上篇文章详细解析了Receiver不断接收数据的过程,在Receiver接收数据的过程中会将数据的元信息发送给ReceiverTracker:
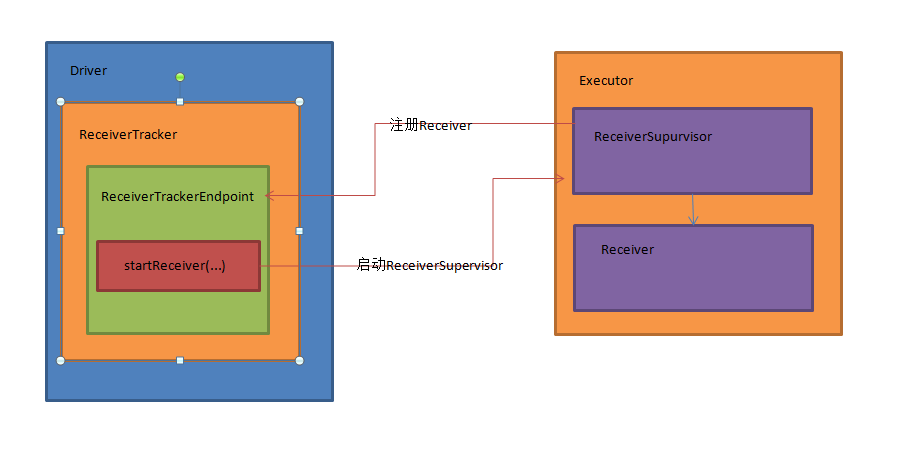
本文将详细解析ReceiverTracker的的架构设计和具体实现
一、ReceiverTracker的主要功能
ReceiverTracker的主要功能有:
1.在Executor上启动Receivers
2.接受Receiver的注册
3.借助ReceivedBlockTracker来管理Receiver接收数据的元数据
4.接受Receiver发送的各种消息,并作相应处理
5.更新Receiver接收数据的速率(也就是限流)
6.不断的等待Receivers的运行状态,只要Receivers停止运行,就重新启动Receiver。也就是Receiver的容错功能。
7.停止Receivers
8.汇报Receiver发送过来的错误信息
二、ReceiverTracker具体功能详解
2.1 启动receiver并管理receiver接收数据的元数据
首先,ReceiverTracker内部有一个ReceiverTrackerEndPoint通讯体endpoint变量,endpoint用来和Receiver和ReceiverTracker本身进行消息通讯。这个ReceiverTrackerEndPoint通讯体在ReceiverTracker启动时被初始化:
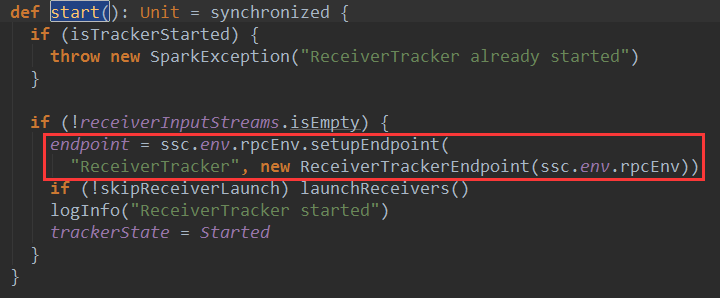
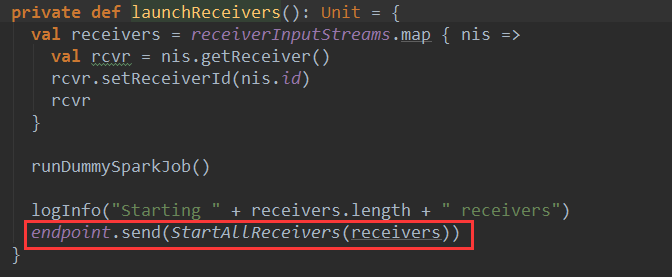
ReceiverTracker启动Receiver时候,向ReceiverTrackerEndPoint通讯体endpoint变量发送了StartAllReceivers(receivers)消息:
Receiver启动后会向ReceiverTracker注册,告诉ReceiverTracker自己启动成功:

代码中的trackerEndpoint就是ReceiverTracker中ReceiverTrackerEndPoint通讯体endpoint的引用。
Receiver会不断将接收的数据封装成Block,并将这些Block推送给BlockManager管理,在将这些Block推送给BlockManager之后,ReceiverSupervisor会将Block的元信息发送给ReceiverTracker的endpoint:
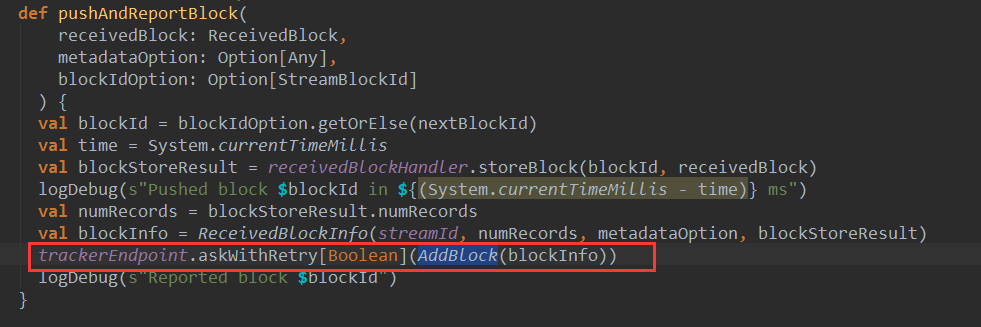
可以看到ReceiverSupervisor向ReceiverTracker的endpoint发送了AddBlock(blockInfo)消息:
ReceiverTracker收到AddBlock(blockInfo)消息后,会启动一个线程进行处理:
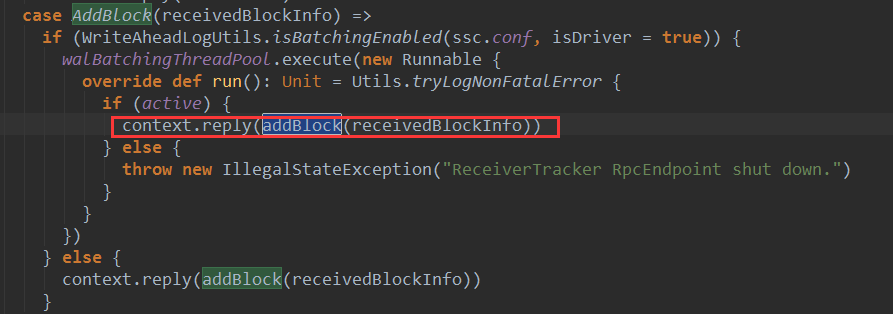
ReceiverTracker收到AddBlock(blockInfo)消息后,调用了addBlock(receiveedBlockInfo)方法进行处理,下面是addBlock的源码:

这里其实调用了receivedBlockTracker的addBlock方法,receivedBlockTracker是ReceivedBlockTracker对象,它是在ReceiverTracker实例化时候被创建:
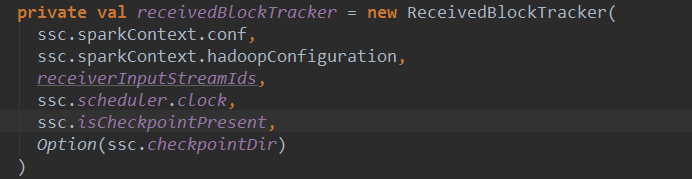
下面看一下ReceivedBlockTracker的addBlock方法:
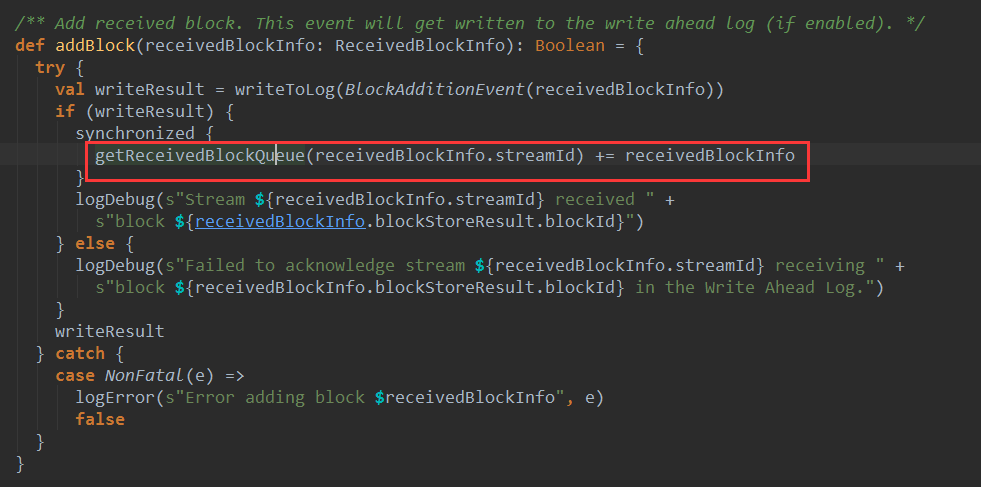
可以看到ReceivedBlockTracker的addBlock方法将block的元信息添加到了一个队队列中,最终是添加到一个叫做streamIdToUnallocatedBlockQueues的HashMap中,其中key是streamId,值是该streamid对应的block队列。

2.2 为Batch分配Block
当spark streaming应用程序动态生成job的时候,JobGenerator会调用generateJobs方法,在该方法中会为批处理分配已经接收的Block
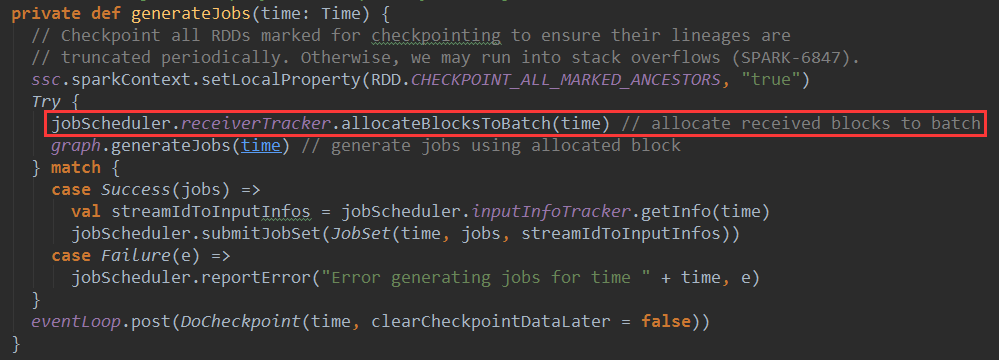
这里调用了jobScheduler中receiverTracker的allocatedBlockToBatch方法,这里的receiverTracker就是ReceiverTracker对象,下面看一下该方法的实现:
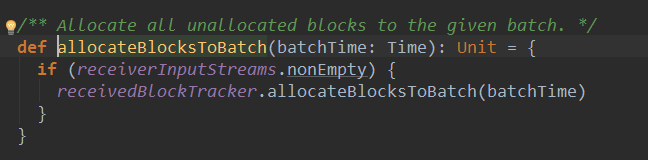
可以看到,最终调用了ReceivedBlockTracker的allocatedBlockToBatch方法:
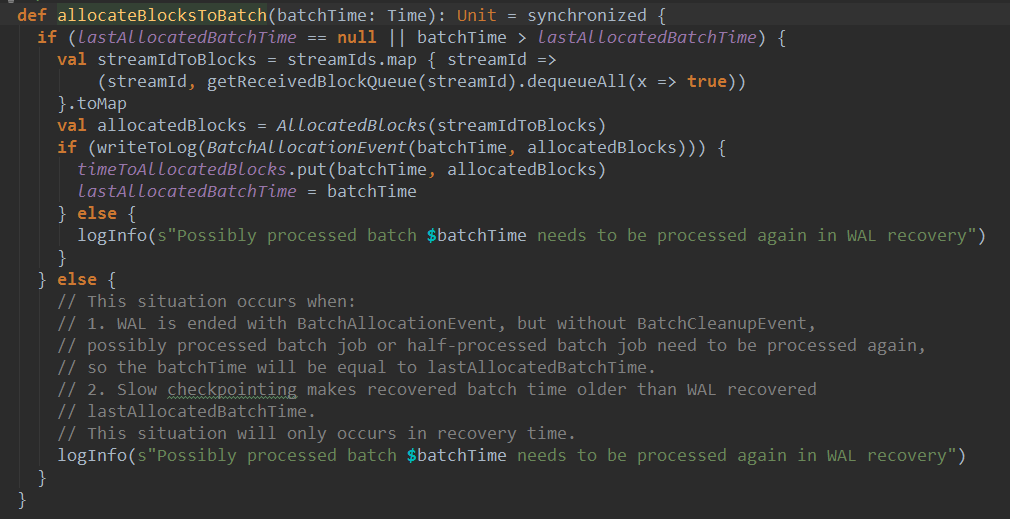
这里先根据streamId,从streamIdToUnallocatedBlockQueues中取出接收到的block队列,并将streamId和block队列封装成AllocatedBlocks,最后根据batchTime将其对应的AllocatedBlocks对象加入timeToAllocatedBlocks中,timeToAllocatedBlocks是一个HashMap:
这样Batch的Block就分配完成。
2.3 ReceiverTracker处理的其他消息
ReceiverTracker中ReceiverTrackerEndpoint的receive方法定义了各种消息的处理逻辑:
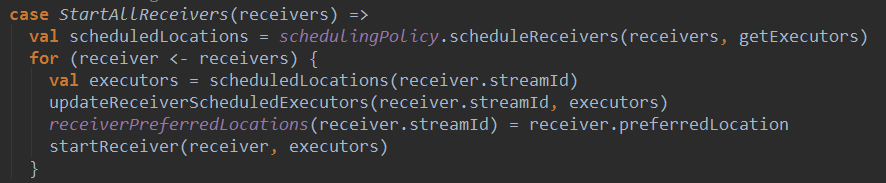
(1) 收到StartAllReceivers(receivers)消息后,ReceiverTracker会为receivers分配executor,并在executor上启动相应的receiver
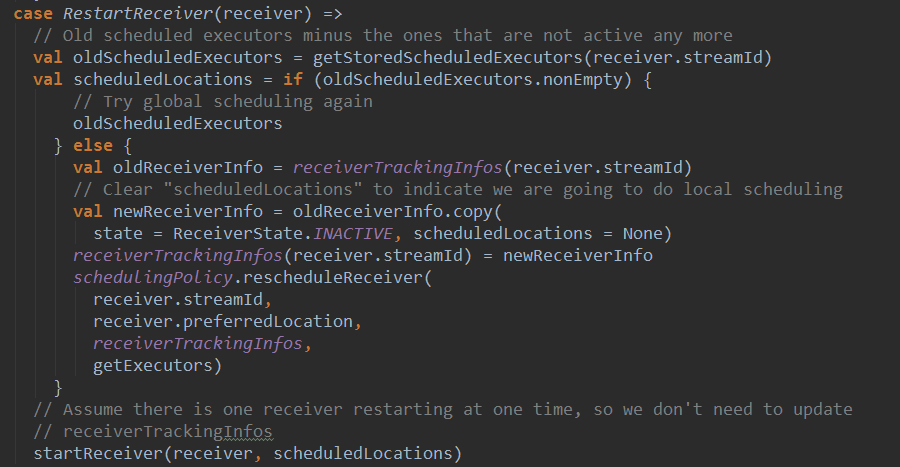
(2)当ReceiverTracker监控到receiver退出返回时,会给ReceiverTrackerEndpoint发送RestartTracker(receiver)消息。收到该消息后,会重新为receiver分配executor启动receiver(如果原来的executor运行正常就在原先的executor上重新启动,否则重新调度executor)。
(3)当Spark Streaming 的job结束后,JobScheduler会调用handleJobCompletion方法,最终会调用cleanupOldBlocksAndBatches方法给endpoint发送CleanupOldBlocks消息:

收到该消息后,会被路由到Receiver 进行Block的清理。
(4)UpdateReceiverRateLimit消息

收到UpdateReceiverRateLimit消息后,会将其路由到receiver,当receiver收到该消息后会调用BlockGenerator的update方法更新Block生成速率。