及结果的自动验证。

好,通过自动化测试沙盒,解放了大量测试人力,使得他们可以更专注于版本特性,保证了版本质量。接下来看看代码包超限的问题。

不管是微信小程序,还是支付宝小程序或者其他小程序,代码包大小都是有限制的,拿微信小程序举例,总包上限为8M,主包或单个分包上限为2M。
代码包超限首先是影响发版进度,不知道你有没有体验过:熬夜加班写完代码,测都测完了,跟别人的分支合并时发现超限了。这显然不是一时半会能解决的,不紧急的可以等下次发版,紧急的就只能推迟发布了。
然后是新增业务,分包大小已经接近上限了,来个新页面,谁来腾空间?这也是个不得不面对的问题。
最后由于代码包太大,启动慢是必然的,太接近包上限,也容易导致小程序内存不足、甚至微信客户端闪退等问题。

怎么办呢,首先是要减小体积。常见的减小体积的方式有这些,前面几种手段相对比较常规,重点讲一下最后一条:找出未使用的文件、函数,删掉。

来看看未使用的文件、函数是怎么形成的。项目初期我们使用 gulp 进行构建,通过规则指定哪些目录需要打包,哪些文件需要剔除等,但久而久之,规则难免有遗漏。随着业务迭代,页面/组件下线,许多公共函数不再被引用,这些靠人工是很难识别的。自然也是需要通过工具化手段来解决。
第一个手段是依赖分析,通过工具在打包时删掉未使用的文件、函数,释放空间。另外一个手段是只能分包,打包时按照算法动态调整 NPM 包到主包或子包,临时调整分包大小。
文件的依赖分析,前面已经讲过了,下面看看函数依赖分析怎么做。

函数依赖分析,或者说 Tree-Shaking,就是识别出未使用的代码并删掉。在 h5 里听得多,相信大家也都有一些实践,小程序如何做呢?
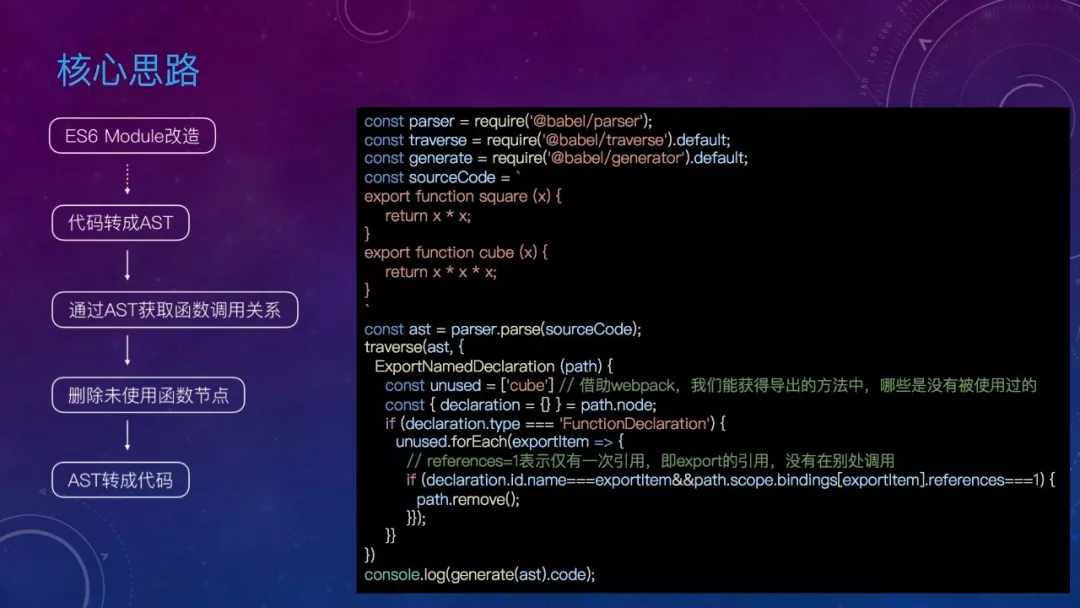
首先,Tree-Shaking 基于 ES6 的模块机制,为此,我们我要统一对小程序代码做了一轮改造,将 commonjs 模块写法全部替换成 ES6 的模块写法,这是前提。
有了这个前提,在 CLI 打包过程中,可以将代码转成 AST,通过 AST 获取各模块的调用关系,删除未使用函数节点,再将 AST 转成代码。
具体实现可以参考这份代码,需要注意的是,一个函数没有被其他模块引用并不代表可以直接删除,还需要考虑模块内的引用情况,同时,写代码时尽量避免副作用。
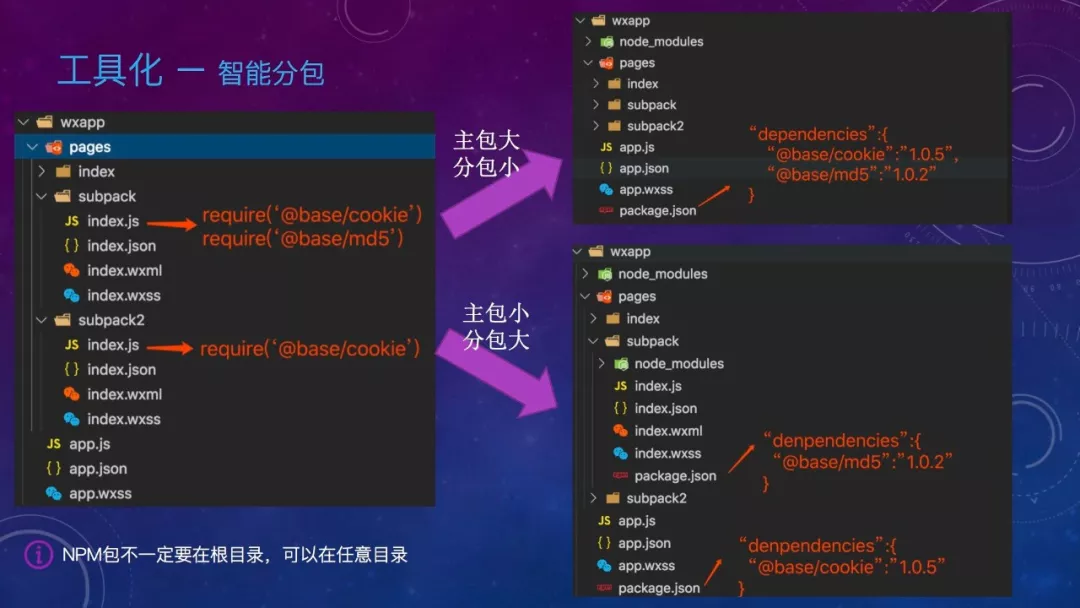
依赖分析可以删除未使用的文件、函数,释放空间。智能分包则是可以临时调整各分包大小。
看图,左边第一个分包使用了 cookie 和 md5 两个包,第二个分包则只使用了 cookie,通过算法配置,在编译时可以选择将两个 NPM 包都提到主包,这时主包大,分包小。或者仅将共用的 cookie 提到主包,md5 留在分包,这时主包小,分包大。这样可以大幅度缓解发版时主包或者分包超限导致延期的问题。

智能分包流程是这样的,先解析 NPM 依赖,获得各 NPM 包被分包引用情况,根据算法动态生成 package.json 到分包,再到各分包下执行 npm install,接着调用开发者工具构建 NPM,最后修改引用路径,兼容低版本。

好,代码包超限的问题,我们通过依赖分析释放出了大概20%的空间,但这些都只是技术上的手段,根源还是在业务方,如果任由业务不断扩张,或许扔键盘是最好的解决方案。接下来看看多小程序间的代码复用问题。
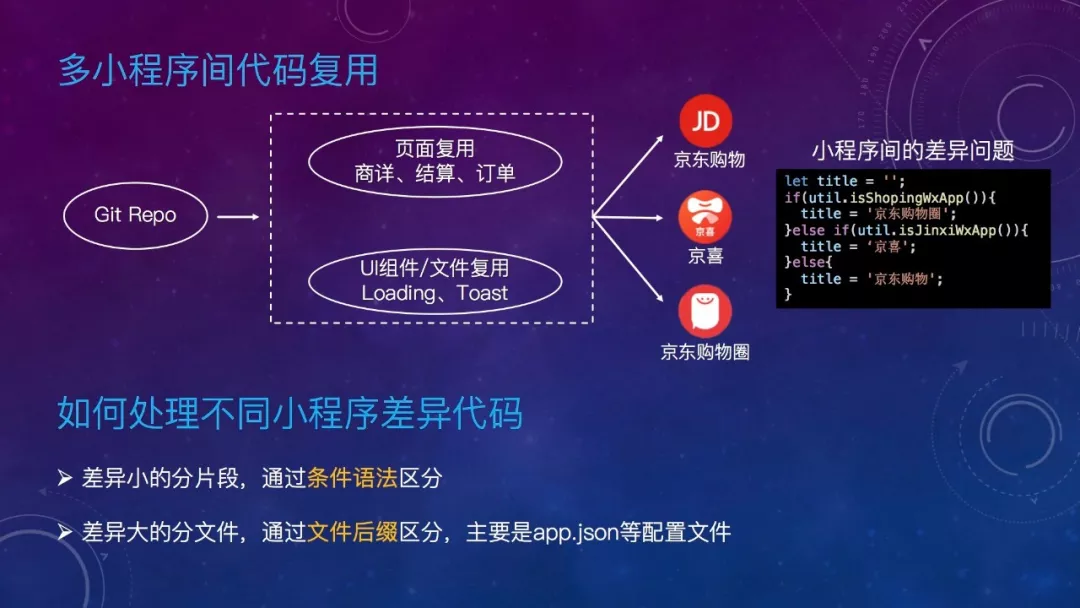
可以看到,同一个 git 项目中,有一些页面、组件、文件是可以同时被多个小程序复用的。复用就会产生类似这样的差异代码,大量的 if else用于环境判断,这些代码最终会出现在小程序代码包里,不管是执行速度也好,体积也好,都会受到影响,在小程序里,空间可是很宝贵的。正确的姿势应该是在编译阶段就将差异解决掉。
差异小的可以分片段,通过条件语法区分,差异大的分文件,通过文件后缀区分,主要是 app.json 等配置文件。
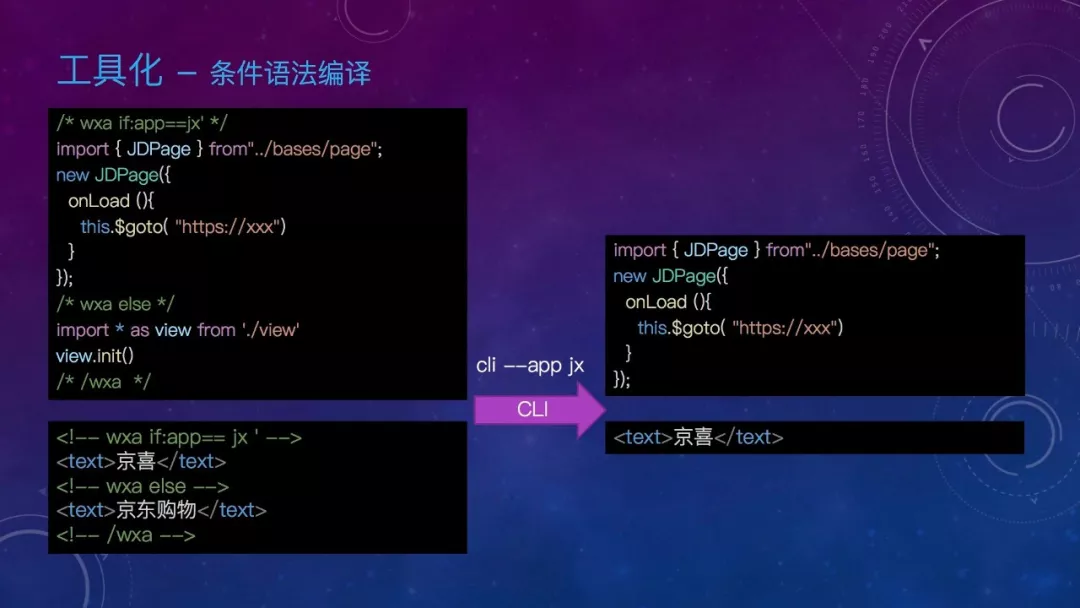
这些也是通过工具化来解决,首先看条件语法编译,我们采用注释的方式编写条件语法,通过 CLI 针对不同小程序编译出不同的代码片段,使得代码更简洁。
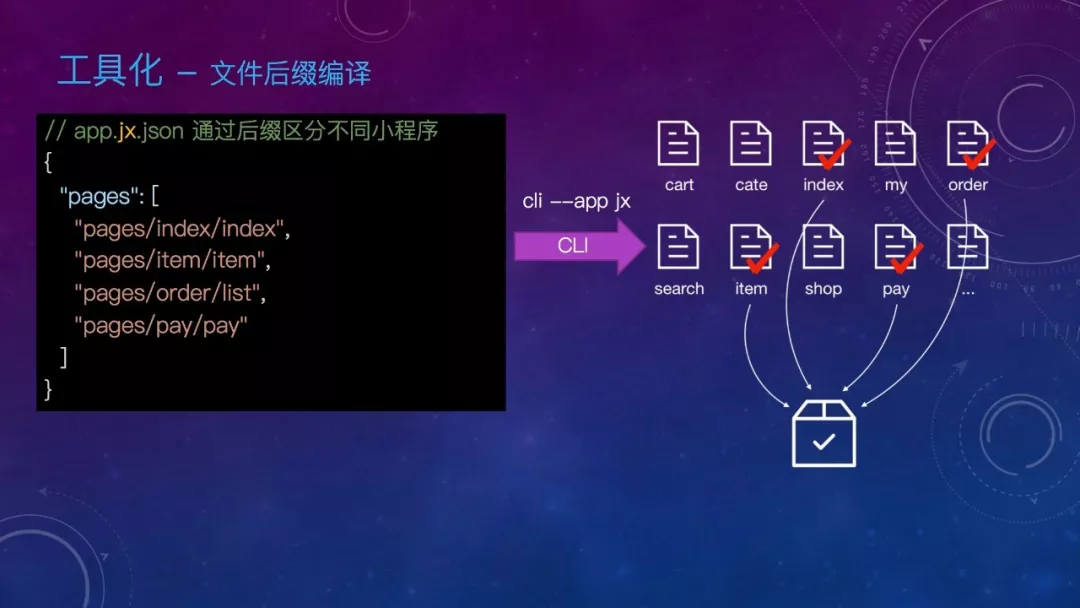
再看看文件后缀编译,小程序的 app.json 中会注册不同的页面,我们可以使用后缀来标识这个文件属于哪个 app,编译时根据 CLI 参数读取相应后缀的文件,这样就可以自由组合打包成不同的小程序。
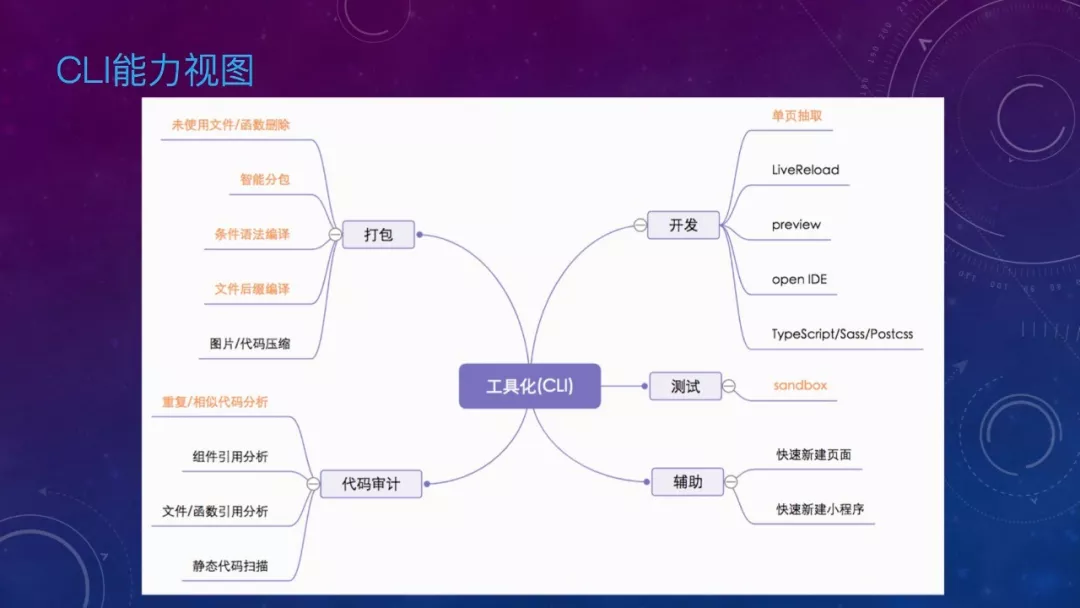
前面很多地方提到了工具化,这也是我们解决大规模小程序问题的主要手段,来总体看下 CLI 有哪些能力,开发这里讲到了单页抽取,测试这里讲到了 Sandbox,代码审计这里讲到了重复代码分析,打包这里讲到了未使用文件/函数删除、智能分包、条件编译等。除此之外,CLI 还包含了一些常用功能,如 LiveReload、ts 支持、静态代码扫描等等。
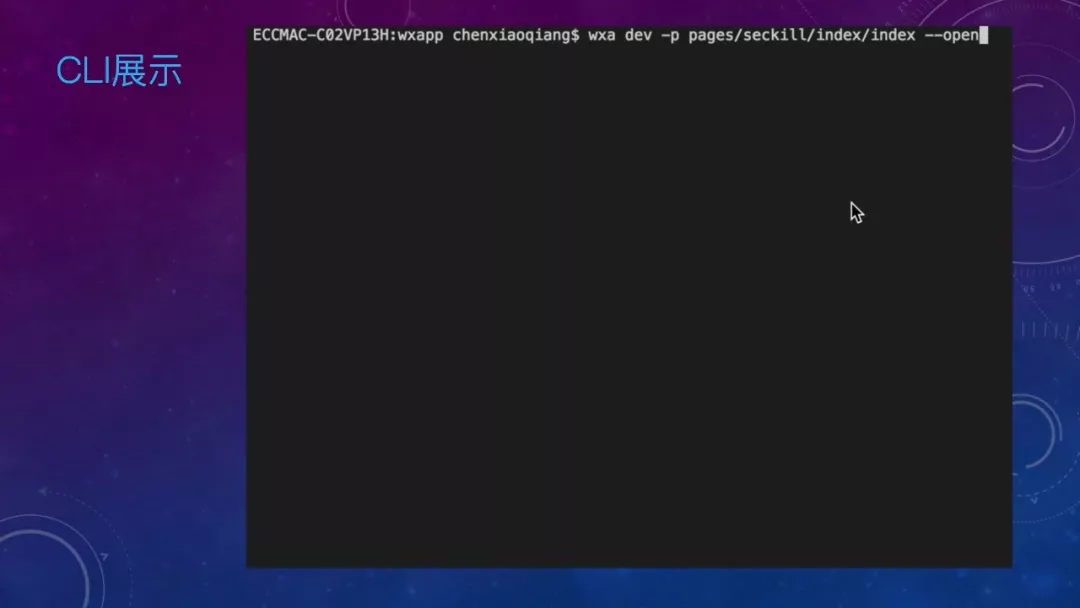
讲了这么多,看一下我们的 CLI 长啥样子:这是一个指定单页调试的命令,包含代码转换、依赖分析、npm 包的安装和构建、文件监听、自动唤起开发者工具等等。

好,多小程序间代码的复用问题,我们通过条件语法编译、文件后缀编译可以解决,接下来看看发布流程过于繁琐的问题。

Git Flow 想必大家都知道,我们的小程序也是基于 Git Flow 的分支规范,可以看到各个阶段需要的手工操作过多,可以想象一下,当发版时需要人工合并几十个分支时是什么样的场景,我们甚至经历过几次因为合版冲突的问题,十几号人花了大半天时间才解决。
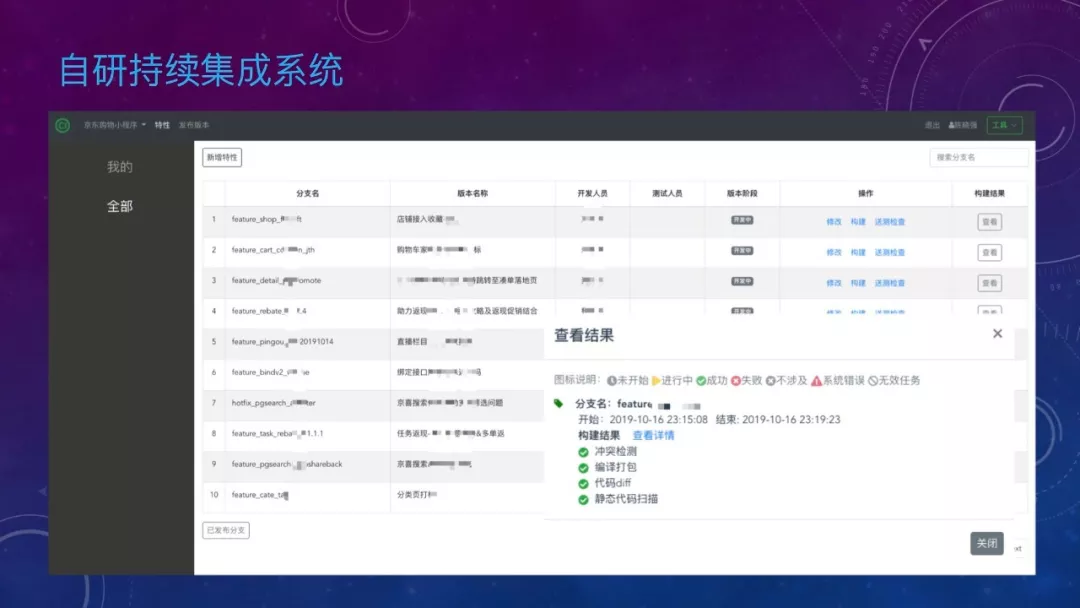
因此,我们通过流程固化、api 集成等手段搭建了持续集成系统,包含特性录入、发布计划管理、代码构建、Git 操作等多项功能。
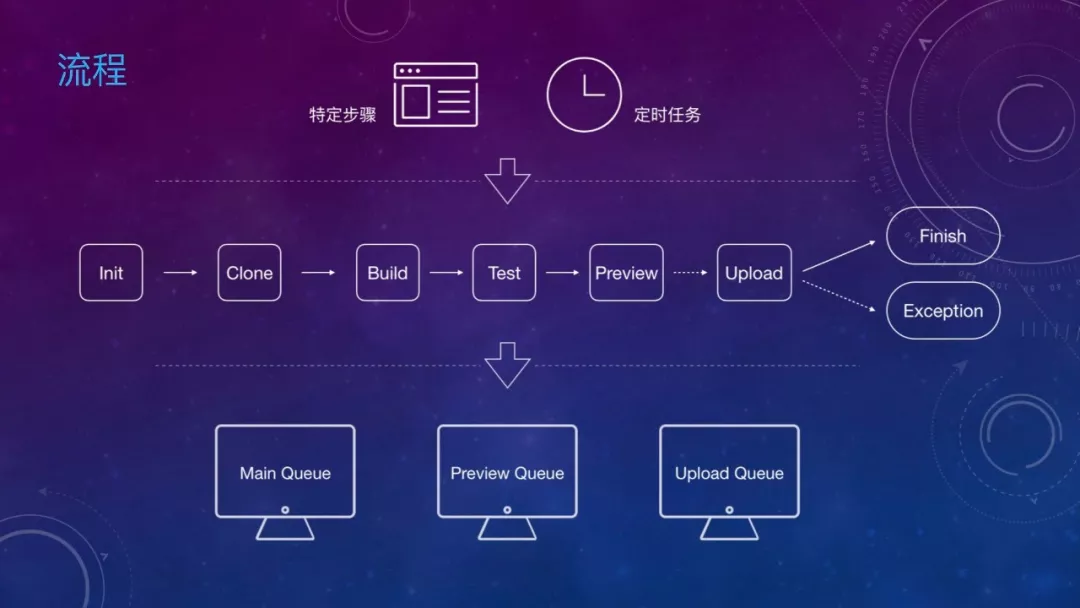
特定步骤包括:新建分支、送测、构建、关联发布版本等等,定时任务包括自动合并分支、静态代码扫描等。
具体的构建步骤,则是从项目初始化开始,获取代码,调用 CLI 工具进行编译,执行自动化测试、预览、上传。
最下面一层,由于预览、上传等依赖小程序开发者工具提供的 CLI 命令,比较耗时,使用了3个不同的进程队列来进行提速。

接入持续集成后,我们可以看到减少了很多手工操作,出错的概率也大大降低了。

好,最后一个问题也解决了。
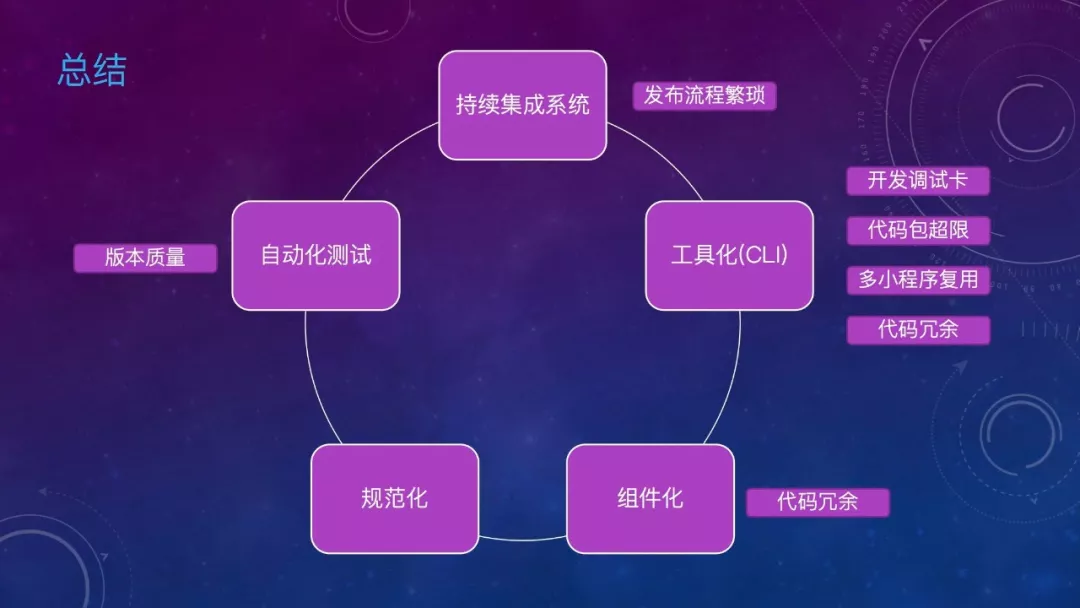
最后总结一下,大规模小程序场景,仅有规范是不够的,需要自动化测试保证版本质量,需要组件化解决代码冗余问题,需要工具化解决开发调试问题、打包编译等问题。持续集成系统解决发布流程繁琐问题。
总的看来,我们所做的这些,大多是基于现有的一些前端工程化方面的技术和思想,把它们应用到了小程序项目中,并针对小程序的特殊性做一差异化处理。放眼未来,希望整个小程序生态圈能够更加的规范和统一。