1 合并数据集
pandas.merge
pandas.merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'), copy=True, indicator=False, validate=None)
import pandas as pd from pandas import DataFrame df1 = DataFrame({'key':['b','b','a','c','a','a','b'],'data1':range(7)}) df2 = DataFrame({'key':['a','b','d','b'],'data2':range(4)}) # pd.merge(df1,df2,on='key')#设定列进行连接 # pd.merge(df1,df2,left_on='data1',right_on='data2') # pd.merge(df1,df2,how='outer')#外连接,求取的是键的并集 # pd.merge(df1,df2,on='key',how='left')#左连接 # pd.merge(df1,df2,on='key',how='right')#右连接 # pd.merge(df1,df2,on='key',how='inner')#内连接,求取的是键的交集 # pd.merge(df1,df2,left_index=True,right_index=True)#索引被用作连接键
merge函数的参数

轴向连接
pandas.concat
pandas.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, sort=None, copy=True)
其中axis=0表示行,axis=1表示列
Series
s1 = Series([0,1],index=['a','b']) s2 = Series([2,3,4],index=['c','d','e']) s3 = Series([5,6],index=['f','g']) s4 = pd.concat([s1*5,s3])#concat默认axis=0,所以得出的是新的Series,取并集;axis=1,所以得出的是新的DataFrame # pd.concat([s1,s4],axis=1,sort=False,join='outer')#axis=1 表示针对列,join='outer'表示取并集 # pd.concat([s1,s4],axis=1,sort=False,join='inner')#axis=1 表示针对列,join='inner'表示取交集 # pd.concat([s1,s4],axis=1,sort=False,join_axes=[['a','c','b','e']])#指定索引 # result = pd.concat([s1,s2,s3],keys=['one','two','three']) result = pd.concat([s1,s2,s3],axis=1,sort=False,keys=['one','two','three'])
DataFrame
类似,略。
合并重叠数据
combine_first()方法
s1.combine_first(s2)
df1.combine_first(df2)
2 重塑和轴向旋转
reshape
pivot
重塑层次化索引
stack:将数据的“列”旋转为“行”
unstack:将数据的“行”旋转为“列”
3 数据转换
移除重复数据
import pandas as pd from pandas import DataFrame,Series s1 = Series(['a','a','a'],index=['i1','i2','i3']) s2 = Series(['a','a','a'],index=['i1','i2','i3']) df = pd.concat([s1,s2],axis=1,sort=False) df
运行结果:

df.duplicated()#返回一个布尔类型的Series
运行结果:

df.drop_duplicates()#移除全部列重复行的数据,默认保留第一个出现的值
df.drop_duplicates(take = True)#移除全部列重复行的数据,默认保留最后一个值
运行结果:

import pandas as pd from pandas import DataFrame,Series s1 = Series(['a','a','a'],index=['i1','i2','i3']) s2 = Series(['a','b','a'],index=['i1','i2','i3']) df = pd.concat([s1,s2],axis=1,sort=False,keys=['key1','key2']) df.drop_duplicates('key2')
运行结果:

df.drop_duplicates('key2')#移除指定列重复行的数据
运行结果:
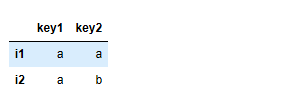
利用函数或映射进行数据转换
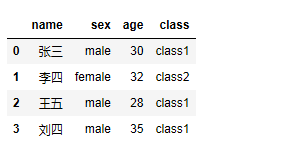
import pandas as pd from pandas import DataFrame,Series data = DataFrame({'name':['张三','李四','王五','刘四'],'sex':['male','female','male','male'],'age':[30,32,28,35]}) student_to_class = {#比如,男性的班级是class1,女性的班级是class2 'male':'class1', 'female':'class2' } data['class'] = data['sex'].map(person_to_class) data
运行结果:
替换值
fillna()
map(参数),可以接收一个函数或含有映射关系的字典型对象
replace(参数1,参数2),参数1表示被替换的值,可以是一个值,也可以是多个值,参数2表示替换值
轴索引重命名
DataFrame 有map函数,DataFrame的index也有个map函数
df.index.map()
离散化和面元划分
pd.cut()
开区间、闭区间,通过right=False或True,left=False或True 进行控制
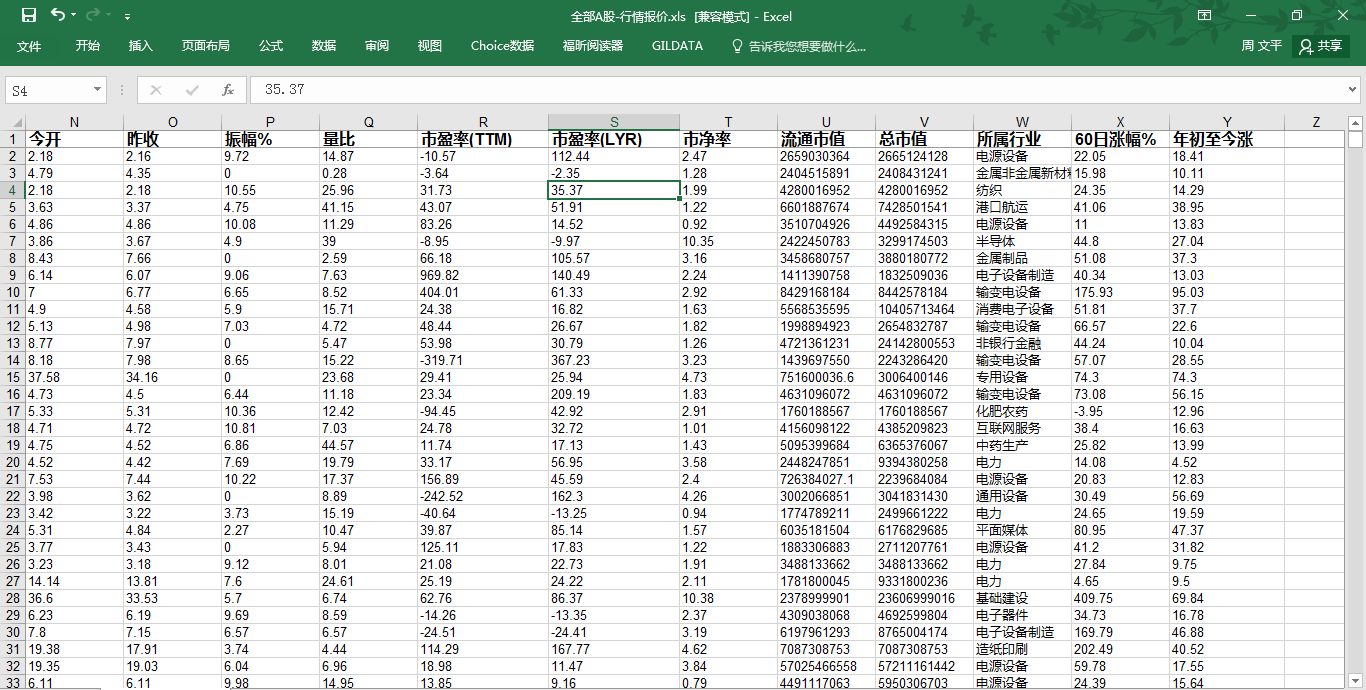
统计市盈率区间分布情况:
import pandas as pd import numpy as np from numpy import array file = 'D:全部A股-行情报价.xls' df = pd.read_excel(file) region = [-100,-50,-30,-20,-10,0,10,20,30,50,100] regions = np.array(region) ratio = df['市净率'].dropna() arrs = np.array(ratio) ratios = pd.cut(ratio,regions) pd.value_counts(ratios)

提示:(0,10] 3481,表示市盈率在(0,10] 的股票有3481只。
ratios = pd.cut(ratio,regions,labels=['非常非常不好','非常不好','不好','很一般','一般一般','一般好','好','很好','非常好','非常非常好'])
