论文:Enhanced Multi-Channel Graph Convolutional Network for Aspect Sentiment Triplet Extraction
论文地址:https://aclanthology.org/2022.acl-long.212.pdf
名词解释
方面级情感分析(Aspect-based Sentiment Analysis, ABSA)是一项细粒度的情感分析任务,主要针对句子级别的文本,分析文本中相关的方面项(Aspect Term)、观点项(Opinion Term)、方面类别(Aspect Category)和情感极性(Sentiment Polarity),在不同的场景下对应着不同的子任务。
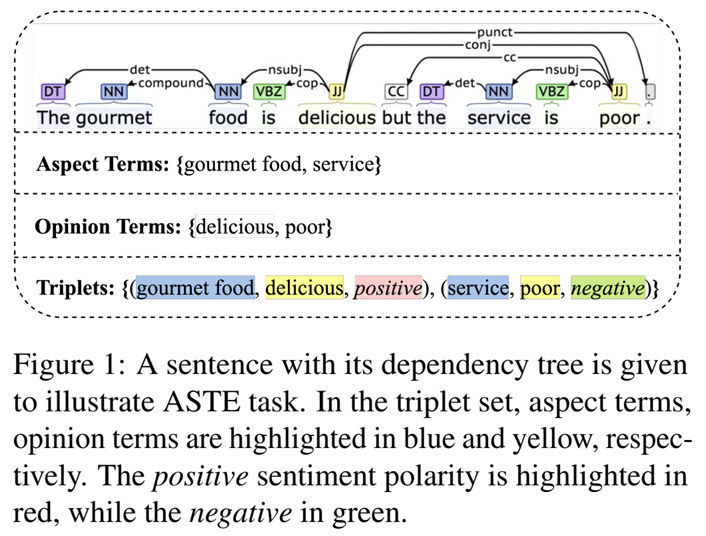
方面情感三元提取(Aspect Sentiment Triplet Extraction ,ASTE) 是 Aspect-based Sentiment Analysis (ABSA) 的一个新变体。 ASTE 任务旨在从句子中提取方面情感三元组,每个三元组包含三个元素,即方面词、观点词及其情感极性。下图是ASTE任务的一个示例。
图卷积网络(Graph Convolutional Networks, GCN),在图上使用卷积运算……(待补充)
张量(Tensor),它是数字的容器,仅包含一个数字的张量叫作标量(scalar,也叫标量张量、零维张量、0D 张量),矩阵是二维张量,张量是矩阵向任意维度的推广[注意,张量的维度(dimension)通常叫作轴(axis)]。
池化函数(Pooling Function),在神经网络中,池化函数一般在卷积函数的下一层。在经过卷积层提取特征之后,得到的特征图代表了比像素更高级的特征,已经可以交给分类器进行训练分类了。但是每一组卷积核都生成一副与原图像素相同大小的卷积图。如果使用了多个卷积核还会使得通道数比之前多。所以卷积之后我们需要进行池化,也就是进行降维,以加快运算速度,其实就是采样。两种主要池化方式:最大池化(Max Pooling)、平均池化(Average Pooling),利用一个矩阵窗口在张量上进行扫描,将每个矩阵中的值通过取最大值或者平均值等来减少元素的个数。
一 问题
(1) 如何利用单词之间的各种关系帮助ASTE任务?
以Figure 1为例;对于词对("gourmet","food"),“gourmet”和“food”属于同一个方面词“gourmet food”。同样,对于词对("food","delicious"),“food”是“delicious”的观点目标,积极的情感极性。因此,为了有效地提取了方面词“gourmet food”,我们期望“gourmet”可以获取“food”的信息,反之亦然。为了判断方面词的情感极性,观点词“delicious”的信息应该传递给“gourmet food”。简而言之,我们需要基于单词之间的关系来学习任务相关的单词表示。
(2) 如何利用语言特征来帮助 ASTE 任务?
首先,方面词“gourmet food”和“service”是名词,而观点词“delicious”和“poor”是形容词。因此,由名词和形容词组成的词对往往形成方面-观点对。其次,从图1中的句法依存树来看,词对中存在不同的依存类型。例如,“gourmet”和“food”是复合名词,因为它们之间的依存类型是“compound”,而“food”是“delicious”的名词性主语,因为类型“nsubj”。因此,这些依赖类型不仅可以帮助提取方面和观点项,还可以帮助它们匹配。此外,我们考虑了描述两个单词相关性的基于树的和相对位置距离。
基于上述问题提出:增强型多通道图卷积网络模型 (EMC-GCN)
首先,利用一个双仿射注意力模块来对句子中单词之间的关系概率分布进行建模,并使用一个向量来表示它,向量中的每个维度对应于某种关系类型,为此,可以从一个句子中推导出一个关系邻接张量。EMC-GCN通过将单词和关系邻接张量分别视为节点和边,将句子转换为多通道图。为了学习单词之间的精确关系,对关系邻接张量施加关系约束。
其次,为了利用语言特征,包括词汇和句法信息,我们获得了句子中每个词对的词性组合、句法依赖类型、基于树的距离和相对位置距离。同样,分别将这些特征转换为多通道图的边,以进一步增强模型。虽然部分语言特征已应用于其他任务(Kouloumpis et al., 2011; Sun et al., 2019; Phan and Ogunbona, 2020; Li et al., 2021),据我们所知,它们很少用于 ASTE 任务,探索各种语言特征,以一种新颖的方式将它们适配并应用于 ASTE 并非易事。
最后,受多标签分类任务中的分类器链方法 (Read et al., 2011) 的启发,设计了一种有效的精炼策略。在判断词对是否匹配时,我们的策略考虑了方面和观点提取的隐含结果,以进行词对表示的。
二 创新点
1)为 ASTE 任务提出了一种新颖的 EMC-GCN 模型。 EMC-GCN 利用多通道图来编码单词之间的关系。多通道图上的卷积函数用于学习关系感知节点表示。
2) 提出了一种新方法来充分开发语言特征以增强基于 GCN 的模型,包括词性组合、句法依赖类型、基于树的距离和每个词对的相对位置距离。
3)提出了一种有效的精炼策略来精炼词对表示。它在检测词对是否匹配时考虑了方面和观点提取的隐含结果。
4) 对基准数据集进行了广泛的实验。实验结果表明 EMC-GCN 模型有效。
三 近期研究
Peng et al.,(2020)首先提出ASTE任务,并开发了一个两阶段的管道框架,将方面提取、方面情感分类和观点提取结合在一起。为了进一步探索这项任务,(Mao et al.,2021;Chen et al.,2021a)将 ASTE 转换为机器阅读理解问题,并利用共享的 BERT 编码器在多阶段解码后获得三元组。
另一条研究思路主要是设计一种新的标记方案,使模型能够以端到端的方式提取三元组(Xu et al., 2020; Wu et al., 2020a; Zhang et al., 2020; Xu et al., 2021;Yan et al.,2021),从而有效地促进了三元组的提取。例如,Xu et al.(2020)提出了一种位置感知标记方案,该方案通过丰富标签的表现能力来解决已有相关工作的限制。Wu et al.(2020a) 提出了一种网格标记方案,类似于表格填充 (Miwa and Sasaki, 2014; Gupta et al., 2016),以端到端的方式解决此任务。Yan et al.(2021) 将 ASTE 任务转换为生成公式。
然而,这些方法都忽略了单词和语言特征之间的关系。
四 模型介绍
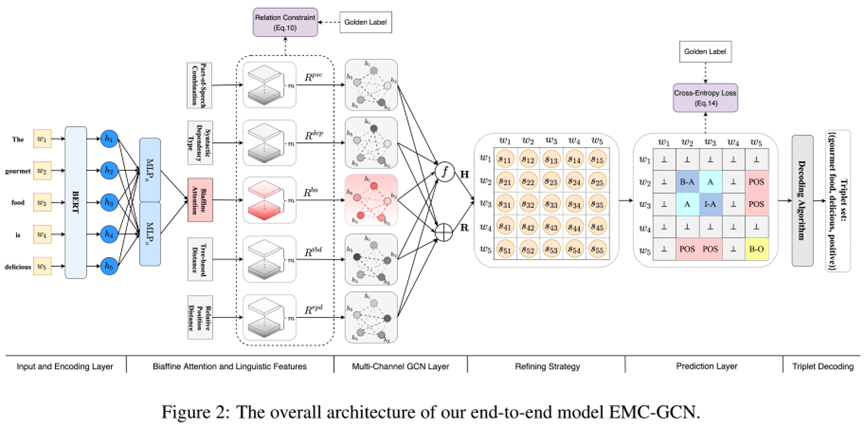
EMC-GCN 框架概述如图2所示。
1任务定义
给定一个输入句子![]() ,包含n个单词,目标是从X中抽取出一批三元组
,包含n个单词,目标是从X中抽取出一批三元组![]() ,其中a和o分别表示方面项和观点项,s表示情感极性且s属于情感标签集S = {POS, NEU, NEG},也就是说,情绪标签集由三个情绪极性组成:积极、中性和消极。句子X总共有|T|个三元组。
,其中a和o分别表示方面项和观点项,s表示情感极性且s属于情感标签集S = {POS, NEU, NEG},也就是说,情绪标签集由三个情绪极性组成:积极、中性和消极。句子X总共有|T|个三元组。
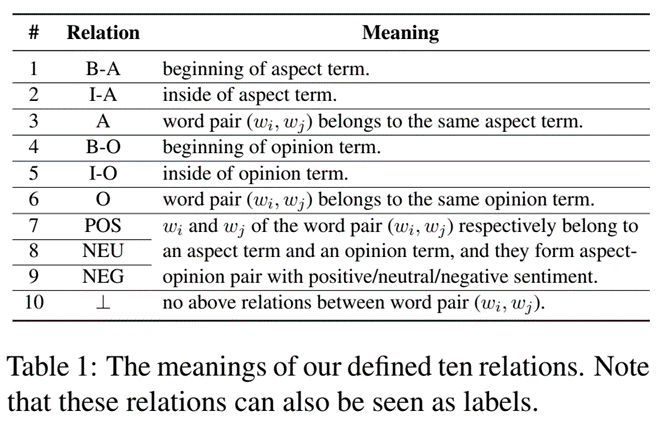
2关系定义和表格填充
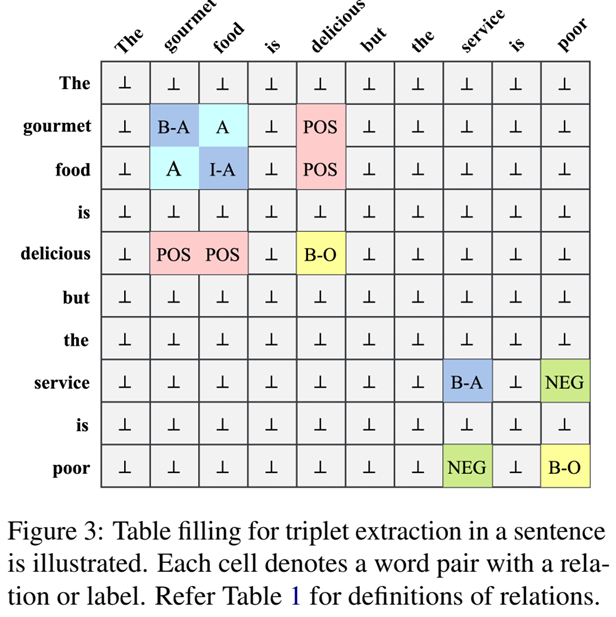
为 ASTE 定义了单词之间的十种关系。这些关系如table 1所示。具体来说,四个关系或标签 {B-A, I-A, B-O, I-O} 旨在提取方面术语和观点术语。与 GTS (Wu et al., 2020a) 相比,我们定义的关系在我们的模型中引入了更准确的边界信息。B 和 I 分别表示术语的开头和内部,而 -A 和 -O 子标签旨在确定术语的作用,即方面或观点。table 1 中的 A 和 O 关系用于检测由两个不同的词组成的词对是否分别属于同一个方面或观点词。三个情感关系{POS, NEU, NEG}的目标不仅是检测一个词对是否匹配,还要判断方面-观点对的情感极性。因此,可以使用表格填充方法为每个标记的句子构建一个关系表(Miwa and Sasaki, 2014; Gupta et al., 2016)。如图3,在一个例句中显示了词对及其关系,每个单元格对应一个具有关系的词对。
3三元解码
ASTE任务的解码细节如算法1所示。为简单起见,使用上三角表来解码三元组。首先,仅使用基于主对角线的所有词对(wi,wi)的预测关系,来提取方面项和观点项;其次,判断提取的方面项和观点项是否匹配,计算所有单词对 (wi, wj) 的预测关系,其中 wi ∈ a 和 wj ∈ o,如果预测关系中存在任何情感关系,则认为方面项和观点项是配对的,否则这两个不配对;最后,判断方面-观点对的情感极性,预测最多的情感关系 s ∈ S 被视为情感极性。最终,得到一个三元组 (a, o, s)。

4 EMC-GCN模型
1) 输入和编码层
利用 BERT 作为句子编码器来提取隐藏的上下文表示。给定一个带有 n 个标记的输入句子 X = {w1, w2, ..., wn},编码层在最后一个 Transformer 块处输出隐藏表示序列 H = {h1, h2, ..., hn}。
2) 双仿射注意模块
双仿射注意力已被证明在句法依赖解析中有效(Dozat and Manning,2017),因此利用双仿注意力模块捕获句子中每个词对的关系概率分布。双仿射注意过程被表述为:
(个人觉得公式3到公式4少了说明,怎么就多出来一维m呢,只能猜测是公式3的计算重复了m次……)
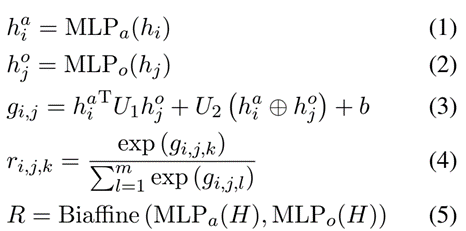
使用了多层感知器。分数向量 ri,j ∈ R1×m 对 wi 和 wj 之间的关系进行建模,m 是关系类型的数量,ri,j,k 表示词对 (wi, wj) 的第 k 个关系类型的分数。邻接张量 R ∈ Rn×n×m 对词之间的关系进行建模,每个通道对应一个关系类型。 U1、U2 和 b 是可训练的权重和偏差。 ⊕ 表示连接。公式(5) 是公式(1)-(4)的汇总。
3) 多通道GCN
受 CNN 的启发,GCN 是一种高效的 CNN 变体,可直接在图上运行(Kipf 和 Welling,2017)。一个图包含节点和边,GCN 对通过边直接连接的节点应用卷积操作来聚合相关信息。给定一个包含 n 个单词的句子,一般的方法是使用句法依存树构造一个邻接矩阵 A ∈ Rn×n,表示该句子的图(Zhang et al., 2019; Sun et al., 2019)。元素 Aij 表示节点对 (wi, wj) 的边,具体来说,如果第 i 个节点直接连接到第 j 个节点,则 Aij = 1,否则 Aij = 0。一些研究(Guo et al., 2019; Chen et al., 2020a; Li et al., 2021)通过图的注意力机制构建软边,任何节点对(wi,wj)的边是一个概率,表示节点wi和wj之间的相关程度。
为了对单词之间的各种关系进行建模,EMC-GCN 扩展了最原始的GCN,其具有由上述双仿射注意模块构建的多通道邻接张量 Rba ∈ Rn×n×m。邻接张量的每个通道代表表1 中定义的单词之间关系的建模。然后,利用 GCN 沿每个通道为每个节点聚合信息。流程如下:
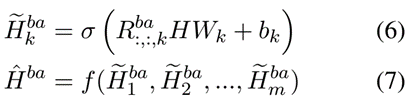
其中 Rba:,:,k ∈ Rn×n 表示 Rba 的第 k 个通道切片。 Wk 和 bk 是可学习的权重和偏差。 σ 是一个激活函数(例如,ReLU)。平均池化函数 f(·) 应用于所有通道的节点隐藏表示。
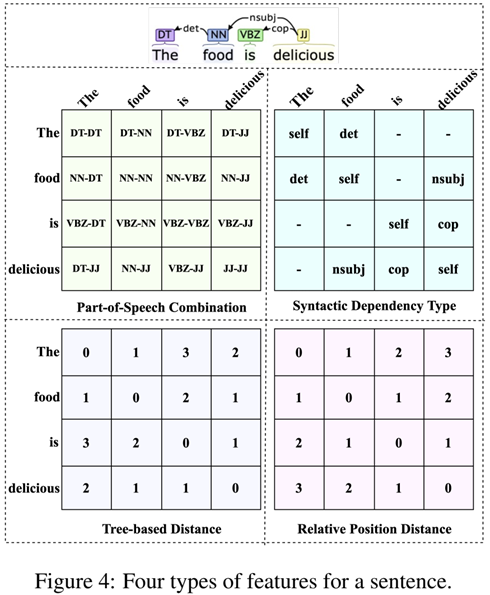
4) 语言特征
为了增强EMC-GCN 模型,我们为每个词对引入了四种类型的语言特征,如图 4 所示,包括词性组合、句法依赖类型、基于树的距离和相对位置距离。一开始随机初始化四个邻接张量,即Rpsc、Rdep、Rtbd和Rrpd,以句法依赖类型特征Rdep为例,为每个词对(wi,wi)添加一个自依赖类型,如果 wi 和 wj 之间存在依赖弧,并且依赖类型为 nsubj,则通过查找可训练的嵌入表,将 Rdep i,j,: 初始化为 nsubj的嵌入,否则用一个 m 维零向量初始化 Rdep i,j,:。随后,使用这些邻接张量重复图卷积操作以获得节点表示 ^Hpsc、^Hdep、^Htbd 和^Hrpd。最后,分别将平均池化函数和连接操作应用于所有节点表示和所有边,形式为:(我个人觉得公式9表达的不是很准确,按照文字介绍应该是卷积后的内容连接形成R,但是公式这么表达感觉更像是关系表达矩阵直接连接成R,有向作者求证,但是没回我……要是好心人知道一定要告诉我……)
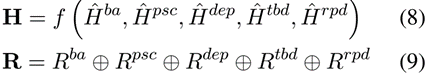
其中 H = {h1, h2, ..., hn} 和 R = {r1,1, r1,2, ..., rn,n} 表示词对的节点表示和边表示。
5)关系约束
为了精确捕捉单词之间的关系,对从双仿射模块获得的相邻张量施加约束,即:
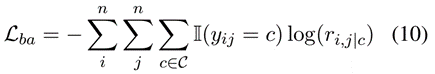
其中||(·)表示指示函数,yij是词对(wi,wj)的真实值,C表示关系集。同样,对语言特征产生的四个相邻张量施加关系约束。约束代价表示为 Lpsc、Ldep、Ltbd 和 Lrpd。
6)精炼策略和预知层
为了获得用于标签预测的词对 (wi, wj) 的表示,将它们的节点表示 hi、hj 和它们的边表示 rij 连接起来。此外,受多标签分类任务中的分类器链(Read et al., 2011)方法的启发,设计了一种有效的精炼策略,在判断词对是否匹配时考虑方面和观点提取的隐含结果。具体来说,假设wi是方面项中的一个词,wj是观点项中的一个词,那么词对(wi, wj)更有可能被预测为情感关系,即POS、NEU或NEG,否则,它们不太可能匹配。因此,我们引入 rii 和 rjj 来精炼词对 (wi, wj) 的表示 sij,即:
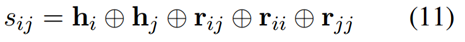
最后,我们将词对表示 sij 输入线性层,然后使用 softmax 函数生成标签概率分布 pij,即:
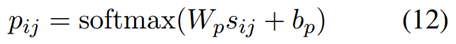
5损失函数
最小化目标函数:
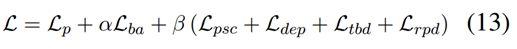
其中系数α和β用于调整对应关系约束损失的影响。ASTE任务的标准交叉熵损失为Lp,即:
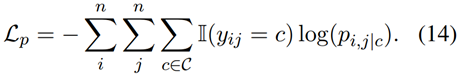
五 实验
1数据集
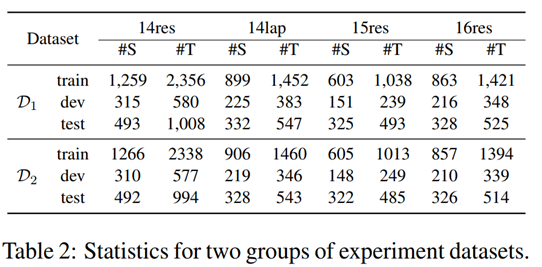
在两个 ABSA 数据集上评估。这两个数据集来自 SemEval ABSA 挑战赛 (Pontiki et al., 2014, 2015, 2016)。第一个数据集 D1 来自 Wu et al.(2020a)第二个数据集 D2由 Xu et al.(2020)注释,这是 Peng et al(2020)提出的数据集的修正版本。这两组数据集的统计数据如表2所示。
2实验参数设置
使用 BERT-base-uncased version 作为句子编码器。AdamW 优化器(Loshchilov 和 Hutter,2018)用于 BERT 微调的学习率为 2×10-5,其他可训练参数的学习率为 10-3。Dropout比例设置为 0.5。 BERT和GCN的隐藏维数分别设置为768和300。EMC-GCN模型在 100 个循环中训练,批量大小为16。为了控制关系约束的影响,我们将超参数α和β 分别设置为0.1和0.01。请注意,由于提出的关系约束,通道数等于我们定义的关系数,这是不可变的。所有句子都由 Stanza (Qi et al., 2020) 解析。我们保存模型参数根据模型在开发集上的最佳性能。报告的结果是使用不同随机种子的五次运行的平均值。
3实验结果
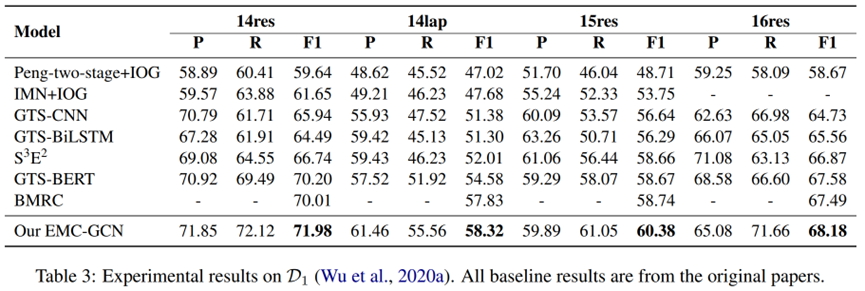
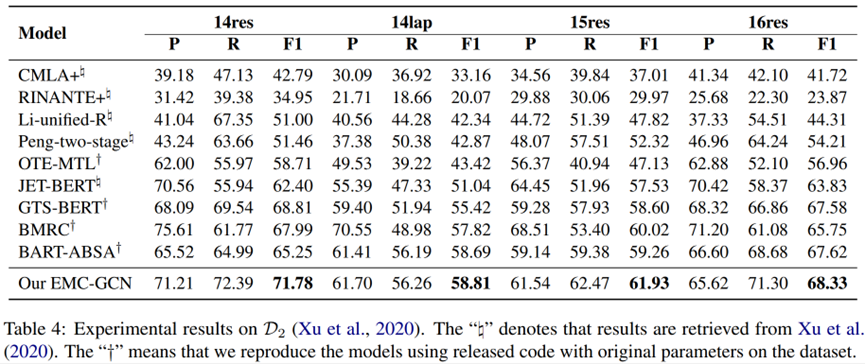
主要实验结果见表 3 和表 4。在 F1 指标下,EMC-GCN 模型在两组数据集上优于所有管道、端到端和基于MRC 的方法。观察到端到端和基于 MRC 的方法比流水线方法取得了更显着的改进,因为它们建立了这些子任务之间的相关性,并通过联合训练多个子任务来缓解错误传播的问题。请注意,OTE-MTL 和 GTS-BERT 的标记方案类似于表格填充。与 GTS-BERT 相比,EMC-GCN 在 D1 和 D2 上的 F1 分数分别超了1.96% 和 2.61%。这种改进归因于EMC-GCN可以利用单词和语言知识之间的关系进行单词表示学习。另一个发现是那些使用BERT编码器的方法,例如 JETBERT、GTS-BERT 和 BMRC,通常比使用 BiLSTM 编码器的方法获得更好的性能。原因可能是BERT已经在大规模数据上进行了预训练,可以提供强大的语言理解能力。
4模型分析
1消融实验
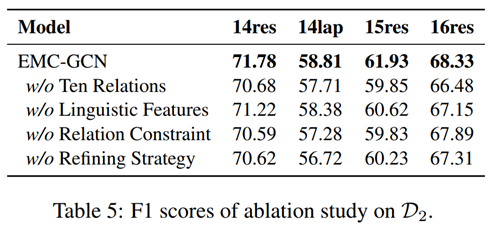
为了研究 EMC-GCN 中不同模块的有效性,对第二个数据集 D2 进行了消融研究。实验结果如表 5 所示。w/o Ten Relations表示 EMC-GCN 使用与 GTS(Wu et al,2020a)相同的标记模式,具有六个标签,没有四个关系{B-A, I-A, B-O, I-O},EMC-GCN 丢失术语的边界信息,性能显着下降。w/o Linguistic Features 意味着从EMC-GCN中删除了四种类型的功能,在没有增强语言特征的情况下,EMC-GCN 的性能在 14res 和 14lap 上略有下降,但在 15res 和 16res 上分别下降了 1.31% 和 1.18%,由于 15res 和 16res 包含的训练数据较少,当训练数据不足时,语言特征可以提供额外的信息,这有助于模型的预测。 w/o Relation Constraint 表示移除了邻接张量Rba和标签之间的关系约束损失,因此,邻接张量中的每个通道都不能精确地描述单词之间的关系依赖,结果,EMC-GCN w/o Relation Constraint 在四个子数据集上的性能显着下降。 w/o Refining Strategy 表示我们从词对表示 sij 中去除了方面和观点提取rii 和 rjj 的隐含结果,由于邻接张量与标签有关系约束,可以假设 rii 是主对角线上单词对 (wi, wi) 的预测标签或关系概率分布,因此,可以利用方面和观点提取的隐含结果作为先验信息来帮助预测词对 (wi, wj) 的标签。总而言之,EMC-GCN 的每个模块都有助于 ASTE 任务的整体性能。
2精炼策略的影响
精炼策略的目的是促进基于方面和观点提取隐含结果的词对匹配过程。为了验证这个想法,在 D2 的 14rest 和 14lap 上对三种情感关系 {POS, NEU, NEG} 进行了比较实验。结果如表 6 所示。请注意,三种情感关系的功能是检测词对是否匹配,并识别方面-观点对的情感极性。结果表明,w/o Refining Strategy 的性能显着下降,该精炼策略与我们期望的一样有效。
3通道可视化
为了研究单词之间关系的影响,可视化了与特定关系相对应的邻接张量 Rba 的通道切片。考虑示例句子,“air has higher resolution but the fonts are small. ”来自 14lap 数据集。这个句子包含两个三元组,{(resolution, Higher, POS), (fonts, small, NEG)}。如图 5 左侧所示,“higher”和“resolution”的可视化邻接信息对应于 POS 关系通道。在可视化中,“Higher”和“resolution”是高度相关的。结果,他们将自己的信息传达给对方。同样,在图 5 的右侧,“fonts”可以接收到 NEG 关系通道中“small”的节点表示和负面情绪。同时,“small“也可以获得它所描述的观点目标的信息。因此,EMC-GCN 模型可以很容易地预测单词对(“fonts”、“small”)和(“resolution”、“higher”)的正确标签。

4语言特征可视化
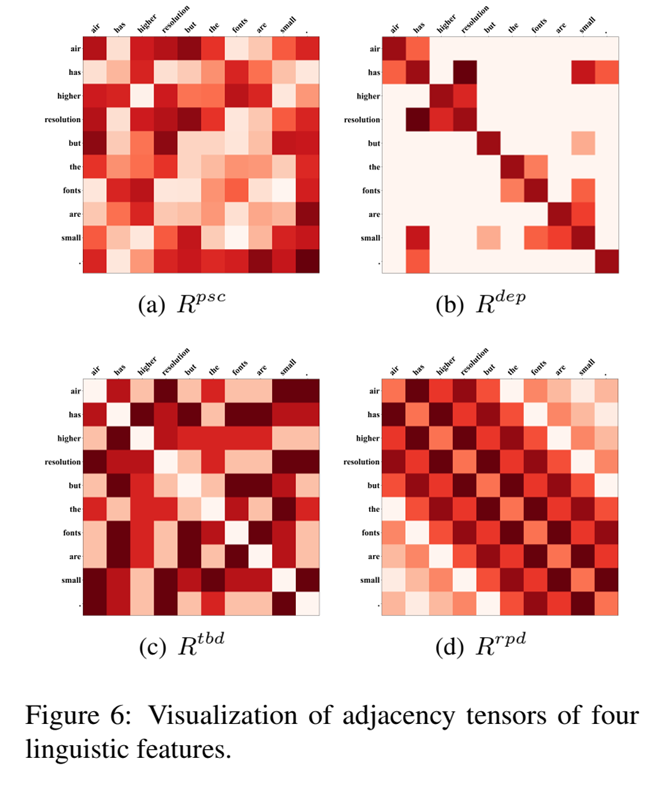
为了进一步分析语言特征在 ASTE 任务中的作用,可视化了四种语言特征的邻接张量。使用邻接张量中特征向量的L2范数来表示对应词对的相关性得分。在图 6 中,第一个是从词性组合特征中可视化的邻接张量 Rpsc,我们观察到形容词和名词之间的得分更高,因为形容词和名词之间很容易形成一个aspect-opinion 对,而形容词之间的得分较低,因为这两个形容词通常不相关,并且很可能相互干扰。在 Rdep 的可视化中,发现每个词只与它直接依赖的词有一个分数,并根据不同的句法依赖类型计算不同的相关性分数。 Rtbd 的可视化显示每个单词与其他单词在不同的基于树的距离处计算的相关性分数。 Rrpd 的可视化表明两个相邻词的相关性大于远距离词对的相关性。总之,设计的所有语言特征都有助于 ASTE 任务。
5案例研究
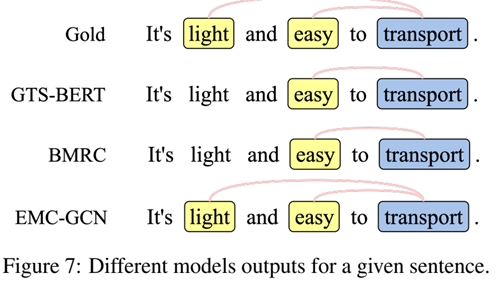
图 7 给出了一个案例研究。在此示例中,方面词和观点词分别以蓝色和黄色突出显示。红线表示aspect term和opinion term匹配,并形成一个带有正面情绪的三元组。 GTS-BERT 和 BMRC 很难识别观点术语“轻”,而所有方法都正确预测“easy”,因为“light”比“easy”更远离“transport”。因此,他们忽略了三元组(“transport”、“light”、positive),而EMC-GCN 可以精确地提取它。关键因素可能是“light”和“transport”可以通过情感关系和语言特征建立重要的联系。
六 总结和未来展望
本文提出了一种用于 ASTE 任务的 EMC-GCN 架构。为了利用单词之间的关系,首先设计了一个多通道图结构,用于对每个单词对的不同关系类型进行建模。然后,在所有通道上利用图卷积运算来学习关系感知节点表示。此外,考虑语言特征来增强基于GCN的模型。最后,在EMC-GCN上设计了一种有效的精炼策略,以更好地提取三元组。对基准数据集的广泛实验表明,EMC-GCN 模型始终优于所有基准。未来,我们将分析语言特征的作用及其组合的效果。