一、Spark Streaming 数据安全性的考虑:
- Spark Streaming不断的接收数据,并且不断的产生Job,不断的提交Job给集群运行。所以这就涉及到一个非常重要的问题数据安全性。
- Spark Streaming是基于Spark Core之上的,如果能够确保数据安全可好的话,在Spark Streaming生成Job的时候里面是基于RDD,即使运行的时候出现问题,那么Spark Streaming也可以借助Spark Core的容错机制自动容错。
- 对Executor容错主要是对数据的安全容错
- 为啥这里不考虑对数据计算的容错:计算的时候Spark Streaming是借助于Spark Core之上的容错的,所以天然就是安全可靠的。
Executor容错方式:
1. 最简单的容错是副本方式,基于底层BlockManager副本容错,也是默认的容错方式。
2.WAL日志方式
3. 接收到数据之后不做副本,支持数据重放,所谓重放就是支持反复读取数据。
BlockManager备份:
- 默认在内存中两份副本,也就是Spark Streaming的Receiver接收到数据之后存储的时候指定StorageLevel为MEMORY_AND_DISK_SER_2,底层存储是交给BlockManager,BlockManager的语义确保了如果指定了两份副本,一般都在内存中。所以至少两个Executor中都会有数据。

Receiver将数据交给BlockManger是由ReceiveredBlockHandler来处理的,有两种ReceiveredBlockHandler的实现:
1.WriteAheadLogBasedBlockHandler
2.BlockManagerBasedBlockHandler
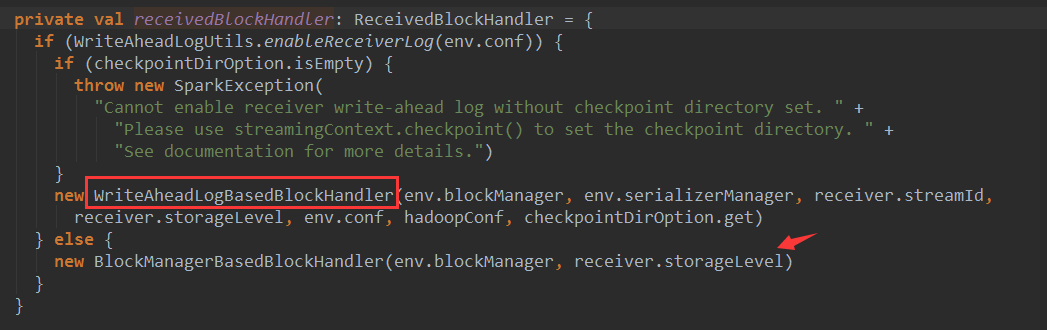
这里的storageLevel是构建InputDStream时传入的,socketTextStream的默认存储级别是StorageLevel.MEMORY_AND_DISK_SER_2

如果使用WriteAheadLogBasedBlockHandler需要开启WAL,默认并没有开启:
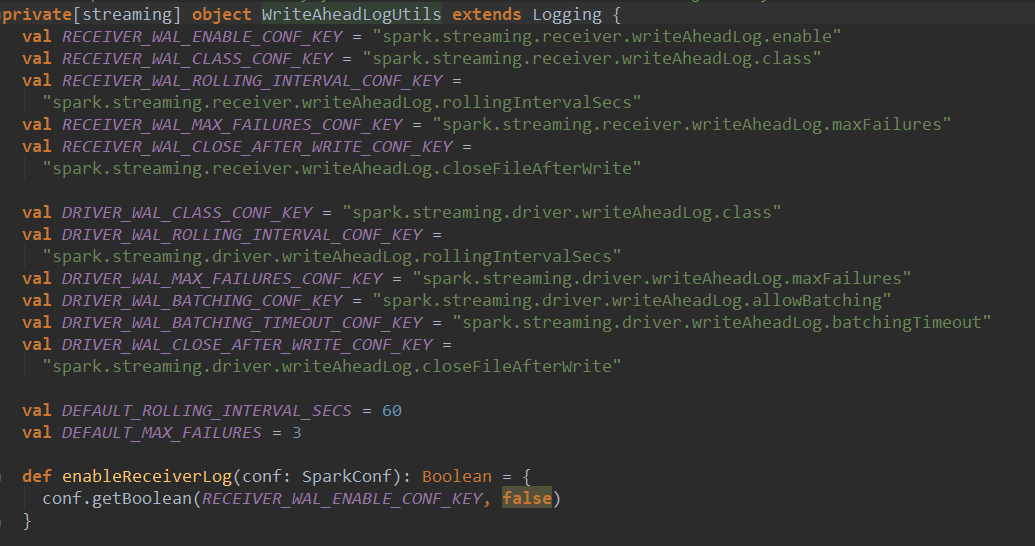
WAL日志方式:
这种方式会现将数据写入日志文件,就是checkpoint目录,出现异常是,从checkpoint目录重新读取数据,进行恢复。启动WAL时候,没必要将副本数设置成大于1,也不需要序列化。
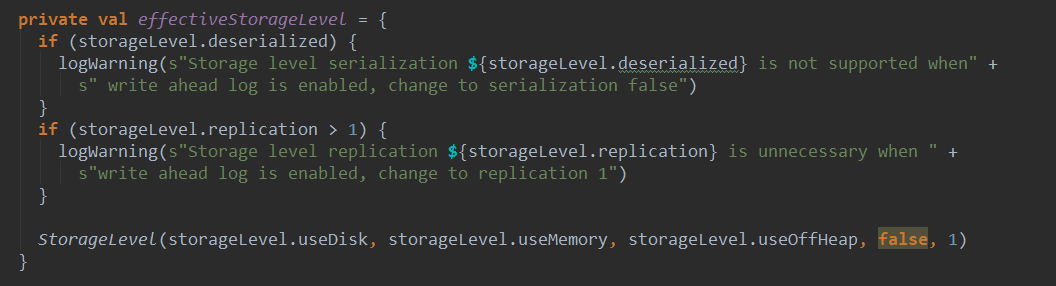
WAL会将数据同时写入BlockManager和write ahead log,而且是并行的写block,当然两处的block存储完成,才会返回。

将Block 存入BlockManager:
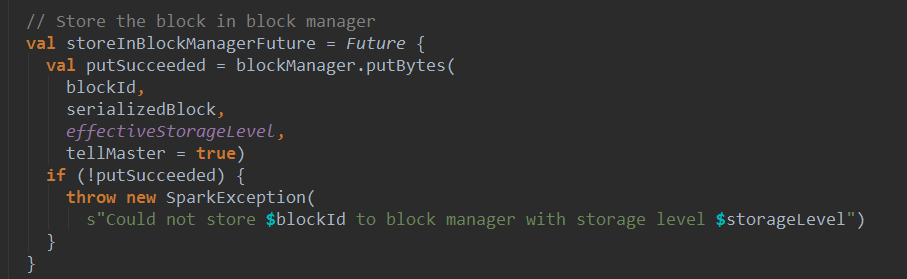
将Block 存入WAL日志:

WAL写数据的时候是顺序写,数据不可修改,所以读的时候只需要按照指针(也就是要读的record在那,长度是多少)读即可。所以WAL的速度非常快。浏览一下WriteAheadLog,他是一个抽象类: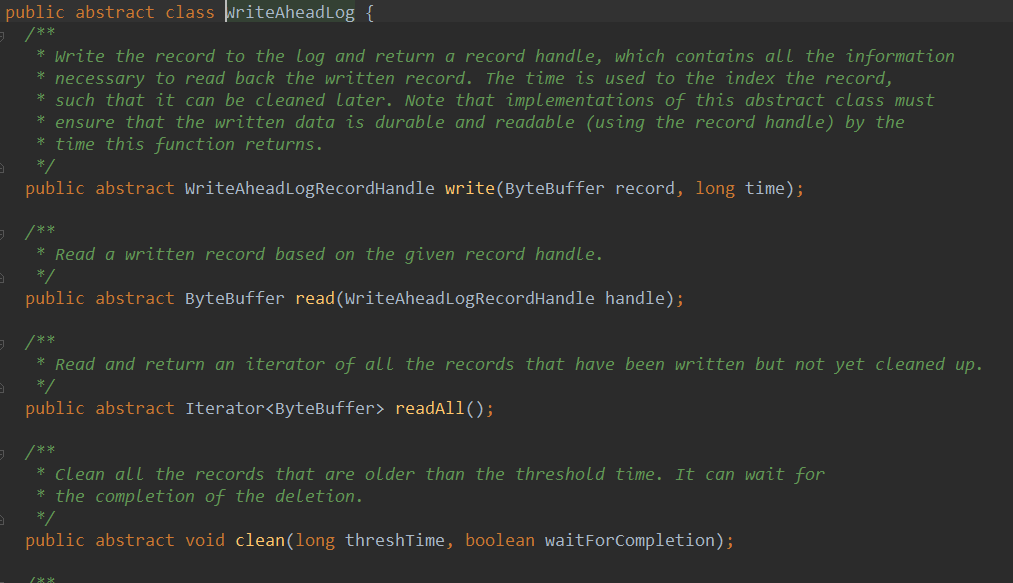
看一下WriteAheadLog的一个实现类FileBasedWriteAheadLog的write方法: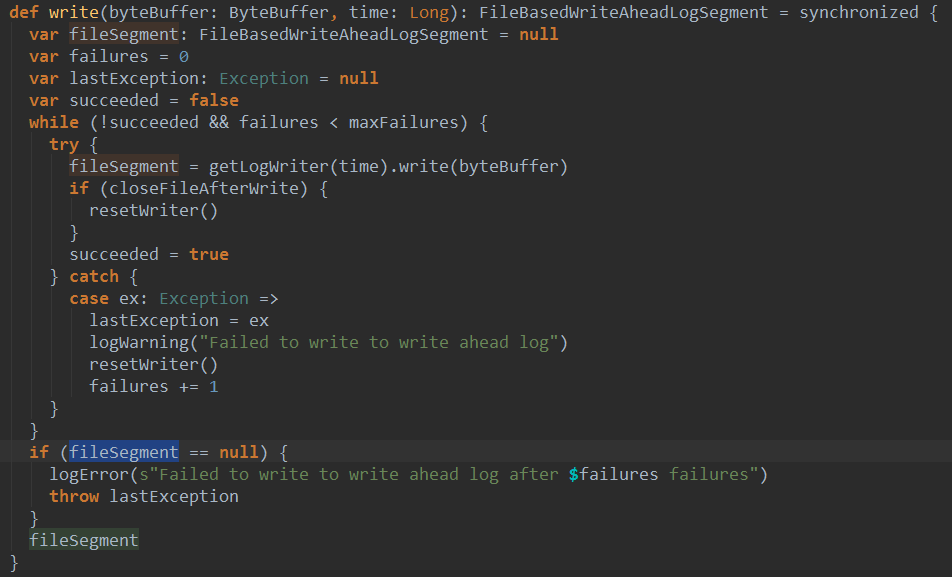
根据不同时间获取不同Writer将序列化结果写入文件,返回一个FileBasedWriteAheadLogSegment类型的对象fileSegment。
读数据:
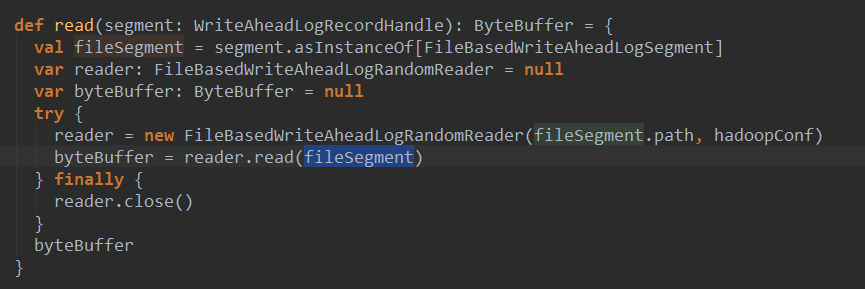
其中创建了一个FileBaseWriteAheadLogRandomReader对象,然后调用了该对象的read方法:

支持数据重放。
在实际的开发中直接使用Kafka,因为不需要容错,也不需要副本。
Kafka有Receiver方式和Direct方式
Receiver方式:是交给Zookeeper去管理数据的,也就是偏移量offSet.如果失效后,Kafka会基于offSet重新读取,因为处理数据的时候中途崩溃,不会给Zookeeper发送ACK,此时Zookeeper认为你并没有消息这个数据。但是在实际中越来用的越多的是Direct的方式直接操作offSet.而且还是自己管理offSet.
- DirectKafkaInputDStream会去查看最新的offSet,并且把offSet放到Batch中。
- 在Batch每次生成的时候都会调用latestLeaderOffsets查看最近的offSet,此时的offSet就会与上一个offSet相减获得这个Batch的范围。这样就可以知道读那些数据。
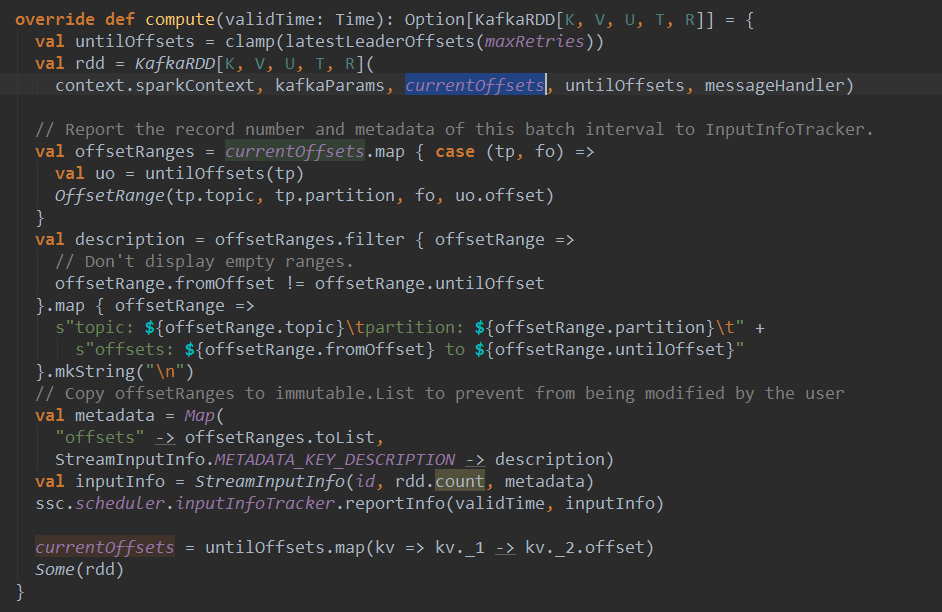
protected final def latestLeaderOffsets(retries: Int): Map[TopicAndPartition, LeaderOffset] = {
val o = kc.getLatestLeaderOffsets(currentOffsets.keySet)
// Either.fold would confuse @tailrec, do it manuallyif (o.isLeft) {
val err = o.left.get.toString
if (retries <= 0) {
throw new SparkException(err)
} else {
log.error(err)
Thread.sleep(kc.config.refreshLeaderBackoffMs)
latestLeaderOffsets(retries - 1)
}
} else {
o.right.get
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17