学习一门语言首先hello world
1,首先建立一个目录,新建一个hello.go的文件
package main
import (
"fmt"
)
func main() {
fmt.Println("hello world")
}
2,go run hello.go
jack_zhou@zhoulideMacBook-Pro study % go run hello.go
hello world
上面我们就完成了我们的基础使命。下面我们正式开始入门
在正式进入写代码之前,推荐大家使用JB家族的Goland
在设置中需要注意GOPATH和GOROOT不能写同一个地址,否则会报错:
warning: GOPATH set to GOROOT (/usr/local/go) has no effect
一,入门篇
1,golang语言特性
① 垃圾回收
- 内存自动回收,不需要开发人员管理内存
- 开发人员只需关注业务实现,降低负担
- 只需new分配内存,不需要释放
② 天然并发
- 从语言层面支持并发,非常简单
- goroute,轻量级线程,创建成千上万个goroute成为可能
- 基于CSP(Communicating Sequential Process)模型实现
③ 管道(channel)
- 管道,类似unix/linux中的pipe
- 多个goroute之间通过channel进行通信
- 支持任何类型
④ 多返回值
- 定义函数返回类型需要加括号
- 返回需要以,作为分隔
⑤ 需要编译
go build + 路径
2,变量的定义:
# 第一种package变量
var (
a = 1
b = 2
)
var aa = true
# 第二种非package变量
var a, b int = 1, 2
# 简写
var a,b = 1, "89"
# 精简
a, b := 1, "78" // 全局不可使用
在上一个例子的基础上写一个加法函数,传入两个变量,返回两个参数之和
package main
import (
"fmt"
)
func add(a int, b int) int {
var sum int
sum = a + b
return sum
}
func main() {
var c int
c = add(100, 200)
fmt.Println("hello world!", c)
}
在上述例子中,我们可以看到,他是没有封号的
在定义变量的时候需要指定比变量的类型,定义函数的时候,在()外需要写上返回值的类型
需要注意的是,go不容许定义变量而不使用的情况发生,否则编译的时候就会报错,比如:
c declared and not used
3,包的定义
- 和Python语言,把相同功能代码放到一个目录中,称之为包(因此,在写代码的时候都需要写package 包名)
- 包当然支持被其他包的引用
- main包是用来生成可执行文件,每一个程序有且只能有一个main包
- 包的主要用途是提高代码的可复用性
4,注意事项
① Go 进行build的时候经常会遇到 can't load package
在Goland中配置

需要加上Project GOPATH 路径
② Go新建项目默认需要在src下,并且,编译的时候不需要将src路径写入
go默认所有的项目文件都放在src目录下面
在project目录下执行go build go_test/day1/example即可
③ 一般build文件都指定在一个bin目录
go build -o bin/calc go_dev/day1/package_count/main
用 -o 来指定目录bin,文件为calc,编译的是main
④ 关于new和make的使用区别
Go语言中new和make是内建的两个函数,主要用来创建分配类型内存。在我们定义生成变量的时候,可能会觉得有点迷惑,其实他们的规则很简单,下面我们就通过一些示例说明他们的区别和使用
变量的声明:
var i int
var s string
变量的声明我们可以通过var关键字,然后就可以在程序中使用。当我们不指定变量的默认值时,这些变量的默认值是他们的零值,比如int类型的零值是0,string类型的零值是"",引用类型的零值是nil。
对于例子中的两种类型的声明,我们可以直接使用,对其进行赋值输出。但是如果我们换成引用类型呢?
package main
import (
"fmt"
)
func main() {
var i *int
*i = 10
fmt.Println(*i)
}
panic: runtime error: invalid memory address or nil pointer dereference
从这个提示中可以看出,对于引用类型的变量,我们不光要声明它,还要为它分配内容空间,否则我们的值放在哪里去呢?这就是上面错误提示的原因。
对于值类型的声明不需要,是因为已经默认帮我们分配好了。
要分配内存,就引出来今天的new和make。
1, new
对于上面的问题我们如何解决呢?既然我们知道了没有为其分配内存,那么我们使用new分配一个吧
package main
import (
"fmt"
)
func main() {
var i *int
i = new(int)
*i = 10
fmt.Println(*i)
}
我们进入new的源码中看一下:
func new(Type) *Type
它只接受一个参数,这个参数是一个类型,分配好内存后,返回一个指向该类型内存地址的指针。同时请注意它同时把分配的内存置为零,也就是类型的零值。
我们的例子中,如果没有*i=10,那么打印的就是0。这里体现不出来new函数这种内存置为零的好处,我们再看一个例子。
package main
import (
"fmt"
"sync"
)
func main() {
u := new(user)
u.lock.Lock()
u.name = "张三"
u.lock.Unlock()
fmt.Println(u)
}
type user struct {
lock sync.Mutex
name string
age int
}
示例中的user结构体类型中的lock字段我不用初始化,直接可以拿来用,不会有无效内存引用异常,因为它已经被零值了。
这就是new,它返回的永远是类型的指针,指向分配类型的内存地址。
2, make
make也是用于内存分配的,但是和new不同,它只用于chan、map以及切片的内存创建,而且它返回的类型就是这三个类型本身,而不是他们的指针类型,因为这三种类型就是引用类型,所以就没有必要返回他们的指针了。
注意,因为这三种类型是引用类型,所以必须得初始化,但是不是置为零值,这个和new是不一样的。
func make(t Type, size ...IntegerType) Type
从函数声明中可以看到,返回的还是该类型。
3, 两者的异同
所以从这里可以看的很明白了,二者都是内存的分配(堆上),但是make只用于slice、map以及channel的初始化(非零值);
而new用于类型的内存分配,并且内存置为零。所以在我们编写程序的时候,就可以根据自己的需要很好的选择了。
make返回的还是这三个引用类型本身;
而new返回的是指向类型的指针。
所以有new这个内置函数,可以给我们分配一块内存让我们使用,但是现实的编码中,它是不常用的。我们通常都是采用短语句声明以及结构体的字面量达到我们的目的,比如:
i := 0
u := user{}
这样更简洁方便,而且不会涉及到指针这种比麻烦的操作。
make函数是无可替代的,我们在使用slice、map以及channel的时候,还是要使用make进行初始化,然后才才可以对他们进行操作。
5,go的基本类型
① 文件名&关键字&标识符
-
[x] 所有源码以.go结尾
-
[x] 标识符以字母或者下划线开头,大小写敏感(_)
-
[x] _是特殊标识符,用来忽略结果
-
[x] 保留关键字
break default func interface select case defer go map struct chan else goto package switch const fallthrough if range type continue for import return var
② Go程序基本结构
-
任何一个代码文件隶属于一个包
-
import 关键字,引用其他包
import ("fmt") import ("os") // 通常写为 import ( "fmt" "os" ) -
Golang 可执行程序,package main,并且有且只有一个main函数入口
-
包内函数调用,直接调用
-
不同包内调用函数,需要通过包名 + 点 + 函数名进行调用(函数名首字母必须大写)
package main import "fmt" func list(n int) { for i := 0; i <= n; i++ { fmt.Println("%d+%d=%d ", i, n-i, n) } } func main() { list(10) } // 打印循环
-
[x] 注意:在包中可以定义一个init函数,默认会在main执行之前执行
package calc var Name string = "jack" var Age int = 10 func init() { Name = "zhou" Age = 100 } // 最终结果是Name为zhou,Age为100 // 执行顺序 先执行全局变量,在执行init,最后到main
③ 常量和变量
一,常量
-
常量使用const修饰,代表永远是只读的,运行期间不能够修改
-
const只能修饰boolean,number(int相关类型、浮点类型、cpmplex)和string
-
常量的特殊类型是是枚举类型
func news() { const ( cpp = iota _ python golang javascript ) // 复杂用法 b, kb, mb, gb, tb, pb const ( b = 1 << (10 * iota) kb mb gb tb pb ) fmt.Println(cpp, python, golang, javascript) fmt.Println(b, kb, mb, gb, tb, pb) } -
语法:const identifier [type] = value,其中type可以省略。
const b string = "hello world" const b = "hello world" const Pi = 3.1415926 const a = 9.3 const c = getValue() // 错误,因为常量是不可改变的 -
单行注释 // 多行注释 /* */(其实和JS的写法一致的)
二,变量
见上方变量的定义
④ 数据类型和操作符
一,数据类型
值类型: 基本数据类型int,float, bool, string以及数组和struct
当值类型需要修改的时候 传入值之前加一个&即可,比如:
modify(a) ---->>> modify(&a)
这样就相当于传入a的内存地址到modify中去
引用类型: 指针,slice,map, chan等都是引用类型
二,操作符
-
逻辑操作符
== 、!=、<=、>=、>、<、!、&&、 ||
func main() { a := 10 if (a > 2) { fmt.Println(a) } } -
数学操作符
+、-、*、/ 等等
⑤ 字符串类型
func main() {
var str = "hello world
"
var str1 = `
窗前明月光,
地上鞋两双。
`
var b byte = 'c'
fmt.Println(str)
fmt.Println(str1)
fmt.Println(b)
fmt.Printf("%c
", b)
}
go在进行输出的时候是不会改变原有的样式的,对于打印bytes对象,会直接打印对于字符表中的具体位置的
fmt文档:给您放这里啦
例子: 交换两个变量的值
package main
import (
"fmt"
_ "os"
)
func swap(a int, b int) {
tem := a
a = b
b = tem
return
}
func main() {
first := 100
second := 200
swap(first, second)
fmt.Println(first, second)
}
结果如下:
jack_zhou@zhoulideMacBook-Pro ~ % /Users/jack_zhou/workspace/gospace/project/main ; exit;
100 200
为啥没有产生变化呢?
因为这两个变量属于值类型的,值类型是属于复制拷贝,改的是副本的值,如果需要改就必须传入指针地址。那如何修改呢?
package main
import (
"fmt"
_ "os"
)
func swap(a *int, b *int) {
tem := *a
*a = *b
*b = tem
return
}
func main() {
first := 100
second := 200
swap(&first, &second) // 传入变量的地址
fmt.Println(first, second)
}
结果如下:
Last login: Sun Dec 8 22:55:57 on ttys002
jack_zhou@zhoulideMacBook-Pro ~ % /Users/jack_zhou/workspace/gospace/project/main ; exit;
200 100
package main
import (
"fmt"
_ "os"
)
func swap(a int, b int) (int, int) {
tem := a
a = b
b = tem
return a, b
}
func main() {
first := 100
second := 200
first, second = swap(first, second) // 传入变量的地址
fmt.Println(first, second)
}
通过返回值的方式也是可以的
最简单的方式是:
package main
import (
"fmt"
_ "os"
)
func main() {
first := 100
second := 200
first, second = second, first
fmt.Println(first, second)
}
写到这突然发现还是Python大法好啊╮( ̄▽ ̄)╭
⑥ 字符串的操作
-
直接相加
package main import "fmt" func main() { var str = "hello" var str2 = " world" str3 := str+str2 fmt.Println(str3) } -
格式化输出
package main
import "fmt"
func main() {
var str = "hello"
var str2 = " world"
// str3 := str+str2
str3 := fmt.Sprintf("%s %s", str, str2) // 格式化输出
fmt.Println(str3)
}
-
求字符串长度
package main import "fmt" func main() { var str = "hello" var str2 = " world" // str3 := str+str2 str3 := fmt.Sprintf("%s %s", str, str2) // 格式化输出 n := len(str3) fmt.Printf("len(str)=%d ", n) } -
字符串的切片
package main import "fmt" func main() { var str = "hello" var str2 = " world" // str3 := str+str2 str3 := fmt.Sprintf("%s %s", str, str2) // 格式化输出 substr := str3[0:5] // 和Python操作一致 fmt.Println(substr) } -
字符串反转
package main import "fmt" func reverse(str string) string { var result []byte tmp := []byte(str) // 强制转换字符数组 length := len(str) for i := 0; i < length; i++ { result = append(result, tmp[length-i-1]) } return string(result) } func main() { var str = "hello" var str2 = " world" str3 := str + str2 result := reverse(str3) fmt.Println(result) }
6,流程语句
① 条件语句
package main
import "fmt"
func bound(v int) int {
if v > 100 {
return 100
} else if v < 0 {
return 0
} else {
return v
}
}
func main() {
c := bound(6)
fmt.Println(c)
}
可以看到,和Python不同的是,go的if条件判断是需要加{}的,但是不同于JS的是条件部分不需要使用()
go语言规定与if匹配的左括号"必须与if和表达式放在同一行",否则编译错误给你看你信不信
go中关于流程控制有一个特殊写法,但是我认为非常方便
if err := Connect(); err != nil {
fmt.Println(err)
return
}
另外go中的条件语句可以返回多个值
package main
import (
"fmt"
"io/ioutil"
) // go语言下的读取库
func main() {
const filename = "abc.txt"
contents, err := ioutil.ReadFile(filename)
if err != nil {
fmt.Println(err)
} else {
fmt.Printf("%s
", contents)
}
}
当然可以简写为:
package main
import (
"fmt"
"io/ioutil"
) // go语言下的读取库
func main() {
const filename = "abc.txt"
if contents, err := ioutil.ReadFile(filename); err != nil {
fmt.Println(err)
} else {
fmt.Printf("%s
", contents)
}
}
示例如下:九九乘法表
package main
import "fmt"
func main() {
for y := 1; y <= 9; y++ {
for x := 1; x <= 9; x++ {
fmt.Printf("%d*%d=%d ", x, y, x*y)
}
fmt.Println()
}
}
遍历数组、切片——获得索引和元素
package main
import "fmt"
func main() {
a := [5]int{1, 2, 3, 4, 5}
// a := []int{1, 2, 3, 4, 5}
for index, value := range a {
fmt.Println(index, value)
}
}
遍历字符串——获得字符串
package main
import (
"fmt"
"string"
)
func main() {
a := "中国ts"
// a := []int{1, 2, 3, 4, 5}
for index, value := range []rune(a) {
fmt.Println(index, string(value))
}
}
遍历map对象(如果需要顺序输出的话,需要先对结果进行排序)
package main
import "fmt"
func main() {
a := make(map[string]int)
a["a"] = 1
a["b"] = 2
a["c"] = 3
for k, v := range a {
fmt.Printf("键为:%s,值为:%d", k, v)
}
}
遍历通道channel ——用于接收通道数据
for range 可以遍历通道(channel),但是通道在遍历时,只输出一个值,即管道内的类型对应的数据。
package main
import "fmt"
func main() {
c := make(chan int)
go func() { // 启动go 的线程
c <- 1
c <- 2
c <- 3
close(c)
}() // 立刻执行
for v := range c {
fmt.Println(v)
}
}
② switch语句
Switch是用于替代多个条件下的if else 语句的,为什么这么说呢?
因为在涉及到多个分支的时候,使用case来直接判断,符合哪一个就走哪一个
最后default用于什么都不满足的情况下!也就是else。
func eval(a, b int, op string) int {
var result int
switch op {
case "+", "--": // 多个条件等于等于 if op in ("+", "--")
result = a + b // 判断成功后不需要break也不会继续向下走
case "-":
result = a - b
fallthrough // 会让这一段执行后继续向下判断
case "/":
result = a / b
case "*":
result = a * b
default:
panic("unsupported operator:" + op) // 相当于Python的raise(报错)
}
return result
}
go和Java不同的是:
switch不需要手动写break(但break会让switch提前终止),除非使用fallthrough(这会让分支继续向下执行)
重点关注:panic
那么现在面临一个问题,假如我需要对成绩大于90分的学生打A
func grade(score int) string {
g := ""
switch {
case score > 100 || score <= 0:
panic(fmt.Sprintf("错误成绩:%d", score))
case score > 90:
g = "A"
case score > 80:
g = "B"
case score > 60:
g = "c"
}
return g
}
在第一段中的case其实替代了的defult
可以看到的是:在条件语句中switch便不再需要跟上判断变量
当然在switch中还是可以用case通过都好分隔来列举相同的处理条件(记住:多条件不可使用双引号*)**
func op(c byte) bool {
switch c {
case " ", "?", "=", "-", "&":
return true
}
return false
}
7,循环语句
注意:go中是没有while的
① for循环
for + 初始化语句 + 条件判断(结束条件)+ 变量修改表达式
func sums(a) int {
sum := 0
for i := 1; i <= a; i++ {
sum += i
}
return sum
}
- for循环的条件里不需要括号
- for的条件里可以省略初始条件,结束条件,递增表达式
- 省略初始条件,相当于while
写个例子:生成一个字母直角三角形:
package main
import "fmt"
func Print(n int) {
for i := 1; i < n+1; i++ {
for j := 0; j < i; j++ {
fmt.Printf("A")
}
fmt.Println()
}
}
func main() {
Print(6)
}
我们知道字符串其实就是一个数组,那么我们的for循环可以这样使用
package main
import "fmt"
func Print() {
var str = "hello world, 我是中国人!"
for i, v := range str {
fmt.Printf("index[%d] val[%c]
", i, v)
}
}
func main() {
Print()
}
加上continue和break
package main
import "fmt"
func Print() {
var str = "hello world, 我是中国人!"
for i, v := range str {
if i < 1 {
continue
}
if i > 4 {
break
}
fmt.Printf("index[%d] val[%c]
", i, v)
}
}
func main() {
Print()
}
非重头戏来了:goto和label语句:label的语法本质上就是一个大写的字母串加冒号
就是当你在某个位置设置了LABEL,循环到continue后加LABEL名的位置会自动跳到LABEL位置处
看个例子:
package main
func Print() {
LABEL1:
for i := 0; i < 6; i++ {
for j := 0; j < 5; j++ {
if j == 3 {
continue LABEL1
/*
当j==3时,按照道理而言应该下面执行j=4,但是加了LABEL语句后就会跳到LABEL1处,
如果是break的话就会直接停止循环
执行最外侧的for循环语句
*/
}
}
}
}
func main() {
Print()
}
当然goto之后也会加label的,一般不建议使用goto,因为代码可读性会变差
那么goto的优势在于什么?
func main() {
err := firstCheckEror()
if err != nil {
fmt.Println(err)
exitProcess()
return
}
err = secondCheckError()
if err != nil {
fmt.Println(err)
exitProcess()
return
}
fmt.Println("done")
}
我们可以看到这段代码中有重复,如果业务调整需要额外的进行判断的话,就需要在每一块雷同的代码中一次修改。极容易造成错误
那这一段就可以改成goto
package main
import "fmt"
func main() {
err := firstCheckEror()
if err != nil {
goto ONEXIT
}
err = secondCheckError()
if err != nil {
goto ONEXIT
}
fmt.Println("done")
return
ONEXIT:
fmt.Println(err)
exitProcess()
}
对于Python而言**:更简洁化,使用range来替代这些步骤(还是Python大法好)
8,函数
go函数的特点:
① 不支持重载,一个包不能有两个名字一样的函数
② 函数式一等公民,函数也是一种类型,一个函数可以赋值给变量
看一个例子:
package main
import "fmt"
func add(a, b int) int {
return a + b
}
func main() {
c := add
fmt.Println(c)
sum := c(10, 30)
fmt.Println(sum)
}
可以看出上个例子中将函数add赋值给c,并且使用c传参得到正确的结果
进而可以进行引申
package main
import "fmt"
type add_func func(int, int) int // 用type自定义的函数类型(名称不会有限制)
func add(a, b int) int {
return a + b
}
func operator(op add_func, a int, b int) int {
return op(a, b)
}
func main() {
c := add
fmt.Println(c)
sum := operator(c, 100, 200)
fmt.Println(sum)
}
函数传递方式:
- 值传递(基本的数据类型)
- 引用传递(map、chan、slice、指针、interface)
注意:无论是值传递,还是引用传递,传递给函数的都是变量的副本(也就是仅仅传递值),不过,值传递是值得拷贝,而引用传递是地址的拷贝,一般来说,地址拷贝更为高效。而值拷贝取决于拷贝的对象大小,对象越大,那么性能越低。
③ 匿名函数
匿名函数的定义格式如下:
func(参数列表) (返回参数列表) {
函数体
}
-
在定义时调用匿名函数:
func (data string) { fmt.Println(data) }("我是谁") // 括号表示对匿名函数进行调用,参数为我是谁 -
将匿名函数赋值给变量
f := func(data int) { fmt.Println("编号", data) } f(9527) -
将匿名函数作为回调函数,go的源码中比较常见
package main import "fmt" func visit(list []int, f func(int)) { for _, v := range list { f(v) } } func main() { visit([]int{1, 2, 3, 4, 5}, func(v int) { fmt.Println(v) }) // 传入匿名函数 } -
使用匿名函数实现操作封装
package main import ( "flag" "fmt" ) var skillParam = flag.String("skill", "", "skill to perform") func main() { flag.Parse() var skill = map[string]func(){ "fire": func() { fmt.Println("fire") }, "run": func() { fmt.Println("run") }, "fly": func() { fmt.Println("fly") }, } if f, ok := skill[*skillParam]; ok { f() } else { fmt.Println("skill not found") } }
go run main.go --skill=fly
④ 多返回值(可命名,免去了return后写那么多)
package main
import "fmt"
func add(a, b int) (c int) {
c = a + b
return
}
func main() {
c := add(10, 2)
fmt.Println(c)
}
Go和Python一样的是函数和方法可以返回多个值
可以看一个例子中关于这样做的好处
func main() {
const filename = "abc.txt"
if contents, err := ioutil.ReadFile(filename); err != nil {
fmt.Println(err)
} else {
fmt.Printf("%s
", contents)
}
}
看一下go的ReadFile的源码:
func ReadFile(filename string) ([]byte, error) {
f, err := os.Open(filename)
if err != nil {
return nil, err
}
defer f.Close()
// It's a good but not certain bet that FileInfo will tell us exactly how much to
// read, so let's try it but be prepared for the answer to be wrong.
var n int64 = bytes.MinRead
if fi, err := f.Stat(); err == nil {
// As initial capacity for readAll, use Size + a little extra in case Size
// is zero, and to avoid another allocation after Read has filled the
// buffer. The readAll call will read into its allocated internal buffer
// cheaply. If the size was wrong, we'll either waste some space off the end
// or reallocate as needed, but in the overwhelmingly common case we'll get
// it just right.
if size := fi.Size() + bytes.MinRead; size > n {
n = size
}
}
return readAll(f, n)
}
我们可以看到函数的返回值有两个
- byte类型的数组
- error读取错误时候的错误信息
好,那么现在我们从头开始
⑤ 函数的定义:
func op(c byte) bool {
switch c {
case ' ', '?', '=', '-', '&':
return true
}
return false
}
定义方式为:
func + 函数名 + (参数 参数类型, 参数 参数类型) + 返回值类型(多返回值需要用括号包含起来)
当然返回值也是可以指定返回的值
func + 函数名 + (参数 参数类型, 参数 参数类型) + (返回值 返回值类型)
func op(c byte) (q bool) {
switch c {
case ' ', '?', '=', '-', '&':
return true
}
return false
}
那么问题来了,我们既然知道可以返回值得话,就可以定义两个返回值的值,一个是结果,一个是错误时候返回的结果
func eval(a, b int, op string) (int, error) {
switch op {
case "+":
return a + b, nil
case "-":
return a - b, nil
case "/":
return a / b, nil
case "*":
return a * b, nil
default:
return 0, fmt.Errorf("unsupported operator:" + op)
}
}
照常感慨一句:还是Python大法好
那这样做的好处在于,程序不会中断掉
package main
import (
"fmt"
) // go语言下的读取库
func eval(a, b int, op string) (int, error) {
switch op {
case "+":
return a + b, nil
case "-":
return a - b, nil
case "/":
return a / b, nil
case "*":
return a * b, nil
default:
return 0, fmt.Errorf("unsupported operator:" + op)
}
}
func main() {
if result, err := eval(9, 10, "&"); err != nil {
fmt.Println("error", err)
} else {
fmt.Println(result)
}
}
总结如下:
- 函数返回多个值时可以起名字
- 仅用于非常简单的函数
- 对调用者而言没有任何区别
函数变量:(把函数作为保存到变量中)
在Go语言中,函数也是一种类型。可以和其他类型一样保存到变量中
package main
import "fmt"
func fire() {
fmt.Println("我是火")
}
func main() {
var f func() // 将变量声明为func()类型,此时f就是回调函数。此时f为nil
f = fire // 将fire()作为值, 赋给f变量。此时f的值为fire()函数
f() //在此处相当于调用fire()
}
⑥ 函数的可变参数:
func add(arg ...int) (c int) { // 0个或多个参数
}
func add(a int, arg ...int) int { // 1个或多个参数
}
func add(a int, b int, arg ...int) int { // 2个或多个参数
}
注意:其中arg是一个slice,我们可以通过arg[index]依次访问所有参数,通过len(arg)来判断参数传递的个数
举个例子:求和
package main
import "fmt"
func add(a int, arg ...int) int { // 1个或多个参数
var sum int = a
for i := 0; i < len(arg); i++ {
sum += arg[i]
}
return sum
}
func main() {
//sum := add(10)
//sum := add(10, 3)
sum := add(10, 3, 6)
fmt.Println(sum)
}
⑦ defer用途
-
当函数返回时,执行defer语句。因此,可以用来做资源的清理(数据库连接等等)
-
关闭文件句柄
func read() { file := os.Open(filename) defer file.Close() } -
锁资源释放
func read() { mc.Lock() defer mc.Unlock() }
这个不得不承认,比Python爽啊。妈妈再也不会忘了解锁了
但是注意这种情况可能不会被释放掉:
func read() { file, err := os.Open(filename) if err != nil { return } defer file.Close() }如果提前返回了,那么就会到值直接return了,没走到定义defer的地方呢,所以defer定义要趁早!
-
-
多个defer语句。按照先进后出的方式执行(按照栈的方式)
举个例子:
package main import "fmt" func main() { i := 0 defer fmt.Println(i) defer fmt.Println("second") i = 10 fmt.Println(i) } // result : 10 second 0 -
defer语句中的变量,在defer声明时就决定了。
举个例子:
package main import "fmt" func main() { i := 0 defer fmt.Println(i) i = 10 fmt.Println(i) } // result : 10 0
⑧ 处理错误
go语言对于错误的处理思想特点有二:
- 一个可能造成错误的函数,需要返回值中返回一个错误接口(error)。如果调用时成功的,错误接口将返回nil,否则返回错误。
- 在函数调用后需要检查错误,如果发生错误,进行必要的函数处理。
Go希望开发者将错误处理视为正常开发必须实现的环节,正确处理每一个可能发生的错误的函数,同时Go语言使用返回值返回错误的机制,也能大幅降低运行时处理错误的复杂度,让开发者真正的掌握错误的处理。
1, net包中的例子
net.Dial()是Go语言系统包net的一个函数,一般用于创建一个Socket连接。
net.Dial拥有两个返回值,也就是Conn和error。这个函数时阻塞的,因此在Socket操作后,会返回Conn连接对象和error;如果发生错误,error就会告知错误类型,Conn会返回空。
根据Go的错误处理机制,Conn是其重要的返回值。因此,为这个函数增加一个错误返回,类似于error。如下:
func Dial(network, address string) (Conn, error) {
var d Dialer
return d.Dial(network, address)
}
在io包中的Reader接口也拥有错误返回,代码如下:
type Reader interface {
Read(p []byte) (n int, err error)
}
还有Closer接口,只有一个错误返回,代码如下:
type Closer interface {
Close() error
}
2, 错误接口的定义格式
error是Go系统声明的接口类型
type error interface {
Error() string
}
所有符合Error() string 格式的方法,都能实现错误接口
Error()方法返回错误的具体描述,使用者可以通过这个字符串知道发生了什么错误
3, 自定义一个错误
返回错误前,需要定义会产生哪些可能错误。在Go语言中,使用errors包进行错误定义,格式如下:
var err = errors.New("this is an error")
错误字符串由于相对固定,一般在包作用域声明,应尽量减少在使用时直接使用err.New返回
⑴ errors包
func New(text string) error {
return &errorString{text}
}
// errorString is a trivial implementation of error.
type errorString struct {
s string
}
func (e *errorString) Error() string {
return e.s
}
⑵ 在代码中使用错误定义
package main
import (
"errors"
"fmt"
)
var DivisionByZero = errors.New("被除数不能为空")
func div(dividend, divisor int) (int, error) {
// 判断除数为0的情况并返回
if dividend == 0 {
return 0, DivisionByZero
}
// 正常计算,返回空错误
return divisor / dividend, nil
}
func main() {
fmt.Println(div(0, 1))
}
4, 在解析中使用自定义错误
使用errors.New定义的错误类型是无法提供丰富的错误信息。那么如果需要携带错误信息返回,就需要借助自定义结构体实现错误接口。
下面代码将实现解析错误,这个错误包含了两个内容:文件名和行号。解析错误的结构还是先了error接口的Error()方法,返回错误描述时,就需要将文件名和行号一并返回。
package main
import "fmt"
type ParseError struct {
Filename string // 文件名
Line int // 行号
}
// 实现error接口,返回错误描述
func (p *ParseError) Error() string {
return fmt.Sprintf("%s:%d", p.Filename, p.Line)
}
// 创建一些解析错误
func newParseError(filename string, line int) error {
return &ParseError{filename, line}
}
func main() {
var e error // 声明错误接口类型
// 创建一个错误实例,包含文件和行号
e = newParseError("main.go", 1)
// 通过error接口查看错误描述
fmt.Println(e.Error())
// 根据错误接口的具体类型,获取详细的错误信息
switch detail := e.(type) {
case *ParseError:
fmt.Printf("Filenam:%s Line:%d
", detail.Filename, detail.Line)
default:
fmt.Println("other error")
}
}
⑨ 内置函数
-
close:主要用来关闭channel
-
len:用来求长度, 比如string、array、slice、map、channel
-
new:用来分配内存,主要用来分配值类型,比如int、struct。返回的是指针,也就是地址
package main import "fmt" func main() { var a int fmt.Println(a) // 0 b := new(int) fmt.Println(b) // 0xc000016058 } -
make:用来分配内存,主要用来分配引用类型,比如chan、map、slice
那么make和new的区别在什么地方呢?
package main import ( "fmt" ) func test() { s1 := new([]int) fmt.Println(s1) // &[] s2 := make([]int, 10) // 10是容量 fmt.Println(s2) // [0 0 0 0 0 0 0 0 0 0] return } func main() { test() } /* s1如果想被操作,必须要有经过make编程[],例如:*s1 = make([]int, 5), (*s1)[0] = 100 */ -
append:用来追加元素到数组、slice中
-
panic和recover:用来做错误处理
package main import ( "fmt" "time" ) func test() { if err := recover(); err != nil { // 做异常捕获 fmt.Println(err) alarm.Do() // 做报警处理逻辑 } b := 0 a := 100 / b fmt.Println(a) return } func main() { for { test() time.Sleep(time.Second * 2) } var a []int // 长度为6的数组,以后长度也不可改变 a = append(a, 10, 30, 34) a = append(a, a...) fmt.Println(a) }
最简单的方式还是直接改成panic方式
⑩ 递归函数
简单来说 一个问题可以拆分为等同逻辑的若干个小问题
package main
import "fmt"
func fab(n int) int {
if n == 1 {
return 1
}
return fab(n-1) * n
}
func main() {
fmt.Println(fab(5))
}
package main
import "fmt"
func test(n int) int {
fmt.Println("66666")
if n == 1 {
return 1
}
return test(n - 1)
}
func main() {
fmt.Println(test(5))
}
⑪ 闭包
package main
import "fmt"
func main() {
var f = Adder() // 此时的f已经变成函数,就差调用了
fmt.Print(f(1), "-----")
fmt.Print(f(20), "++++++")
fmt.Print(f(200), "_____+++")
} // 1-----21++++++221_____+++
func Adder() func(int) int {
var x int
return func(delta int) int {
x += delta
return x
}
}
闭包实现生成器:
闭包的记忆效应备用药实现类似设计模式中工厂模式的生成器。下面的例子展示创建一个玩家生成器的过程。
package main
import "fmt"
func playerGen(name string) func() (string, int) {
hp := 150 // 血量
// 返回创建的闭包
return func() (s string, i int) {
return name, hp // 将变量引用到比保重
}
}
func main() {
// 创建一个玩家生成器
generator := playerGen("zhou xian sheng")
// 返回玩家的名字和血量
name, hp := generator()
fmt.Println(name, hp)
}
⑫ 可变参数
再次之前,我们已经了解到函数传递可变参数的方法是使用...
具体格式如下:
func 函数名 (固定参数列表, v...T) (返回参数列表) {
函数体
}
特点:
- 一般情况下,可变参数放在函数列表的末尾
- v是可变参数变量,类型是[]T也就是切片,v和T之间由...连接
- T为可变参数的类型,当T为interface{}时,传入的可以是任意类型
那如何在多个可变参数函数中传递参数?
可变参数变量是一个包含所有参数的切片,如果要在多个可变参数中传递参数,可以在传递时候在可变参数变量中默认添加"...",将切片中元素进行传递,而不是传递可变参数变量本省。
package main
import "fmt"
func rawPrint(rawList ...interface{}) {
for _, a := range rawList {
fmt.Println(a)
}
}
func Print(sList ...interface{}) {
rawPrint(sList...)
}
func main() {
print(1, 2, 3, 4)
}
⑬ 宕机(panic)程序终止运行
go触发宕机相当简单panic(v interface{})
1, 在运行依赖的必备资源缺失时主动触发宕机
regexp是Go语言的正则表达式包,正则表达式需要编译后才能使用,而且编译必须是成功的,表示正则表达式可用。
编译正则表达式函数有两种,具体如下:
1. Func Compile (expr string) (*Regexp, error)
编译正则表达式,发生错误是返回编译错误,Regexp为nil,该函数适用于在编译错误是获得编译错误进行处理,同时继续后续执行的环境。
2.func MustCompile(str string) *Regexp
当编译正则表达式发生错误的时候,使用panic触发宕机,该函数适用于直接使用这则表达式而无需处理正则表达式错误的情况。
func MustCompile(str string) *Regexp {
regexp, error := Compile(str)
if error != nil {
panic(error.Error())
}
return regexp
}
2, 在宕机时触发延迟执行语句
package main
import "fmt"
func main() {
defer fmt.Println("one")
defer fmt.Println("two")
panic("error")
}
⑭ 宕机恢复(recover)防止程序崩溃
无论是代码运行错误有Runtime层抛出的panic崩溃,还是主动触发的panic崩溃,都可以配合defer和recover实现错误捕捉和恢复,让代码在发生崩溃后允许继续运行。
Go并没有异常系统,panic类似python的raise;recover就相当于与try/except机制
注意: recover()让程序恢复,必须在延迟函数中执行。换言之,recover()仅在延迟函数中有效
在正常的程序运行过程中,调用recover()会返回nil。否则会捕获到panic的输入值让程序正常运行
1, 程序崩溃后继续执行
下面这段代码实现了ProtectRun函数,该函数传入一个匿名函数或者闭包后的执行函数,当传入函数以任何形式发生panic崩溃后,可以将奔溃发生的错误打印出来,同时允许后面的代码继续运行,不会造成整个进程的崩溃
package main
import (
"fmt"
"runtime"
)
// 崩溃时需要传递的上下文信息
type panicContext struct {
function string // 所在函数
}
func ProtectRun(entry func()) {
// 延迟处理的函数
defer func() {
// 发生宕机时,获取panic传递上下文并打印
err := recover() // recover()获取到panic传入的参数
switch err.(type) {
case runtime.Error: // 运行时错误,比如空指针访问,除数为0等情况
fmt.Println("runtime error:", err)
default:
fmt.Println("error", err)
}
}()
entry()
}
func main() {
fmt.Println("运行前")
ProtectRun(func() {
fmt.Println("手动宕机前")
// 使用panic传递上下文
panic(&panicContext{"手动触发panic"})
fmt.Println("手动宕机后")
})
ProtectRun(func() {
fmt.Println("赋值宕机前")
var a *int
*a = 1
fmt.Println("赋值宕机后")
})
fmt.Println("运行后")
}
运行前
手动宕机前
error &{手动触发panic}
赋值宕机前
runtime error: runtime error: invalid memory address or nil pointer dereference
运行后
2, panic和recover的关系
panic和defer的组合有如下特性:
- 有panic没recover,程序宕机
- 有panic也有recover捕获,程序不会宕机。执行完对应的defer后,从宕机点退出当前函数继续执行
提示: 不建议普通函数经常使用这种特性
在panic触发的defer函数内,可以继续调用panic,经一部将错误外抛直到程序崩溃
如果想在捕获错误时设置当前函数的返回值,可以对返回值使用命名返回值的方式直接设置
9,strings(字符串)和strconv(字符串转的)的使用
具体的还要去官方文档中看,一下子写不完。
补充一个一个小Tip:
go里面和Python不一样,中文字符go中取长度会按照字节长度来算,因此使用len()方法的时候就会得出错误的结果,所以我们需要对其进一步转化。
t := []rune(str),在使用len方法就会得到正确的结果,相当于告诉go,中文的字符就按照一个字符来统计。
package main
import "fmt"
func testSlice() {
var l = "我在tianchi"
fmt.Println(l)
fmt.Println(len(l))
fmt.Println(len([]rune(l)))
}
func main() {
testSlice()
}
① strings
接下来的讲解会对着Python,一点一点来进行对比
- 判断字符串s是否是以prefix开头或者结尾
-
Python的做法:
# -*- coding=utf-8 -*- # @Time : 2019/12/16 11:15 下午 # @Site : # @File : strings.py # @Software: PyCharm # @Author 周力 s = "prefix" ss = "prefix_with" sss = "with_prefix" ss.startswith(s) # 判断ss是否以s开头 sss.endswith(s) # 判断sss是否以s结尾 -
Go的做法:
package main import ( "fmt" "strings" ) func urlProcess(url string) string { result := strings.HasPrefix(url, "http://") // 判断字符串是否以"http://"开头 if !result { url = fmt.Sprintf("http://%s", url) } return url } func pathProcess(path string) string { result := strings.HasSuffix(path, "/") // 判断字符串是否已"/"结尾 if !result { path = fmt.Sprintf("%s/", path) } return path } func main() { var ( url string path string ) fmt.Scanf("%s%s", &url, &path) // 从终端读取值,记住要加&,默认以空格做分隔 url = urlProcess(url) path = pathProcess(path) fmt.Println(url) fmt.Println(path) }
-
判断字符在字符串中出现的位置,如果没有出现那就返回-1
-
Python的做法:
s = "q" ss = "prefix_with" result = ss.index(s) if s in ss else -1 print(result)优雅,优美,壮哉我Python!!!
-
Go的做法:
result := strings.Index("hello world", a)
-
-
字符串的替换
-
Python的做法:
ss = "prefix_with" s1 = ss.replace('p', 's') print(s1) -
Go 的做法:
package main import ( "fmt" "strings" ) func main() { result := strings.Replace("hello wohs", "he", "hs", -1) fmt.Println(result) // hsllo wohs }
-
-
统计字符创重复的格式
-
Python的做法:
from collections import Counter ss = "prefix_with" ss_list = [i for i in ss] print(Counter(ss_list)) -
Go 的做法:
package main import ( "fmt" "strings" ) func main() { result := strings.Count("hello wohs", "l") fmt.Println(result) // 2 }
-
-
字符串转为大小写
-
Python的做法:
ss = "prefix_with" ss_up = ss.upper() ss_lower = ss_up.lower() print(ss_up, ss_lower) -
Go的做法:
package main import ( "fmt" "strings" ) func main() { result := strings.ToUpper("hello world") result_lower := strings.ToLower("HELLO WORLD") fmt.Println(result) // HELLO WORLD fmt.Println(result_lower) // hello world }
-
② strconv
对于Python而言,直接使用str(),int()就可以做到相互转化
但是go还是不行的
package main
import (
"fmt"
"strconv"
)
func main() {
str := strconv.Itoa(100)
fmt.Println(str)
str1, _ := strconv.Atoi("1001")
fmt.Println(str1)
}
10, Go中的时间和日期类型
Go 中的时间处理使用的是time包
go中用time.Time类型,用来表示时间
获取当前时间,now := time.Now()
当然获取年月日时分秒,就类似time.Now().Day(),time.Now().Minute()等
格式化,fmt.Printf("%02d/%02d", now.Year(),now.Month())
time.Duration用来表示纳秒
const (
Nanosecond Duration = 1
Microsecond = 1000 * Nanosecond
Millisecond = 1000 * Microsecond
Second = 1000 * Millisecond
Minute = 60 * Second
Hour = 60 * Minute
)
now := time.Now()
fmt.Println(now.Format("02/1/2006 15:04")) // 坑爹的go为了让人记住他的诞生时间,format必须是这串数字
fmt.Println(now.Format("2006/1/02 15:04"))
fmt.Println(now.Format("2006/1/02"))
记住go的诞生时间2006/1/02 15:04:05(改成三点也行)
举个例子:
-
获取当前时间格式化成2019/12/22 08:05:00
-
获取程序的执行时间,精确到纳秒
package main import ( "fmt" "time" ) func main() { now := time.Now() fmt.Println(now.Format("2006/01/02 15:02:05")) }
package main
import (
"fmt"
"time"
)
func test() {
time.Sleep(time.Millisecond * 100)
}
func main() {
now := time.Now()
fmt.Println(now.Format("2006/01/02 15:02:05"))
start := time.Now().UnixNano() // 1970 年到现在的纳秒数
test()
end := time.Now().UnixNano()
fmt.Printf("cost: %d us
", (end-start)/1000)
}
11, 指针类型
① 普通类型,变量存的就是值,也就是值类型
② 获取变量的地址,用&,比如 var a int, 那么获取a 的地址就是&a
③ 指针类型,变量存的是一个地址,这个地址存的才是值
④ 获取指针类型所指向的值,使用*,比如:var *p int,使用*p获取p指向的值
Go 的指针为什么比c简单呢?
Go 指针不能运算
go的参数传递方式是只有值传递和Python不一样的是Python的既不是值传递也不是引用传递,而是传递对象的引用。
Go 之所以对于引用类型的传递可以修改原内容数据,是因为在底层默认使用该引用类型的指针进行传递,但是也是使用指针的副本,依旧是值传递。
具体使用可以看之前关于变量值交换的第一个例子
package main
import (
"fmt"
)
func main() {
var a int = 5
var p *int = &a
fmt.Println(*p)
var b int = 999
p = &b
*p = 50
fmt.Println(b) // 50
}
12、数组和切片和map和List
① 数组
一,数组是同一种数据类型的固定长度的序列
二,数组定义:var a [len] int,比如:var a[5] int
三,长度是数组类型的一部分,因此var a[5] int 和 var a[10] int 并不是同一种类型
四,数组可以通过下表的形式进行访问,下标是从0开始的,最后一个元素下标是len - 1
for i := 0; i< len(a); i++ {
}
五,访问越界,如果下标在数组不在合法范围,会触发panic
for index, val := range a {
fmt.Println(index, val) // index是下标,val是值
}
数组的初始化:
一维数组
var age0 [5] int = [5]int{1, 2, 3} // 不足部分go会自动补全0
var age1 = [5]int{1, 2, 3, 4, 5} // 这种情况不会自动补全默认值
var age2 [5] int = [...]int{1, 2, 3, 4, 5} // 让go自己数个数
var str = [5]string{3: "hello world", 4: "Jack"} // 表示第一个元素,第四个元素
多维数组:
var age [5][3]int // 5行3列
var f [2][3]int = [...][3]int{{123, 123, 234}, {5, 6, 7}}
总结;
数组是一段固定长度的连续的内存区域。在Go里面数组从声明的时候就确定,使用时可以修改数组成员,但是数组大小不可变化
数组的写法如下:
var 数组变量名 [元素数量]T
- 元素数量:他可以是一个表达式,但是最终编译运算完的结果必须是整形数值,也就是说元素数量的大小不能含有到运行时才能确定的大小范围
- T可以是任意的基本类型,包括T为数组本身,但如果类型为数组本身的时候,可以实现多维数组
示例如下:
package main
import "fmt"
func main() {
var test [3]string
test[0] = "name"
test[1] = "zhou"
test[2] = "li"
fmt.Println(test)
}
数组的遍历:
package main
import "fmt"
func main() {
var test = [3]int{1, 3, 5}
fmt.Println(test)
for index, value := range test {
fmt.Printf("索引为:%d;值为:%d
", index, value)
}
}
[1 3 5]
索引为:0;值为:1
索引为:1;值为:3
索引为:2;值为:5
和Python不同的是,go中遍历会默认第一个元素就是索引,如果不想获取索引,可以使用_来不接收。
另外go语言中一般不会直接使用数组
② 切片
切片的内部结构包含地址、大小、容量,切片一般用于快速操作数据集合
一,切片是数组的一个引用,因此切片是引用类型(意味着:不单独存在,必须指向数组)
二,切片的长度可以改变,因此,切片是一个可变数组
三, 切片的遍历方式和数组一致,可以使用len()求长度
四, cap可以求出slice最大的容量, 0<= len(slice) <= cap(array),其中array是slice引用的数组
五, 切片的定义方式: var 变量名 []类型, 比如 var str []string var arr []int (和数组不一样的地方在于没有长度)
-
从数组中切片
package main import "fmt" func testSlice() { var slice []int var arr = [5]int{1, 2, 3, 4, 5} slice = arr[2:4] fmt.Println(slice) fmt.Println(cap(slice)) // 获取切片的容量 fmt.Println(len(slice)) // 获取切片的长度 // 查看容量和长度的区别 slice = slice[0:1] fmt.Println(slice) fmt.Println(cap(slice)) // 获取切片的容量 fmt.Println(len(slice)) // 获取切片的长度 } func main() { testSlice() }
[3 4]
3
2
[3]
3
1
从数组中切片的形式和Python的方法是基本一致的,这里就不多说了
关于切片的清空和生成相同的切片
package main
import "fmt"
func testSlice() {
var slice []int
var arr = [5]int{1, 2, 3, 4, 5}
slice = arr[:]
fmt.Println(slice[:]) // go 中生成相同的切片
fmt.Println(slice[0:0]) // go中重置切片,清空拥有的元素
}
func main() {
testSlice()
}
[1 2 3 4 5]
[]
需要注意关于切片为空的判定,下面看一个实例
package main
import "fmt"
func testSlice() {
var strlist []string
fmt.Println(strlist == nil)
var intlist = []int{}
fmt.Println(intlist == nil)
}
func main() {
testSlice()
}
true
false
那为什么会是false呢?
因为在声明intlist的时候为一个整形的切片,原本会在{}中填充初始化元素,但是这里并没有填充,因此切片是空的,但是此时intlist已经被分配到内存中去,就只是没有元素而已,因此为false
切片的变化会给数组带来变化:
package main
import "fmt"
func updataSlice(a []int) {
a[0] = 999
}
func main() {
arr := [...]int{0, 1, 2, 3, 4, 5}
s1 := arr[3:6]
s2 := arr[:]
fmt.Println(s1)
fmt.Println(s2)
updataSlice(s1)
fmt.Println(s1)
fmt.Println(arr)
}
[3 4 5]
[0 1 2 3 4 5]
[999 4 5]
[0 1 2 999 4 5]
也就是说切片中元素的改变,会直接影响到数组;
Slice本省没有数据,是对底层array的一个view
slice可以向后扩展,不可以向前扩展
s[i]不可以超越len(s),向后扩展不可以超越底层数组cap(s)
举例说明:
package main
import "fmt"
func main() {
arr := [...]int{0, 1, 2, 3, 4, 5}
s1 := arr[1:3]
s2 := s1[1:4]
fmt.Println(s1)
fmt.Println(s2)
}
[1 2]
[2 3 4]
注意此时的s2切片索引已经超过了s1的索引范围
切片还可以有另一种构造方式:
使用make()函数构造切片;
如果需要动态的床架一个切片,可以使用make()内建函数,格式如下:
make([]T, size, cap )
-
T : 切片的元素类型
-
size:为这个类型分配了多少元素
-
cap:预分配的元素数量,这个值设定之后不会影响size,只能提前分配空间,降低多次分配空间所造成的性能问题。
-
实例如下:
package main import "fmt" func main() { // a和b均为预分配两个元素的切片,只是b元素的内部空间已经分配了10个,但是实际使用2个元素 // 预分配空间并不会影响当前元素的个数。因此a,b取len均为2 a :=make([]int, 2) b :=make([]int, 2, 10) fmt.Println(a, b) fmt.Println(len(a), len(b)) fmt.Println(cap(a), cap(b)) }
[0 0] [0 0]
2 2
2 10
切片不一定必须经过make()函数才能使用。生成切片,声明之后使用append()函数均可以正常使用切片
一, 使用append()函数为切片添加元素
看一个例子:
package main
import "fmt"
func main() {
arr := [...]int{0,1,2,3,4,5,6,7,8}
s1 := arr[2:6]
s2 := s1[3:5]
s3 := append(s2, 10)
s4 := append(s3, 11)
s5 := append(s4, 12)
fmt.Println(s1)
fmt.Println(s2)
fmt.Println(arr)
fmt.Println(s3)
fmt.Println(s4)
fmt.Println(s5)
}
[0 1 2 3 4 5 6 10 11]
[2 3 4 5]
[5 6]
[5 6 10]
[5 6 10 11]
[5 6 10 11 12]
[5 6 10 11 12 13]
可以看到的是数组长度是保持不变的
但是当切片append元素在数值中依旧存在索引的话,就会使用append的值取替换掉原位置索引的值。
那当已经超出数组的时候,比如13去哪了?其实go语言在内部帮我们生成一个新的array(扩容),也就是s4和s5在新的数组中了,所以我们得出结论:添加元素时如果超越cap,系统会重新分配更大的底层数组, 由于值传递的关系,必须接收append的返回值
我们也可以看一下,关于扩容期间,go是怎么去分配容量cap的
package main
import "fmt"
func main() {
var a []int
for i := 1; i <= 10; i++ {
fmt.Printf("数组为:%d;容量为:%d,长度为%d, 地址为%p
", a, cap(a), len(a), a)
a = append(a, i)
}
}
数组为:[];容量为:0,长度为0, 地址为0x0
数组为:[1];容量为:1,长度为1, 地址为0xc000016060
数组为:[1 2];容量为:2,长度为2, 地址为0xc000016080
数组为:[1 2 3];容量为:4,长度为3, 地址为0xc00001a100
数组为:[1 2 3 4];容量为:4,长度为4, 地址为0xc00001a100
数组为:[1 2 3 4 5];容量为:8,长度为5, 地址为0xc00001e080
数组为:[1 2 3 4 5 6];容量为:8,长度为6, 地址为0xc00001e080
数组为:[1 2 3 4 5 6 7];容量为:8,长度为7, 地址为0xc00001e080
数组为:[1 2 3 4 5 6 7 8];容量为:8,长度为8, 地址为0xc00001e080
数组为:[1 2 3 4 5 6 7 8 9];容量为:16,长度为9, 地址为0xc00009c080
可以看到在声明切片的容量为0,也就是为nil,当容量不够的时候,容量扩展规律按照容量的2倍数扩充,比如1,2,4,8,16……当然地址也是在扩容之后发生变化,原因是这个数组是go语言给我新创建的。
当然切片也是支持一次添加多个元素或添加切片
package main
import "fmt"
func main() {
var a []int
var b = []int{1, 2, 3, 4, 5}
var c = []int{6, 7, 8, 9, 10}
a = append(a, 11, 33, 44) // 一次添加多个元素
b = append(b, c...) // go语言中万能的...啊;这次是添加整个切片
fmt.Println(a)
fmt.Println(b)
}
[11 33 44]
[1 2 3 4 5 6 7 8 9 10]
[6 7 8 9 10]
温故而知新: ...目前在go中的用处有哪些?
- 可变参数:...arg
- 让数组自己数:var a = [...]int{1, 2, 3}
- 切片添加切片
二,复制切片元素到另一个切片
Go中内建的copy()函数, 可以迅速的将一个切片的数据复制到另一个切片空间中,copy()函数的使用格式如下:
copy(destSlice, srcSlice []T) int
-
srcSlice 数据来源切片
-
destSlice 复制的目标。目标切片必须分配过空间并且足够承载复制的元素的个数。来源也必须和目标的类型一致。copy返回值表示实际发生复制的元素个数。
实例:
package main import "fmt" func main() { const elementCount = 1000 srcData := make([]int, elementCount) for i := 0; i < elementCount; i++ { srcData[i] = i } redData := srcData copyData := make([]int, elementCount) copy(copyData, srcData) srcData[0] = 999 fmt.Printf("经过拷贝之后的第一个值%d ", redData[0]) fmt.Println(copyData[0], copyData[elementCount-1]) fmt.Printf("scr:%d ", srcData[4:6]) fmt.Printf("copydata前几个值::%d ", copyData[:6]) copy(copyData, srcData[4:6]) fmt.Printf("scr:%d ", srcData[4:6]) fmt.Printf("copydata前几个值::%d ", copyData[:6]) for i := 0; i < 5; i++ { fmt.Printf("%d ", copyData[i]) } }
经过拷贝之后的第一个值999
0 999
scr:[4 5]
copydata前几个值::[0 1 2 3 4 5]
scr:[4 5]
copydata前几个值::[4 5 2 3 4 5]
4
5
2
3
4
得出结论如下: copy是索引对应索引位置进行替换
三, 切片中删除元素
遗憾的是:Go并没有对删除切片元素提供专用的语法或者是接口,需要利用切片的特性来完成
package main
import "fmt"
var delSlice = []string{"a", "b", "c", "v", "d"}
func main() {
delSlice = append(delSlice[:3], delSlice[4:]...)
fmt.Println(delSlice)
}
Go语言中切片删除元素的本质:以被删除元素为分界点,将前后两个部分内存重新连接起来。
③ 映射(map)——建立事务关联的容器
和Python的字典类似,Go中的map也是键值对类型;
go语言中关于map的定义是这样的
map[keyType]ValueType
- keyType 是键的类型
- ValueType 是键对应值得类型
package main
import "fmt"
func main() {
scence := make(map[string]int)
scence["a"] = 1
scence["b"] = 2
fmt.Println(scence["c"]) // 查找一个不存在的键的时候返回返回类型的默认值
v := scence["b"]
fmt.Println(v)
}
当然如果我们有的时候需要知道查询中某个键是否在map中存在的话,可以采用这种写法
package main
import "fmt"
func main() {
scence := make(map[string]int)
scence["a"] = 1
scence["b"] = 2
fmt.Println(scence["c"]) // 查找一个不存在的键的时候返回返回类型的默认值
v, ok := scence["c"]
fmt.Println(v, ok)
d, ok_ := scence["b"]
fmt.Println(d, ok_)
if d, ok_ := scence["c"]; ok_ { // 快速判定
fmt.Println("yes")
} else {
fmt.Println("NO")
}
}
不存在就会返回false
当然在声明map的时候还有另外一种方式:
package main
import "fmt"
func main() {
// scence := make(map[string]int)
scence := map[string]int{
"a": 1,
"b": 2, // 逗号千万可别省略
}
fmt.Println(scence)
}
1,遍历map的键值对使用range
package main
import "fmt"
func main() {
// scence := make(map[string]int)
scence := map[string]int{
"a": 1,
"b": 2,
}
for k ,v := range scence {
fmt.Println(k, v) // 单独只要k就是只是键
}
}
要知道遍历输出元素的顺序和填充的顺序毫无关系,不能期望map在遍历时返回某种期望顺序的结果
如果我们现在想要拿到特定顺序的结果怎么办?
package main
import (
"fmt"
"sort"
)
func main() {
scence := map[string]int{
"a": 1,
"b": 2,
}
var sort_list []string
for k := range scence {
sort_list = append(sort_list, k)
}
sort.Strings(sort_list)
fmt.Println(sort_list)
for i := 0; i < len(sort_list); i++ {
fmt.Printf("键:%s,值: %d", sort_list[i], scence[sort_list[i]])
}
}
2,删除元素
使用delete() 内建函数从map中删除一组键值对,delete()函数格式如下:
delete(map, 键)
- map 要删除的实例
- 键 要删除的map键值对中的键
3, 清空map所有元素:
Go中并没有为map提供任何清空所有元素的函数、方法,想清空?那就重新make一个吧
Go中采用的是并行垃圾回收效率比清空方法效率高得多
4, 能够在并发环境中使用map------sync.Map
Go语言在map并发情况下:只读是线程安全的,同时读写线程不安全
如果想要变得安全的话,那就去加锁,但是加锁后性能便不高,所以go在1.9版本之后提供了
效率较高的并发安全的sync.Map。
sync.Map有以下的特点:
-
无需初始化,直接声明即可
-
sync.Map不能使用Map的方式去取值或者设置等操作,而是使用sync.Map的方法进行调用。Store表示存储,Load表示获取。Delete表示删除
-
使用Range配合一个回调函数进行遍历操作,通过回调函数返回内部遍历出来的值。Range参数中的回调函数的返回值功能是:需要继续迭代遍历时,返回true;终止迭代遍历时返回false
package main import ( "fmt" "sync" ) func main() { var scene sync.Map // 声明scene 类型为sync.Map,不能通过make来创建 // 将键值对保存到sync.Map scene.Store("greece", 97) // 以interface{}类型进行保存 scene.Store("london", 98) scene.Store("egypt", 90) // 从sync.Map中根据键取值 fmt.Println(scene.Load("greece")) // 从sync.Delete中删除键值对 scene.Delete("london") // 遍历所有sync.Map中的键值对 scene.Range(func(key, value interface{}) bool { fmt.Println("iterate", key, value) return true }) /* Range()方法可以遍历sync.Map,遍历需要提供一个匿名函数,参数为key, value类型为interface{} 每一次Range()在遍历一个元素的时候,都会调用这个匿名函数把结果返回 */ }
sync.Map在保证并发安全的前提下会有一点性能损失,在非并发环境下采用map
5, map嵌套map
package main
import "fmt"
func main() {
a := make(map[string]map[string], 100)
fmt.Println(a)
}
如果直接调用的话会报错
package main
import "fmt"
func main() {
var a = make(map[string]map[string]string)
a["key"] = make(map[string]string)
a["key"]["key2"] = "value"
fmt.Println(a)
}
在调用之前需要先对map进行初始化。
总结:
map使用哈希表,必须可以比较相等
除了slice,map,function的内建类型都可以作为key
Struct类型不包含上述字段,也可以作为key(不推荐)
④ List列表------可以快速增删的非连续容器
列表十一章非连续存储的容器,由多个节点组成,节点通过一些变量记录彼此之间的关系,列表的实现方法有单链表,双链表等
在Go语言中,列表将通过container/list包来实现,内部的实现原理是双链表列表可以很方便的也很高效的对任意位置的元素进行插入删除
List 的初始化有两种方法:New和声明。两种方法的初始化效果都是一样的
一, 通过container/list包的New方法初始化list
变量名 := list.New方法初始化list
a := list.New()
二, 通过声明初始化list
var 变量名 list.List
var a list.List
列表与切片和map不同的是,列表并没有具体元素类型的限制。因此,列表的元素可以使任意类型。
三, 插入元素
双链表支持从队列前方或者后方插入元素,分别对应的方法是PushFront和PushBack。
这两个方法都会返回一个*list.Element结构。如果在以后的使用中需要删除插入的元素,则只能通过*list.Element配合Remove()方法进行删除,这种方法可以让删除更具有效率化,这也是双链表的特性之一。
//a := list.New()
var a list.List
a.PushBack("first") // 插入队列的尾部,此时的队列是空的,因此此时只有一个元素
a.PushFront(55) // 将55放入队列中,此时的列表中已经存在first,因此55将在其之前
| 方法 | 功能 |
|---|---|
| InsertAfter(v interface{}, mark *Element) | 在mark点之后插入元素,mark点由其他人插入函数提供 |
| InsertBefore(v interface{}, mark *Element) | 在mark点之前插入元素,mark点由其他人插入函数提供 |
| PushBackList(other *List) | 添加other列表元素到尾部 |
| PushFrontList(other *List) | 添加other列表元素到头部 |
四, 从列表中删除元素
列表的插入函数的返回值会提供一个 *List.Element结构,这个结构记录着列表元素的值及其他节点之间的关系等信息。从列表中删除元素时,需要用到这个结构进行快速删除。
package main
import "container/list"
func main() {
a := list.New()
a.PushBack("1") // 尾部添加
a.PushFront("前1") // 头部添加
element := a.PushBack("first") // 尾部添加后保存元素句柄
a.InsertAfter("high", element) // 在first之后添加high
a.InsertBefore("second", element) // 在first之前添加second
a.Remove(element) // 删除元素句柄对应的元素,也就是first
}
因为操作过程不好直接展示a列表的元素情况,因此,将值得实时状态写出来
| 操作内容 | 列表元素 |
|---|---|
| a.PushBack("1") | "1" |
| a.PushFront("前1") | 前1,"1" |
| element := a.PushBack("first") | 前1,"1","first" |
| a.InsertAfter("high", element) | 前1,"1","first","high" |
| a.InsertBefore("second", element) | 前1,"1",”second“,"first","high" |
| a.Remove(element) | 前1,"1",”second“,"high" |
五,遍历列表------访问列表的每一个元素
遍历双链表需要配合Front()函数获取头元素,遍历时只要元素不为空就可以继续进行。每一次遍历调用Next!
package main
import (
"container/list"
"fmt"
)
func main() {
a := list.New()
a.PushBack("1") // 尾部添加
a.PushFront("前1") // 头部添加
for i := a.Front(); i != nil; i = i.Next() {
fmt.Println(i.Value)
}
/*
其中a.Front()表示初始赋值,也就是获取头部元素,只会在开始的时候执行一次。
使用i.value方法获取放入列表中的原值
*/
}
13, 结构体(struct)
go语言的面向对象仅支持封装,不支持继承和多态。
go中没有类也就是class,只有struct
并且go的struct并没有构造函数的
定义格式如下:
type 类型名 struct {
字段1 字段1的类型
字段2 字段2的类型
…
}
- struct{} 表示结构体类型,type类型名struct{}结构体定义为类型名的类型
- 字段1、字段2……:表示结构体字段名。结构体中的字段名必须唯一。
- 字段1类型、字段2类型……表示结构体字段的类型
- 结构体是值类型,也就是如果需要修改结构体字段,就需要传递指针
比如结构体表示一个包含X和Y整形分量的点结构,代码如下:
type Point struct {
X int
Y int
}
// 相同类型的变量也可以卸载同一行。颜色的红绿蓝3个分量可以使用byte类型表示
type Color struct {
R, G, B byte
}
结构体的内存布局:struct所有字段在内存中是连续的
package main
import "fmt"
type Student struct {
Name string
Age int
score float32
}
func main() {
var stu Student
stu.Age = 18
stu.Name = "zhou"
stu.score = 90
fmt.Println(stu)
fmt.Printf("stu.Name:%p
", &stu.Name)
fmt.Printf("stu.Age:%p
", &stu.Age)
fmt.Printf("stu.score:%p
", &stu.score)
}
stu.Name:0xc00000c060
stu.Age:0xc00000c070
stu.score:0xc00000c078
实现链表结构:
package main
import (
"fmt"
"math/rand"
)
type Student struct {
Name string
Age int
Score float32
next *Student
}
// 遍历链表,首先需要制定头结点
func trans(p *Student) {
for p != nil {
fmt.Println(*p)
p = p.next // 等同于(*p).next
}
}
// 尾部插入节点
func insertTail(p *Student) {
var tail = p
for i := 3; i < 10; i++ {
stu := Student{
Name: fmt.Sprintf("stu%d", i),
Age: rand.Intn(100),
Score: rand.Float32() * 100,
}
tail.next = &stu
tail = &stu
}
}
func main() {
// 定义头结点
var head Student
head.Name = "zl"
head.Age = 28
head.Score = 100
stu2 := Student{
Name: "stu2",
Age: 10,
Score: 15,
next: nil,
}
stu := Student{
Name: "stu",
Age: 10,
Score: 15,
next: &stu2,
}
head.next = &stu
trans(&head)
// 插入节点
insertTail(&head)
}
① 实例化结构体:
结构体的定义只是对内存布局的描述,只有当结构体实例化时,词汇真正的分配内存。因此必须在定义结构体并实例化后才可以使用结构体的字段。
实例化就是根据结构体的定义格式创建一份格式与之完全一致的内存区域,结构体实例和实例的内存完全独立
Go中存在多种方式实例化结构体。
⑴ 最基本的实例化形式:
结构体的本身是一种类型,可以像整形、字符串等类型一样,以var的方式声明结构体即可完成实例化
var ins T
- T为结构体类型
- ins为结构体实例
用结构体表示点结构(Point)的实例化过程:
type Point struct {
X int
Y int
}
var point Point
point.X = 10
point.Y = 10
// point := Point{X: 10, Y: 10}
在例子中,使用.来访问结构体的成员变量,如p.X和p.Y等。结构体成员变量的复制方法和普通变量一致
⑵ 指针类型的结构体
在Go中还可以使用new关键字对类型(包括结构体、整形、浮点数、字符串等)进行实例化。结构体实例化之后会形成指针类型的结构体
使用new格式如下:
point := new(T)
等同于point := &T{}
- T为类型,可以是结构体,整形字符串等
- point:T类型被实例化后保存到point变量中,point的类型为*T,属于指针
type Player struct {
Name string
HealthPoint int
MagicPoint int
}
tank := new(Player)
tank.Name = "Wang"
tank.HealthPoint = 200
// 经过new实例化之后的结构体是在成员赋值上的写法是一致的
在Go中,我们知道*来访问指针,那这里直接用点的方式实现是因为go使用了语法糖的技术,吧tank.Name形式转化为:
(*tank).Name
⑶ 结构体的地址实例化
在Go语言中,对结构体进行&取地址操作的时,视为对该类型进行一次new的实例化操作,取地址的格式如下:
ins := &T{}
- T表示结构体类型
- ins为结构体是,类型是*T是指针
package main
type Command struct {
Name string
age *int
comment string
}
var age = 18
func main() {
cmd := &Command{}
cmd.Name = "zhou"
cmd.age = &age
cmd.comment = "show IT"
}
⑷ 初始化结构体的成员变量
-
使用键值对初始化结构体
键值对的填充是可选的,不需要初始化的字段可以不写入初始化列表中。
结构体实例化后字段的默认值是字段类型的默认值,例如:数值为0,字符串为空字符串,布尔为false
,指针为nil等
初始化的格式如下:
ins := 结构体类型名 {
字段1 :字段1的值
字段2 :字段2的值,
}
举个例子: 爷父子是三级名称,那怎么用结构体进行定义呢?(也就是struct链表)
package main type People struct { Name string child *People } func main() { relation := &People{ Name: "爷", child: &People{ Name: "父", child: &People{ Name: "子", child: nil, // 可以忽略 }, }, } var p = relation // 利用单链表实现循环查找下一个 for p != nil { fmt.Println(p) p = p.child } } } -
使用多个值的列表初始化结构体
Go语言可以在键值对初始化的基础上忽略键,也就是说,可以试用多个值得列表初始化结构体字段
格式如下:
ins := {
字段1的值,
字段2的值,
}
但是如果不写键的话初始化,必须要所有字段全部一次性初始化完毕;顺序必须和声明顺序一致;键值对和值列表的初始化形式不可以混用;另外,别忘了逗号
package main type Address struct { Province string City string ZipCode string Phone int } func main() { myAdress := Address{ "江苏", "连云港", "011111", 111111, } } -
初始化匿名结构体
所谓匿名结构体,和匿名函数类似,无需名字,无需通过type关键字定义就可以直接使用
① 匿名结构体定义格式和初始化写法
匿名结构体的护士和写法由结构体定义和键值对初始化两部分组成。结构体定义时没有结构体类型名,只有字段和类型的定义。键值对初始化方式和之前一致
ins := struct { // 匿名结构体字段定义 字段1 字段类型, 字段2 字段类型, }{ // 字段值的初始化 初始化字段1: 字段1的值 初始化字段2: 字段2的值 }
不需要初始化成员时,格式如下:
ins := struct {
// 匿名结构体字段定义
字段1 字段类型,
字段2 字段类型,
}{ }
② 使用匿名结构体的例子:
package main
import "fmt"
func printMsgType(msg *struct {
id int
data string
}) {
//使用动词%T打印msg的类型
fmt.Printf("%T
", msg)
}
func main() {
// 实例化一个匿名结构体
msg := &struct {
id int
data string
}{
1024,
"hello",
}
printMsgType(msg)
}
③ 工厂函数生成结构体
type treeNode struct {
value int
left, right *treeNode
}
func createNode(value int) *treeNode {
return &treeNode{value:value}
}
如果有C经验的同学就会说这个呢在C是报错的,因为函数返回的是个局部变量。但是在Go里面却是合法的
那么这个go的结构体到底是存在堆上还是在栈上呢?这个其实是不需要我们了解的,因为Go中有完善的垃圾回收机制
④带有父子关系的结构体的构造和初始化——————模拟父级构造调用
黑猫是一种猫,猫是黑猫的一种泛称,同时描述这两种概念时就是派生,黑猫派生自猫的种类。使用结构体
描述猫和黑猫的关系时,将猫(cat)的结构体嵌入到黑猫(BalckCat)中,表示黑猫有猫的属性。然后再使用两个不同的构造函数分别构造出黑猫和猫两个结构体实例:**
package main
type Cat struct {
Color string
Name string
}
type BlackCat struct {
Cat // 嵌入Cat ,类似于派生;也就表示BlackCat拥有Cat的所有成员,实例化后可以自由访问Cat的所有成员
}
// 定义Cat的构造过程,使用名字作为参数填充Cat结构体
func NewCat(name string) *Cat {
return &Cat{
Name: name,
}
}
// 使用color作为参数,构造返回BlackCat指针
func NewBlackCat(color string) *BlackCat {
cat := &BlackCat{} // 实例化BlackCat结构,此时Cat也被实例化(重点)
cat.Color = color // 填充BalckCat中嵌套的Cat颜色属性。BlackCat没有任何成员,所有的成员都来自Cat
return cat
}
总之,Go语言中没有提供构造函数相关的特殊机制,用户根据自己的需求,将参数使用函数传递到结构体构造参数中即可完成构造函数的任务。
⑸ 方法
Go 语言中的方法(Method)是一种作用于特定类型变量的函数,这种特定类型变量叫做接收器(Recerier)
如果将特定类型理解为结构体或“类”时,接收器的概念就类似于其他语言中的this或self。
在Go语言中,接收器的类型可以是任何类型,不仅仅是结构体,任何类型都可以拥有方法
在面向对象的语言中,类拥有的方法一般被理解为类可以做的事情,在Go语言中的方法的概念和其他语言一致,只是Go语言建立的接收器强调方法的作用对象是接收器,也就是类实例,而函数没有作用对象。
nil指针也可以调用方法!
1, 面向过程实现方法
面向过程中没有方法的概念,由使用者使用函数参数和调用关系来形成接近方法的概念
package main
type Bag struct {
items []int
}
// 将一个物品放入背包的过程
func Insert(b *Bag, itemid int) {
b.items = append(b.items, itemid)
}
func main() {
bag := new(Bag)
Insert(bag, 200)
}
面向过程的代码描述对象方法概念随着越来越多的代码,会变得难以理解和麻烦
2, Go语言的结构体方法
将背包及放入背包的物品使用Go语言的结构体和方法方式编写,为*Bag创建一个方法,代码如下
package main
type Bag struct {
items []int
}
// 将一个物品放入背包的过程
func (b *Bag) Insert(itemid int) {
b.items = append(b.items, itemid)
}
func main() {
bag := new(Bag)
bag.Insert(200)
}
第五行中,Insert(itemid int)的写法和函数一致。(b *Bag)表示接收器,就是Insert作用的对象实例
每一个方法只能有一个接收器

接收器——————方法作用的目标
接收器的格式定义如下:
func (接收器变量 接收器类型) 方法名 (参数列表) (返回参数) {
函数体
}
也就是说Go的新增方法很简单,仅仅是需要额外的添加接收者
- 接收器变量: 接收器中的参数变量名在命名时候,建议使用接收器类型名的第一个小写字母,而不是像Python中的self之类的命名。例如:Socket类型的接收器变量应该是s,Connector类型的接收变量为c。
- 接收器的类型:接收器类型和参数类似,可以是指针类型或者是非指针类型。
- 方法名、参数列表、返回参数:格式与函数定义一致。
接收器可以根据接收器的类型分为指针接收器、非指针接收器。两种接收器在使用的时候会产生不同的效果。根据效果的不同,两种接收器会被用于不同性能和功能需求的代码中。
指针类型的接收器:
指针类型的接收器由一个结构体的指针组成,更接近于面向对象中的self
同样的,由于指针的特定,调用方法适合修改的是指针成员的变量,在方法调用结束之后,修改都是有效的
在下面的例子中:使用结构体定义一个属性(Property),为属性添加setValue()方法以封装设置属性的过程
通过属性的Value()方法可以重新获得属性的数值。使用属性时,通过setValue()方法的调用,可以达成修改属性值得效果
package main
import "fmt"
// 定义属性结构
type Property struct {
value int
}
// 设置属性值
func (p *Property) SetValue(v int) {
// 修改p的成员变量
p.value = v
}
// 取属性值
func (p *Property) Value() int {
return p.value
}
func main() {
// 实例化属性
p := new(Property)
// 设置值
p.SetValue(0)
// 打印值
fmt.Println(p.Value())
}
非指针类型接收器:
当方法作用于非指针接收器是,Go语言会在代码运行时将接收器的值复制一份,在非指针接收器的方法中可以获取接收器的成员值,但修改后是无效的。
package main
import "fmt"
// 定义点结构
type Point struct {
X int
Y int
}
// 非指针接收器的加方法
func (p Point) Add(other Point) Point {
// 成员值和参数相加之后返回新的结构
return Point{p.X + other.X, p.Y + other.Y}
}
func main() {
// 初始化点
p1 := Point{1, 1}
p2 := Point{2, 2}
result := p1.Add(p2)
fmt.Println(result)
}
Point使用结构体描述时,为点添加Add()方法,这个方法不能修改Point成员的X,Y变量,而是在计算后返回新的Point对象。Point属于小内存对象,在函数返回值的复制过程中可以极大的提高代码的运行效率。
由于例子中使用了非指针接收器,Add()方法变得类似于只读的方法,Add()方法内部不会对成员进行任何修改
总结:
对于小对象的值复制速度较快,比较适合使用非指针接收器;
但是大对象因为复制性能较低,适合使用指针接收器,在接收器和参数间传递不进行复制,只是传递指针
大的示例:
在游戏中,一般使用二维矢量保存玩家的位置。使用矢量运算可以计算出玩家的移动位置。
-
实现二维矢量结构:
矢量是数学中的概念,二维矢量拥有两个方向的信息,同时可以进行加、减、乘、除(缩放功能)、距离、单位化等计算,在计算机中,使用拥有X和Y两个分量的Vec2结构体实现数学中二维向量的概念
package main import "math" // 定义点结构 type Vec2 struct { X, Y float32 } // 使用矢量加上另一个矢量,生成新的矢量 func (v Vec2) Add(other Vec2) Vec2 { return Vec2{ X: v.X + other.X, Y: v.Y + other.Y, } } // 使用矢量减去另一个矢量,生成新的矢量 func (v Vec2) Sub(other Vec2) Vec2 { return Vec2{ X: v.X - other.X, Y: v.Y - other.Y, } } // 使用矢量乘以另外一个矢量,生成新的矢量 func (v Vec2) Scale(other float32) Vec2 { return Vec2{v.X * other, v.Y * other} } // 计算两个矢量的距离 func (v Vec2) DistanceTo(other Vec2) float32 { dx := v.X - other.X dy := v.Y - other.Y return float32(math.Sqrt(float64(dx*dx + dy*dy))) // math.Sqrt(x float64) } // 返回当前矢量的标准化矢量 func (v Vec2) Normalize() Vec2 { if msg := v.X*v.X + v.Y*v.Y; msg > 0 { oneOverMsg := 1 / float32(math.Sqrt(float64(msg))) return Vec2{v.X * oneOverMsg, v.Y * oneOverMsg} } return Vec2{0, 0} } -
实现玩家对象:
玩家对象负责存储玩家的当前位置,目标位置和速度。使用MoveTo()方法为玩家设定移动的目标,使用Update()方法更新玩家位置。在Update()方法中,通过一系列的矢量计算获得玩家移动后的新位置,步骤如下:
1,使用矢量剪发,将目标位置(targetPos)减去当前位置(currPos)即可计算出位于两个位置之间的新矢量
2, 使用Normalize()方法将方向矢量变成模为1的单位化矢量。这里需要将矢量单位优化后才能进行后续计算
3, 获得方向后,将单位化方向矢量根据速度进行等比缩放,速度越快,速度数值越大,乘上方向后生成的矢量就越长(模很大)
4, 将缩放后的方向添加到当前位置后形成新的位置
package main //import "go_dev/day4/val_or_address/main/" type Player struct { currPos Vec2 // 当前位置 targetPos Vec2 // 目标位置 speed float32 // 移动速度 } // 设置玩家移动的目标位置 func (p *Player) MoveTo(other Vec2) { p.targetPos = other } // 获取当前位置 func (p *Player) Pos() Vec2 { return p.currPos } // 判断是否到达目的地 func (p *Player) IsArrived() bool { // 通过计算当前玩家位置与目标位置的距离不超过移动的步长,判断已经达到目标点 return p.currPos.DistanceTo(p.targetPos) < p.speed } // 更新玩家位置 func (p *Player) Update() { if !p.IsArrived() { // 计算出当前位置指向目标朝向 dir := p.targetPos.Sub(p.currPos).Normalize() // 添加速度矢量生成新的位置 newPos := p.currPos.Add(dir.Scale(p.speed)) // 移动完成之后,更新当前位置 p.currPos = newPos } } // 创建新玩家 func NewPlayer(speed float32) *Player { return &Player{ speed: speed, } } -
处理移动逻辑
将Player实例化之后,设定玩家移动的最终目标点。之后开始进行移动的过程,这是一个不断更新位置的循环过程
每一次检测玩家是否靠近目标点附近,如果还没有到达,则不断的更新位置,让玩家插着目标点不停的修改当前位置
package main import "fmt" func main() { // 实例化玩家对象,并设定速度为0.5 p := NewPlayer(0.5) // 让玩家移动到3 1点 p.MoveTo(Vec2{3, 1}) for !p.IsArrived() { // 更新玩家位置 p.Update() fmt.Println(p.Pos()) } }
⑹ 为类型添加方法
在Go中可以为任何类型添加方法,给一种类型添加方法就像给结构体添加方法一样简单,毕竟在Go中结构体也是一种类型
-
为基本类型添加方法
在Go语言中,使用type关键字可以定义新的自定义类型。之后就可以为自定义类型添加各种方法。我们习惯于使用面向过程的方式判断一个值是否为0;
if v == 0 { // 处理逻辑 }如果价格v当做整形对象,那么判断v值就可以增加一个IsZero()的方法,通过这个方法去判断v值是否为0
if v.IsZero() { // 处理逻辑 }
示例如下:
package main
import "fmt"
// 将int定义为MyInt类型(也就是别名)
type MyInt int
// 为MyInt 增加IsZero方法
func (m MyInt) IsZero() bool {
return m == 0
}
// 为MyInt添加add()方法
func (m MyInt) Add(other int) int {
return int(m) + other
}
func main() {
b := MyInt(3)
fmt.Println(b.Add(3))
fmt.Println(b.IsZero())
var c MyInt
fmt.Println(c.IsZero())
c = 1
fmt.Println(c.Add(1))
}
在上述例子中,Add和IsZero方法均使用非指针接收器,b和c的值会被复制进入IsZero进行判断
6
false
true
2
其实在Go语言的源码中也大量的使用了类型方法。Go语言使用http包进行HTTP的请求。
使用Http包的NewRequest方法可以创建一个HTTP请求,填充请求中的http头(req.Hearder)
再调用http.Client的Do包方法,将传入的HTTP请求发送出去
package simu_http
import (
"fmt"
"io/ioutil"
"net/http"
"os"
"strings"
)
func ReqMain() {
client := &http.Client{}
// 创建一个HTTP请求
// 先构造一个请求帝乡,不会真正的链接网络
if req, err := http.NewRequest("POST", "http://www.baidu.com",
strings.NewReader("key=value")); err != nil {
fmt.Println(err)
os.Exit(1)
return
} else {
req.Header.Add("User-Agent", "myClient") // 自定义的方法
// 开始请求
resp, err := client.Do(req)
// 处理请求错误
if err != nil {
fmt.Println(err)
os.Exit(1)
return
}
// 读取服务器返回的内容
data, err := ioutil.ReadAll(resp.Body)
fmt.Println(string(data))
defer resp.Body.Close()
}
}
⑺ 使用事件系统实现事件的响应和处理
Go语言可以将类型的方法和普通函数视为一个概念,从而简化方法和函数混合作为回调类型的复杂性。这个特性和C#中的代理比较类似,调用者无需关心谁来支持调用,系统会自动处理是否调用普通函数或类型的方法。
-
方法和函数的统一调用
举一个结构体的方法的参数和一个普通函数的参数完全一致,也就是方法与函数的签名一致。然后使用与他们签名一致的函数变量分别赋值方法与函数,接着调用他们,观察实际效果。
package main import "fmt" type class struct { } func (c class) Do(v int) { fmt.Println("method do:", v) } // 普通函数的Do()方法 func funcDo(v int) { fmt.Println("function do:", v) } func main() { //声明一个函数回调 var delegate func(int) // 声明一个delegate的变量,类型为func(int),与funcDo和class的Do方法入参类型一致 // 创建一个结构体实例 c := new(class) // 将回调设为c的Do方法 delegate = c.Do delegate(100) // 将回调设置为普通函数 delegate = funcDo delegate(100) }这段代码能运行的基础在于:无论是普通函数还是结构体方法,只要他们签名是一致的,函数 变量就可以保存为普通函数或者是结构体方法。
了解Go的这一个特性之后,我们就可以把它们应用在事件中
-
事件系统基本原理:
事件系统可以将事件派发者与事件处理者解耦。例如:网络底层可以生成各种事件,在网络连接上之后,网络底层只需要将事件派发出去,而不需要关心到底哪些代码来响应连接上的逻辑。
一个事件系统拥有如下特性:
能够实现事件的一方,可以根据事件的ID或名字注册对应的事件。
事件的发起者,会根据注册信息通知这些注册者。
一个事件可以有多个实现方响应
-
事件注册
事件系统需要为外部提供一个注册入口,这个注册入口传入注册的事件名称和对应事件名称的响应函数,事件注册的过程就是将事件名称和响应函数关联并保存起来。
package main // 实例化一个通过字符串映射函数切片的map var eventByName = make(map[string][]func(interface{})) // 注册事件,提供事件名和回调函数 func RegisterEvent(name string, callback func(interface{})) { // 通过名字查找事件列表 list := eventByName[name] // 在列表切片中添加函数 list = append(list, callback) // 保存修改的事件列表切片 eventByName[name] = list } -
事件调用
事件调用方和注册方是事件处理中完全不同的两个角色。事件调用方是事发现场,负责将事件和事件发生的参数通过事件系统派发出去,而不关系到底有谁处理;
事件注册方通过事件系统注册应该响应哪些事件以及如何使用回调函数处理这些事件,事件的详细实现如下:
//调用事件 func CallEvent(name string, param interface{}) { // 通过名字找到事件列表 list := eventByName[name] for _, callback := range list { //传入参数参与回调 callback(param) } } -
使用事件系统
使用main函数去嗲用事件系统的CallEvent生成OnSkill事件,这个事件由两个处理函数,一个角色的OnEvent()方法,还有一个是函数GlobalEvent,详细代码实现如下:
// 声明结构体 type Actor struct { } // 为角色添加一个事件处理函数 func (a *Actor) OnEvent(param interface{}) { fmt.Println("actor event", param) } // 全局事件 func GlobalEvent(param interface{}) { fmt.Println("global event", param) } func main() { // 实例化一个角色 a := new(Actor) // 注册名为OnSkill的回调 RegisterEvent("OnSkill", a.OnEvent) // 再次在OnSkill上注册全局事件 RegisterEvent("OnSkill", GlobalEvent) // 调用事件,所有注册的同名函数都会被调用 CallEvent("OnSkill", 100) }
完整如下:
package main
import "fmt"
// 实例化一个通过字符串映射函数切片的map
var eventByName = make(map[string][]func(interface{}))
// 注册事件,提供事件名和回调函数
func RegisterEvent(name string, callback func(interface{})) {
// 通过名字查找事件列表
list := eventByName[name]
// 在列表切片中添加函数
list = append(list, callback)
// 保存修改的事件列表切片
eventByName[name] = list
}
//调用事件
func CallEvent(name string, param interface{}) {
// 通过名字找到事件列表
list := eventByName[name]
for _, callback := range list {
//传入参数参与回调
callback(param)
}
}
// 声明结构体
type Actor struct {
}
// 为角色添加一个事件处理函数
func (a *Actor) OnEvent(param interface{}) {
fmt.Println("actor event", param)
}
// 全局事件
func GlobalEvent(param interface{}) {
fmt.Println("global event", param)
}
func main() {
// 实例化一个角色
a := new(Actor)
// 注册名为OnSkill的回调
RegisterEvent("OnSkill", a.OnEvent)
// 再次在OnSkill上注册全局事件
RegisterEvent("OnSkill", GlobalEvent)
// 调用事件,所有注册的同名函数都会被调用
CallEvent("OnSkill", 100)
}
actor event 100
global event 100
从结果来看:角色和全局的事件会按照注册的顺序顺序地触发。
一般来说,事件系统并不保证同一个事件实现方读个函数列表中的调用顺序,事件系统认为所有实现函数都是平等的,也就是说,无论例子中的a.OnEvent先注册韩式GlobalEvent函数先注册,最终谁先被调用,都是无所谓的。
当然一个完善的事件系统还会提供移除单个和所有事件的方法
② 类型内嵌和结构体内嵌
结构体允许成员字段在声明时候没有字段名而只有类型,这种形式的字段被称为类型内嵌或者匿名字段
具体写法如下:
package main
import "fmt"
type Data struct {
int
float32
bool
}
func main() {
ins := Data{
int: 10,
float32: 3.14,
bool: true,
}
fmt.Println(ins)
}
其实类型内嵌依然拥有自己的字段名,只是字段名就是其本身的类型而已,因此结构体中的字段名必须唯一,因此一个结构体中同种类型的匿名字段只能有一个
结构体实例化之后,如果匿名字段类型为结构体,那么可以直接访问匿名结构体里面的所有成员,这种方式就是结构体内嵌
⑴ 声明结构体内嵌
结构体类型内嵌比普通类型内嵌的概念复杂一些,下面通过一个实例来理解
所有的颜色都是由红绿蓝组合而成的,在计算机中透明度角Alpha,范围0~1之间。0代表完全透明,1代表不透明。使用传统结构体字段的方法定义基础颜色和带有透明度颜色的过程代码如下:
package main
import "fmt"
type BasicColor struct {
// 红,绿 ,蓝三种颜色分量
R, G, B float32
}
// 完整颜色定义
type Color struct {
// 将基本颜色作为成员
Basic BasicColor
Alpha float32
}
func main() {
var c Color
// 设置基本颜色分量
c.Basic.R = 1
c.Basic.G = 1
c.Basic.B = 0
// 设置透明度
c.Alpha = 1
fmt.Printf("%+v", c)
}
这样写起来是完全没有问题的,但是c需要通过Basic才能够设置RGB分量,虽然合理但是写法很复杂,使用GO语言结构体内嵌写法重新调整如下:
package main
import "fmt"
type BasicColor struct {
// 红,绿 ,蓝三种颜色分量
R, G, B float32
}
// 完整颜色定义
type Color struct {
// 将基本颜色作为成员
BasicColor
Alpha float32
}
func main() {
var c Color
// 设置基本颜色分量
c.R = 1
c.G = 1
c.B = 0
// 设置透明度
c.Alpha = 1
fmt.Printf("%+v", c)
}
这个就是之前我们所说的派生。(在本章节第一段第四小段第四小节说过)
当然在Go中这种写法就叫结构体内嵌。
特性:
-
内嵌结构体可以直接访问其成员变量
嵌入结构体的成员,可以通过外部结构体实例直接访问。如果结构体有多层嵌入结构体,结构体实例访问任意一级的嵌入结构体成员时都只用给出字段名,而无需向传统结构体字段一样,通过一层层访问,内嵌结构体的字段名就是他的类型名;例如ins.a.b.c的访问可以简化为ins.c。
-
内嵌结构体的字段名是他的类型名
内嵌结构体字段仍然可以使用详细的字段进行一层层访问,内嵌结构体的字段名就是他的类型名,代码如下:
var c Color c.BasicColor.R = 1 c.BasicColor.G = 1 c.BasicColor.B = 1一个结构体只能嵌入一个同类型的成员,无须担心结构体重名和错误赋值的情况,因为编译器就会提前报错
-
使用组合思想描述对象特性
在面向对象思想中,实现对象关系需要使用继承特性:
比如人不能飞翔,鸟可以飞行。人和鸟都可以继承行走类,但鸟还可以继承飞行类
面向对象设计原则也建议最好不要使用多继承,有些面向对象语言从语言层面就禁止多继承,如:Java和C#。鸟类可以同时继承行走类和飞行类,这显然是有问题的,在面向对象思想中要正确的使用对象的多重特性,只能使用一些精巧的设计来补救。(反正我很讨厌)
Go语言的结构体内嵌特性就是一种组合特性,使用组合特性可快速构建对象的不同特性。
实例如下:
package main import "fmt" type Flying struct { } func (f *Flying) Fly() { fmt.Println("I can Fly") } type Walkable struct { } func (w *Walkable) Walk() { fmt.Println("I can Walk") } // 人 type Human struct { Walkable } type Bird struct { Walkable // 鸟能走 Flying // 鸟能飞 } func main() { // 实例化鸟类 b := new(Bird) fmt.Println("Bird: ") b.Fly() b.Walk() // 实例化人类 h := &Human{} fmt.Println("Human: ") h.Walk() }使用Go语言的内嵌结构体实现对象的特性,可以很自由的在对对象实现各种特性,Go语言会在编译时检查是否可以使用这些特性。
-
初始化结构体内嵌
结构体内嵌初始化时候,将结构体内嵌的类型作为字段名像普通结构体一样进行初始化
package main import "fmt" // 车轮 type Wheel struct { Size int } // 引擎 type Engine struct { Power int Type string } // 车 type Car struct { Wheel Engine } func main() { c := Car{ Wheel: Wheel{ Size: 18, }, Engine: Engine{143, "1.45T"}, } fmt.Printf("%+v ", c) } -
初始化内嵌结构体
在上一个例子中,为了考虑代码的便捷性,会直接将结构体定义到嵌入的结构体中,也就是结构体的定义不会被外部引用到。在初始化这个被嵌入的结构体是,就需要再次声明结构才能赋予数据。
package main import "fmt" type Wheel struct { Size int } type Car struct { Wheel // 引擎 Engine struct { Power int // 功率 Type string // 类型 } } func main() { c := Car{ Wheel: Wheel{ Size: 18, }, Engine: struct { Power int Type string }{ Power: 143, Type: "1.45T", }, } fmt.Printf("%+v ", c) // 需要对Car的Engine字段进行初始化,由于Engine字段的类型并没有被单独定义,因此在初始化其字段是需要先填写struct{…}声明其类型 } -
成员名字冲突
嵌入结构体内部可能有相同的成员名,当成员重名时候会发生啥?
当然就不能直接用点的方式了,只能先点出A,再去点a
也就是说不能c.a,而是需要c.A.a
-
实际案例
手机拥有屏幕、电池、指纹等信息,将这些信息填充为Json格式的数据。如果需要选择的分离Json中的数据则比较麻烦。Go语言中的匿名结构体可以方便的完成这个操作
准备Json数据
package main import "encoding/json" type Screen struct { Size float32 // 屏幕尺寸 ResX, ResY int // 屏幕水平和垂直分辨率 } // 定义电池 type Battery struct { Capacity int // 容量 } // 准备Json数据 // 准备手机数据,填充数据,将数据序列化为Json格式的字节数组,代码如下: func genJsonData() []byte { // 完整数据结构 raw := &struct { Screen Battery HasTouchID bool }{ //屏幕参数 Screen: Screen{ Size: 5.5, ResX: 1920, ResY: 1080, }, //电池参数 Battery: Battery{Capacity: 2910}, //是否有指纹识别 HasTouchID: true, } //将数据序列号为Json jsonData, _ := json.Marshal(raw) return jsonData }分离json数据
func main() { // 生成一段Json数据 jsonData := genJsonData() fmt.Println(string(jsonData)) //只需要屏幕和指纹识别信息的结构和实例 screenAndTouch := struct { Screen HasTouchID bool }{} // 反序列化到screenAndTouch中 json.Unmarshal(jsonData, &screenAndTouch) batteryAndTouch := struct { Battery HasTouchID bool }{} // 反序列化到batteryAndTouch json.Unmarshal(jsonData, &batteryAndTouch) fmt.Printf("%+v ", batteryAndTouch) fmt.Printf("%+v ", screenAndTouch) }
14, 包
Go语言的源码服用建立在包(package)基础之上。Go语言入口main()函数所在的包(package)叫main。
main包要想引用别的代码,必须同样以包的方式进行引用。本章内容将详细讲解如何导出包的内容以及如何导入其他包
Go语言的包与文件夹意义对应,所有与包相关的操作,必须依赖工作目录(GOPATH)
go中是每一个目录对应一个包,可以不同名
main包,包含可执行入口,因此是必须的名字main
为结构定义的方法必须放在同一个包内,可以是不同的文件
① 工作目录(GOPATH)
GOPATH是Go中的一个环境变量,他使绝对路径提供项目的工作目录;GOPATH适合处理大量Go语言源码,多个包组合而组成的复杂工程。
- 使用命令行查看GOPATH信息
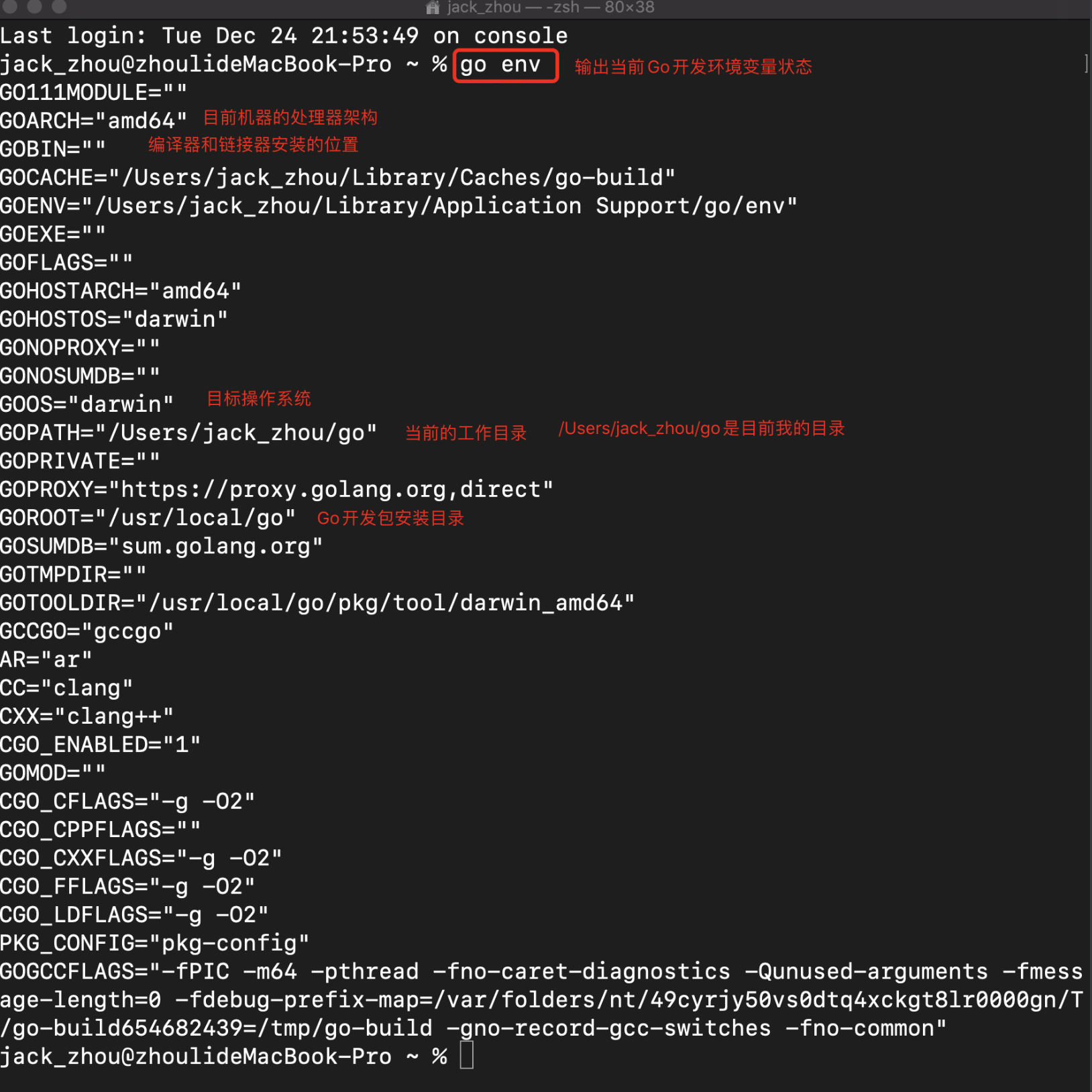
在GOPATH指定目录下。代码总是会保存在$GOPATH/src目录下
在工程中使用go build、go install或者go get等指令后,会将产生的二进制可执行文件放在$GOPATH/bin目录下
生成的中间件缓存文件会被保存在$GOPATH/pkg下。

其实Goland早已为我们做好一切
-
创建包package——编写自己的代码扩展
包(package)是多个go源码集合,是一种高级的代码复用方案,Go语言默认为我们提供很多包,如fmt、os、io包等,当然我们也可以根据我们自己的需求创建自己的包package 包名
包的特性如下:
- 一个目录下的同级文件属于一个包
- 包名可以和其目录不同名
- 包名为main的包为应用程序的入口包,编译源码没有main包时,无法编译输出可执行文件
-
导出标识符 ————让外部访问包的类型和值
在Go语言中,如果想在一个包里引用另外一个包里面的标识符(类型、变量、常量的等)时,必须首先将被引用的标识符导出,将要导出的标识符的首字母大写就可以让引用者进行访问。
举个例子:
package main
var myVar = 100 // 仅能在内部包使用
const MyConst = "what?" // 外部包也可以调用
// 结构体
type MyStruct struct {
PublicField int // 包外可以访问
privateField int // 仅限包内部访问
}
// 接口
type MyInterface interface {
ExportedMethod() // 包外可以访问的方法
privateMethod() // 仅限包内部访问的方法
}
在被导出的结构体或者是接口中,如果他们的字段或者方法是首字母大写的,外部就可以访问这些字段或者方法
-
包的导出
package main import ( "fmt" "go_dev/day1/package_count/calc" ) func main() { fmt.Println(calc.Name) }
当然如果遇到包名一样的情况下我们可以为他改个名
package main
import (
"fmt"
name "go_dev/day1/package_count/calc"
)
func main() {
fmt.Println(name.Name)
}
这样我们就给包换个名字了,类似于Python的import …… as ……
- 匿名导入包
匿名导入包——只导入包,但是不使用包内类型和数值
package main
import (
_ "go_dev/day1/package_count/calc"
)
func main() {
}
那么你可能会问,那既然不使用它的方法和函数或者值,我导入包干什么呢?
因为在Go里面匿名导入的包和其他方式导入包会让导入包编译到可执行文件中,同时,导入包也会触发init函数的调用
- 包在程序启动前的初始化入口:init
在一些需求设计需要程序启动时统一调用程序引用的所有包的初始化函数,如果需要通过开发者手动调用这些初始化函数,那么这个过程可能会发生错误和遗漏。我们希望在引用的包内部,由包的编写者获得代码启动通知,在程序启动时做一些自己包内代码的初始化工作。
举个实际的例子:
为了提高读写数据处理的执行效率,可以在程序启动时,就去加载H5文件,提前在内存中建立索引表,外部程序通过查表的方式迅速获得对应的值,但是索引表不希望的初始化函数的调用不希望由每一个外部使用吹的开发者调用,如果在数据处理的包内有一个机制可以告诉处理函数何时该启动,那么久解决了初始化的问题。
就是这个init函数,特点:
-
每一个源码都可以使用一个init()函数
-
init()函数会在程序执行前也就是main()函数执行前调用
-
调用顺序为main()中引用的包,以深度优先顺序初始化
例如:
假如包的引用关系为:main →A→B→C,那么对应的init()函数的调用顺序为:C.init→B.init→A.init→main
-
同一个包中如果存在多个init那么顺序不可以确定
-
init函数不能够被其他的函数调用
-
init函数的初始化顺序
包的执行顺序包1→包2
对应的init执行顺序包2init→包1init→包1→包2
② 工厂模式自动注册——管理多个包的结构体
/go_dev/xxx/base/factory.go
package base
// 类接口
type Class interface {
Do()
}
var (
// 保存注册好的工厂信息
factoryByName = make(map[string]func() Class)
// 所谓的工厂 就是一个定义func() Class的普通函数。调用此函数,创建一个类实例,实现的工厂内部结构体会实现Class接口
)
// 注册一个类生成工厂
func Register(name string, factory func() Class) {
factoryByName[name] = factory
}
// 根据名称创建对应的类
func Create(name string) Class {
if f, ok := factoryByName[name]; ok {
return f()
} else {
panic("name not found")
}
}
/go_dev/xxx/cls/reg.go
package cls
import (
base "go_dev/xxx/base"
"fmt"
)
// 定义类
type Class struct {
}
// 实现Class的接口
func (c *Class) Do() {
fmt.Println("Class1")
}
func init() {
// 在启动时注册类1工厂
base.Register("Class1", func() base.Class {
return new(Class)
})
}
/go_dev/xxx/main.go
package main
import (
"go_dev/xxx/base"
_ "go_dev/xxx/cls"
)
func main() {
// 根据字符串动态创建一个Class1实例
c1 := base.Create("Class1")
c1.Do()
}
③ 安装第三方包
go get github.com/go-sql-driver/mysql(安装SQL)
会在GOPATH的src目录下安装好
删除包,简单粗暴rm加包名o(╥﹏╥)o
当遇到go get获取不了的包的时候(比如被墙了)
就用gopm来获取无法下载的包
用之前需要go get github.com/gpmgo/gopm
那下载就可以使用gopm get -g golang.org/x/net
换句话讲就是是哟能够gopm get -g代替go get
15, 接口
go中是采用组合来实现对于对象的描述的,详细可见结构体内嵌的描述文字
Go的接口设计是非侵入式的,接口编写者无需知道接口被哪些类型实现。而接口实现者只要知道实现的是一个设么样子的接口,但无需指明是哪一个接口。编译器知道最终编译时候使用哪一个类型实现哪一个接口
① 接口的声明
⑴ 接口声明的格式
每个接口类型由数个方法组成。接口的形式代码如下:
type 接口类型名 interface{
方法名1(参数列表1)返回值列表1
方法名2(参数列表2)返回值列表2
…
}
-
接口类型名:使用type将接口定义为自定义的类型名。Go语言的接口在命名时,一般会在单词后面添加er,如有写操作的接口就叫Writer,关闭的接口就叫Closer
-
方法名:当方法名首字母是大写的时候,且这个接口类型名首字母也是大写的时候,这个方法可以被接口所在的包之外的代码访问到
-
参数列表、返回值列表:参数列表和返回值列表中的参数变量名可以被忽略,比如:
type writer interface { Writer([]byte) error }
Interface类型可以定义一组方法,但这些不需要实现。并且interface不可以包含任何变量。
⑵ 开发中常见的接口以及写法
Go提供的包很多都有接口,比如说io包中提供Writer接口:
type writer interface {
Write(p []byte) (n int, err error)
}
这个接口可以调用Write()方法进行写入一个字节数组,返回值告知写入字节数n和可能发生的错误
类似的,还有将一个对象以字符串形式展现的接口,只要实现了这个接口的类型,在调用String()方法时,都可以忽的对象对应的字符串。在fmt包中定义如下:
type Stringer interface {
String() string
}
Stringer接口在Go语言中的使用频率非常高,功能类似于Java或者C#语言中的ToString的操作
Go每一个接口中的方法数量不会很多。Go希望通过一个接口精准描述它自己的功能,而通过多个接口的嵌入和组合的方式组合将简单的接口扩展为复杂的接口。
package main
import "fmt"
// 定义一个空接口
// 空接口意味着可以被任何类型所实现
func main() {
var a interface{}
var b int
a = b
fmt.Printf("a type is %T", a)
}
⑶ 接口的实现细节
interface类型默认是一个指针
Golang中的接口,不需要显示的实现。只要一个变量,含有接口类型中的所有方法,那么这个变量就实现这个接口,因此golang中没有implement类似的关键字。
如果一个变量含有多个interface类型的方法,那么这个变量就实现了多个接口
② 实现接口的条件
接口的实现需要遵循两条规则才能让接口可用。
条件1:(接口的方法与实现接口的类型方法格式一致)
在类型中添加与接口签名一致的方法就可以实现该方法。签名包括方法中的名称,参数列表,返回参数列表。也就是说,只要实现接口类型中的方法的名称。参数列表,返回参数列表中的任意一项与接口要实现的方法不一致,那么这个接口的这个方法就不会被实现。
为了抽象数据写入的过程,定义DataWriter接口来描述数据写入需要实现的方法,接口中的WriteData()方法表示将数据写入,写入方无需关心写入到哪里。实现接口的类型实现WriteData方法时,会具体编写将数据写入到什么结构中。这里使用file结构体实现DataWriter接口中的Write方法,方法内部只是打印一个日志,不会有数据的写入:
注意:结构体方法如果是值类型就需要注意了
package main
import "fmt"
type Writer interface {
WriteData(data interface{}) error
}
type file struct {
}
func (f *file) WriteData(data interface{}) error {
fmt.Printf("Data:%s", data)
return nil
}
func main() {
// 实例化file
var f = new(file)
// 声明一个Writer的接口
var WriterData Writer // 声明为接口变量
// 将接口赋值给f,也就是*file类型
WriterData = f
// 使用WriteData接口进行数据写入
WriterData.WriteData("data")
}
上列中的关系如下:

当类型无法实现接口时,编译器会报错,常见错误如下:
-
函数名不一致导致的错误
./main.go:23:13: cannot use f (type *file) as type Writer in assignment:
*file does not implement Writer (missing WriteData method)不能将f变量(类型file)视为Writer进行复制。原有:file类型未实现DataWriter接口(丢失WriterData方法)
在上述代码中修改结构体的方法名:
func (f *file) WriteDataX(data interface{}) error { fmt.Printf("Data:%s", data) return nil } -
实现接口的方法签名不一致导致的错误
这次把入参类型变了
func (f *file) WriteData(data string) error { fmt.Printf("Data:%s", data) return nil }: cannot use f (type *file) as type Writer in assignment:
*file does not implement Writer (wrong type for WriteData method)
have WriteData(string) error
want WriteData(interface {}) error期望的是interface{}但是给的是string类型
条件二: 接口中所有方法均被实现
package main
import "fmt"
type Writer interface {
WriteData(data interface{}) error
ReadTable() bool
}
type file struct {
}
func (f *file) WriteData(data interface{}) error {
fmt.Printf("Data:%s", data)
return nil
}
func main() {
// 实例化file
var f = new(file)
// 声明一个Writer的接口
var WriterData Writer // 声明为接口变量
// 将接口赋值给f,也就是*file类型
WriterData = f
// 使用WriteData接口进行数据写入
WriterData.WriteData("data")
}
在上述接口中,我有多定义了一个方法ReadTable,返回的是bool,此时编译的话就会出错
cannot use f (type *file) as type Writer in assignment:
*file does not implement Writer (missing ReadTable method)
Go的接口实现是隐式的,无需让实现接口的类型写出实现了哪些接口,这个设计被称为非侵入式设计
实现者在编写方法是,无法预测未来哪些方法会变成接口。一旦某一个接口被创建出来,要求旧代码实现这个接口时候,就需要修改旧代码的派生部分,一般都会造成雪崩一样的重新编译。
③ 类型和接口之间的关系
一个类型可以实现多个接口
package main
type Socket struct {
}
func (s *Socket) Write(p []byte) (n int, err error) {
return 0, nil
}
func (s *Socket) Close() error {
return nil
}
type Writer interface {
Writer(p []byte) (n int, err error)
}
type Closer interface {
Close() error
}
// 使用io.Writer的代码,并不知道Socket和io.Closer的存在
func usingWriter(writer Writer) {
writer.Writer(nil)
}
// 使用io.Closer的代码,并不知道Socket和io.Writer的存在
func usingCloser(closer Closer) {
closer.Close()
}
func main() {
// 实例化Socket
s := new(Socket)
usingWriter(s)
usingCloser(s)
}
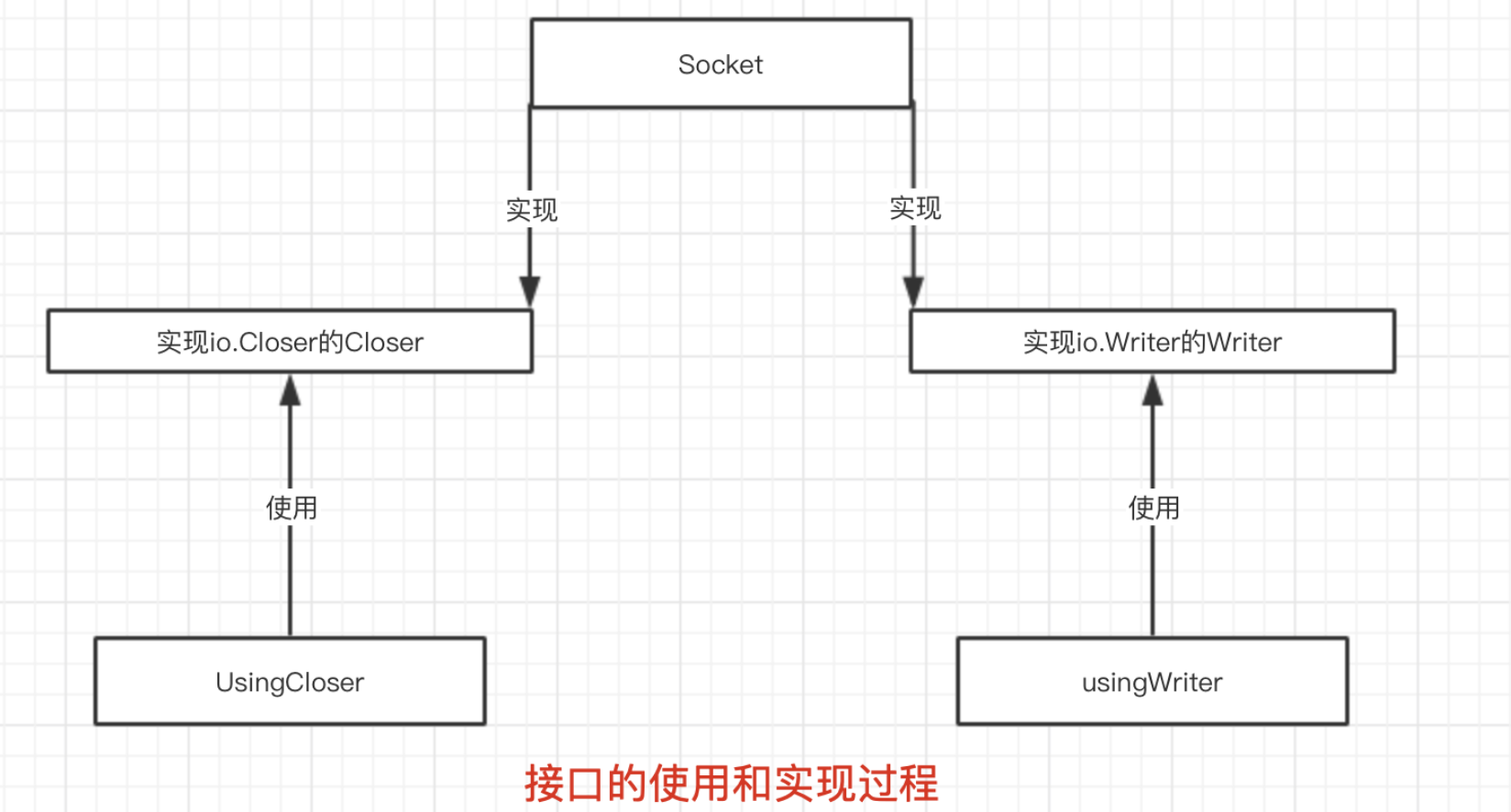
使用Socket实现Writer接口和Closer接口的代码
多个类型可以实现相同的接口
type Service interface {
Start() // 开启服务
Log(string) // 日志输出
}
// 日志器
type Logger struct {
}
// 实现Service的Log方法
func (l *Logger) Log(g string) {
}
type GameService struct {
Logger // 嵌入或者说派生日志器
}
// 实现Service的Start()方法
func (g *GameService) Start() {
}
可以看出Start()由GameService实现,Log()方法由Logger实现
③ 常见类型排序
其实官网有实例的:https://go-zh.org/src/sort/sort.go?s=9423:9455#L332

我们看go的源码可以得到结论,通过sort。Interface接口的排序过程具有很强的可定制性,可以根据被排序对象比较复杂的特性进行定制。
Go 语言在排序时,需要使用者通过sort.interface接口提供数据的一些特性和操作方法。接口定义如上图
也就是说,我们如果需要对自己的自定义类型进行排序的话,就需要实现上图接口的三个方法:数量(Len)、比较(Less)、交换(swap)。
举个例子:
使用sort.interface接口进行排序
对一系列字符串进行排序时,使用字符串切片([]string)承载多个字符串。使用type关键字,将字符串切片([]string)定义为自定义类型MyStringList。为了让sort包能识别MyStringList,能够对MyStringListList进行排序,就必须让MyStringList实现sort.interface接口
package main
import (
"fmt"
"sort"
)
// 将[]string定义为MyStringList类型,取个别名
type MyStringList []string
// 实现sort.interface接口获取元素数量的方法
func (m MyStringList) Len() int {
return len(m)
}
// 实现比较元素的方法
func (m MyStringList) Less(i, j int) bool {
return m[i] < m[j]
}
// 实现接口交换元素的方法
func (m MyStringList) Swap(i, j int) {
m[i], m[j] = m[j], m[i]
}
func main() {
// 准备一个内容被打乱顺序的字符串切片
names := MyStringList{
"3.1",
"2.1",
"5.1",
"1.1",
"9.1",
}
// 使用sort包进行排序
sort.Sort(names)
// sort包会根据MyStringList实现的三个接口方法进行数据的获取和修改
for index, v := range names {
fmt.Printf("索引: %d, 值:%s
", index, v)
}
}
索引: 0, 值:1.1
索引: 1, 值:2.1
索引: 2, 值:3.1
索引: 3, 值:5.1
索引: 4, 值:9.1
例如:需要多种排序逻辑的需求就是和使用sort.Interface接口进行排序。但大部分情况中。只需要对字符串、整形等进行快速排序。Go语言中提供了一些固定模式的封装以方便开发者迅速对内容进行排序。
⑴ 字符串切片的便捷排序
这个是sort包中StringSlice的源码
// StringSlice attaches the methods of Interface to []string, sorting in increasing order.
// StringSlice 针对 []string 实现接口的方法,以升序排列。
type StringSlice []string
func (p StringSlice) Len() int { return len(p) }
func (p StringSlice) Less(i, j int) bool { return p[i] < p[j] }
func (p StringSlice) Swap(i, j int) { p[i], p[j] = p[j], p[i] }
// Sort is a convenience method.
// Sort 为便捷性方法
func (p StringSlice) Sort() { Sort(p) }
可以看到sort包中的StringSlice的代码和MyStringList的实现代码基本一样。因此,只需要使用sort包中StringSlice就可以简单快速的进行字符串排序。
number := sort.StringSlice{
"3.1",
"2.1",
"5.1",
"1.1",
"9.1",
}
sort.Sort(number)
其实本质上讲就是用内建的StringSlice来替代我们模拟的MyStringList,so,很简单的
当然还可以对已经定义为切片的字符串进行排序
names_two := []string{
"3.1",
"2.1",
"5.1",
"1.1",
"9.1",
}
sort.Strings(names_two)
⑵ 对整型切片进行排序
再看源码
// IntSlice attaches the methods of Interface to []int, sorting in increasing order.
type IntSlice []int
func (p IntSlice) Len() int { return len(p) }
func (p IntSlice) Less(i, j int) bool { return p[i] < p[j] }
func (p IntSlice) Swap(i, j int) { p[i], p[j] = p[j], p[i] }
// Sort is a convenience method.
func (p IntSlice) Sort() { Sort(p) }
实现方式和上面一致,两种方式
number := sort.IntSlice{
3,
2,
5,
1,
9,
}
sort.Sort(number)
fmt.Println(number)
number_two := []int{
3,
2,
5,
1,
9,
}
sort.Ints(number_two)
fmt.Println(number_two)
⑶ sort包内建的类型排序接口一览表
| 类型 | 实现sort.interface的类型 | 直接排序的方法 | 说明 |
|---|---|---|---|
| 字符串(string) | StringSlice | sort.Strings(a []string) | ASCII升序 |
| 整型(int) | IntSlice | sort.Ints(a []int) | 数值升序 |
| 双精度浮点(float64) | Float64Slice | sort.Float64s(a []float64) | 数值升序 |
像其他的int32,int64,bool等类型sort包中没有,因此我们需要自己实现。
④ 对结构体进行排序
除了基本类型的排序,也可以对结构体进行排序。但是结构体的字段较多,因此排序规则可能会起冲突,因此需要确立优先级。
⑴ 完整实现sort.interface进行结构体排序
将一批忍者名单使用结构体定义,英雄名单结构体中定义忍者名字和分类。排序时要求按照英雄的分类进行排序,相同分类的情况下按名字进行排序
package main
import (
"fmt"
"sort"
)
// 声明忍者分类
type NinjaKind int
// 定义NinjaKind常量,类似于枚举
const (
None NinjaKind = iota
Attack
Life
Protect
)
// 定义忍者结构
type Ninja struct {
Name string
Kind NinjaKind
}
// 将英雄指针的切片定义为Ninja类型
type MyNinja []Ninja
// 实现sort.interface接口比较元素的方法
func (n MyNinja) Len() int {
return len(n)
}
// 实现比较方法
func (n MyNinja) Less(i, j int) bool {
// 如果忍者分类不一致的时候,有限对分类进行排序
if n[i].Kind != n[j].Kind {
return n[i].Kind < n[j].Kind
}
// 默认按照忍者名字字符升序排列
return n[i].Name < n[j].Name
}
// 实现交换方法
func (n MyNinja) Swap(i, j int) {
n[i], n[j] = n[j], n[i]
}
func main() {
// 忍者列表
ninjas := MyNinja{
Ninja{"千手柱间", Life},
Ninja{"千手扉间", Attack},
Ninja{"宇智波斑", Attack},
Ninja{"波风水门", Protect},
}
sort.Sort(ninjas)
// 遍历忍者
for _, v := range ninjas {
fmt.Printf("%+v
", v)
}
}
⑵ 使用sort.Slice进行切片元素排序
从Go1.8开始,从Go语言在sort包中提供sort.Slice()函数进行更加简单的排序方法。
sort.Slice()函数只要求传入需要排序的数据,以及一个排序时对元素的回调函数,类型为func(i, j int) bool,sort.Slice()函数定义如下:
func Slice (slice interface{}, less func(i, j int) bool)
使用sort.Slice()函数
package main
import (
"fmt"
"sort"
)
// 声明忍者分类
type NinjaKind int
// 定义NinjaKind常量,类似于枚举
const (
None NinjaKind = iota
Attack
Life
Protect
)
// 定义忍者结构
type Ninja struct {
Name string
Kind NinjaKind
}
func main() {
// 忍者列表
ninjas := []Ninja{
Ninja{"千手柱间", Life},
Ninja{"千手扉间", Attack},
Ninja{"宇智波斑", Attack},
Ninja{"波风水门", Protect},
}
sort.Slice(ninjas, func(i, j int) bool {
if ninjas[i].Kind != ninjas[j].Kind {
return ninjas[i].Kind < ninjas[j].Kind
}
// 默认按照英雄名字字符升序排列
return ninjas[i].Name < ninjas[j].Name
})
// 变量忍者
for _, v := range ninjas {
fmt.Printf("%+v
", v)
}
}
使用sort.Slice()不仅可以完成结构体切片排序,还可以对各种切片类型进行自定义排序。
⑤ 接口的嵌套和组合
在Go中不仅仅是结构体和结构体之间可以嵌套,接口与接口间也可以通过嵌套创造出新的接口。
接口和接口嵌套组合成新街口,只要接口的所有方法被实现,则这个接口中的所有嵌套接口的方法可以被调用。
⑴ 系统包中的组合嵌套
Go中的io包中定义了写入器(Write)、关闭器(Closer)和写入关闭器(WriteCloser)3个接口,代码如下:
type Writer interface {
Write(p []byte) (n int, err error)
}
type Closer interface {
Close() error
}
type CloserWriter interface {
Closer
Writer
}
最后一个接口是由前两个接口嵌入构成的,因此,这个接口同时拥有Writer和Closer两个属性
⑵ 在代码中使用接口嵌套组合
在代码中使用io.Writer, io.Closer和io.WriteCloser这三个接口时候,只需要按照接口实现的规则实现io.Writer接口和io.Closer接口即可。而io.WriteCloser接口在使用时,编译器会根据接口的实现者确认他们是否同时实现了io.Writer和io.Closer接口,详细实现代码如下:
package combination
import "io"
type device struct {
}
// 实现io.Writer的Write()方法
func (d *device) Write(p []byte) (n int, err error) {
return 0, nil
}
// 实现io.Closer的Close()方法
func (d *device) Close() error {
return nil
}
func main() {
// 声明写入关闭器,并赋予device的实例
var wc io.WriteCloser = &device{}
//对device进行实例化,由于device实现了io.WriteCloser的所有嵌入接口,因此device指针就会被隐式转化为io..WriteCloser接口
wc.Write(nil)
wc.Close()
//声明写入器,并赋予device的新实例
var writeOnly io.Writer = new(device)
// 写入数据
writeOnly.Write(nil)
}
⑶ 模拟sort的流程
package combination
import "fmt"
type Writer interface {
Write()
}
type Closer interface {
Close()
}
type CloserWriter interface {
Closer
Writer
}
type File struct {
}
func (f *File) Write() {
fmt.Println("Write data")
}
func (f *File) Close() {
fmt.Println("Close data")
}
func Sort(cw CloserWriter) {
// 排序逻辑
cw.Write()
cw.Close()
}
func main() {
var f File
Sort(&f) // 因为结构体的指针实现了接口,但是值没有
}
⑥ 在接口和类型间转换
Go中使用接口断言(type assertions)将接口转换为另外一个接口,也可以将接口转化为另外的类型。接口的转换在开发中相当常见,使用也非常频繁。
⑴ 类型断言的格式
类型断言,由于接口是一般类型,不知道具体类型,如果要转成具体类型可以采用以下方法进行转换
类型断言基本格式如下:
t := i.(T)
- i代表接口变量
- T代表转换的目标类型
- t代表转换后的变量
如果i没有完全实现T接口的方法,这个语句会触发宕机。触发宕机并不是很友好,因此还有另一种写法:
t, ok := i.(T)
这种写法下,如果发生接口未实现,将会把ok设置为false,t设置为T类型的0值
正常实现时,ok为true。这里ok可以被认为是:i接口是否实现T类型的结果。
那么当我们不清楚需要转变为什么类型的时候,也就是说需要动态判断类型的时候,我们应该咋办呢?
func ClassFilter(items...interface{}) {
for _, x := range items{
switch x.(type) { // 用关键字来判定
case bool: fmt.Println("bool")
case float64, float32: fmt.Println("float64")
case nil: fmt.Println("nil")
default:
fmt.Println("米有啦")
}
}
}
⑵ 将接口转为其他接口
实现某个接口的类型同时实现另一个接口,因此可以在两个接口间转换。
鸟和猪具有不同的特性:鸟会飞,但是猪不会,但是他们都会走,如果使用结构体实现鸟和猪,让它们具备自己特性的Fly()和Walk()方法就让鸟和猪各自实现了飞行动物接口(Flyer)和行走动物接口(Walker)
将鸟和猪的实例创建后被保存到interface{}类型的map中。interface{}类型表示空接口,意识就是说这种接口可以保存为任意类型。对保存有鸟或猪的实例的interface{}变量进行断言操作,如果断言对象是断言指定类型,则返回转换为断言对象类型的接口:如果不是指定的断言类型,断言的第二个参数将会返回false。例如下面的代码:
var obj interface = new (bird)
f, isFlyer := obj.(Flyer)
代码中,new(bird)产生*bird类型的bird实例,这个实例被保存在interface{}类型的obj变量中。使用obj.(Flyer)类型断言,将obj转换为Flyer接口。f为转换成功时的Flyer接口类型,isFlyer表示是否转换成功,类型就是bool
package main
import "fmt"
// 定义飞行动物接口
type Flyer interface {
Fly()
}
// 定义行走动物接口
type Walker interface {
Walk()
}
// 定义鸟类
type bird struct {
}
// 实现飞行动物接口
func (b *bird) Fly() {
fmt.Println("bird:fly")
}
// 实现行走动物接口
func (b *bird) Walk() {
fmt.Println("bird:walk")
}
// 定义猪
type pig struct {
}
// 为猪添加Walk()方法,实现行走动物接口
func (p *pig) Walk() {
fmt.Println("pig: walk")
}
func main() {
// 创建动物的名字到实例的映射
animals := map[string]interface{}{
"bird": new(bird),
"pig": new(pig),
}
// 遍历映射
for name, obj := range animals {
// 判断对象是否为飞行动物
f, isFlyer := obj.(Flyer)
// 判断对象是否为行走动物
w, isWalk := obj.(Walker)
fmt.Printf("name: %s is Flyer: %v isWalker: %v
", name, isFlyer, isWalk)
// 如果是飞行动物则调用飞行动物接口
if isFlyer {
f.Fly()
}
// 如果是行走动物则调用行走动物接口
if isWalk {
w.Walk()
}
}
}
name: bird is Flyer: true isWalker: true
bird:fly
bird:walk
name: pig is Flyer: false isWalker: true
pig: walk
⑶ 将接口转换为其他类型
在上一个代码中,可以实现将接口转换为普通指针类型。例如将Walker接口转换为*pig类型
p1 := new(pig)
var a Walker = p1 // 由于pig实现了Walker接口,因此可以被隐式转换为Walker接口类型保存于a中
p2 := a.(*pig)
fmt.Printf("p1=%p p2=%p", p1, p2)
如果将pig 换成bird的话就会报错
p1 := new(pig)
var a Walker = p1 // 由于pig实现了Walker接口,因此可以被隐式转换为Walker接口类型保存于a中
p2 := a.(*bird) // p1并未实现fly接口
fmt.Printf("p1=%p p2=%p", p1, p2)
panic: interface conversion: main.Walker is *main.pig, not *main.bird
接口转换时,main.Walker 接口的内部保存是 *****main.pig,而不是*main.bird
因此,接口在转换为其他类型时候,接口内保存的实例对应的类型指针,必须是要转换的对应类型指针
总结: 接口和其他类型的转换可以在Go语言中自由进行,嵌套是已经完全实现。
接口的断言类似于if。但大量类型断言出现时,影使用更为高效的switch特性。
⑦ 空接口类型(interface{}) ————能保存所有值得类型
空接口是接口类型的特殊形式,空接口没有任何方法,因此任何类型都无需实现空接口。从实现的角度看,任何值都满足这个接口的需求。因此空接口类型可以保存任何值,也可以从空接口中取出原值
使用空接口保存一个数据的过程会比直接用数据对应的类型稍慢,因此在开发过程中,不要在所有的地方使用空接口
⑴ 将值保存到空接口
空接口的赋值如下:
var any interface {}
any = 1
fmt.Prinln(any)
先为any赋值一个整形1,但是any的类型还是interface{}
⑵ 从空接口获取值
保存到空接口的值,如果直接取出指定类型的值是,会发生编译错误,代码如下:
package main
func main() {
var a int = 1
// 声明i变量,类型为 interface{},初始值为a,此时i的值变成1
var i interface{} = a
// 声明b变量,尝试赋值i
var b int = i
}
报错如下:
cannot use i (type interface {}) as type int in assignment: need type assertion
在代码中,我们可以将a赋值给i,虽然i在赋值完成后的内部值为int,但i还是interface{}类型的变量。类似于无论集装箱装的是什么,集装箱依旧是集装箱,不会因为装了东西就改变了集装箱的本质
为了可以转换不出错,编译器提示我们:need type assertion,意思就是类型断言
那么修改代码如下:
package main
import "fmt"
func main() {
var a int = 1
// 声明i变量,类型为 interface{},初始值为a,此时i的值变成1
var i interface{} = a
// 声明b变量,尝试赋值i
b, ok := i.(int)
fmt.Println(b, ok)
}
修改后,代码就可以编译通过,并且b可以获得i变保存的a变量的值:1
⑶ 空接口值的比较
空接口在保存不同的值后,可以和其他变量值一样使用“==”进行比较操作。空接口的比较有以下特性:
Ⅰ 类型不同的空接口间的比较结果不协调
保存有类型不同的值得空接口进行比较时,Go会优先比较值得类型。因此类型不同,比较结果也是不相同的。
package main
import "fmt"
func main() {
var a interface{} = 100
var b interface{} = "b"
// 两个空接口不相等
fmt.Println(a == b)
// 结果false
}
Ⅱ 不能比较空接口中的动态值
当接口中保存有动态类型的值时,运行时将触发错误,代码如下:
package main
import "fmt"
func main() {
// c 保存包含100的整形切片
var c interface{} = []int{100}
var d interface{} = []int{200}
// 将会引发崩溃
fmt.Println(c == d)
}
Ⅲ 类型的可比较性
| 类型 | 说明 |
|---|---|
| map | 宕机 |
| 切片([]T) | 宕机 |
| 通道(channel) | 可比较,必须由同一个make生成,也就是同一个通道才是true,否则是false |
| 数组([容量]T) | 可比较 |
| 结构体 | 可比较,逐个比较结构体的值 |
| 函数 | 可比较 |
⑧ 类型分支————批量判断空接口中变量的类型
/*
switch 实现类型分支时写法格式如下:
switch 接口变量.(type) {
case 类型1:
// 处理逻辑
case 类型2:
// 处理逻辑
……
default:
// 变量不是所有case中列举的类型时的处理
}
*/
要注意,判断用的是接口类型进行判断!
⑨ 综合示例:
实现有限状态机(FSM)
有限状态机,表示有限个状态及在这些状态间的转移和动作等行为的数学模型。
1,状态的概念
状态机中的状态与状态间能够自由转换,但是现实中的状态却不一定能够自由转换,举个例子:人可站立状态变成跑步状态,也可以变成卧倒状态,但是不能从卧倒直接变成跑步状态。
因此每一个状态可以设置他可以转移到的状态,一些状态机还准许在同一个状态间相互转换,这个也需要根据实际情况进行配置。
2,自定义状态需要实现的接口
有限状态机系统需要制定一个状态需具备的属性和功能,由于状态需要由由用户自定义,为了统一管理状态,就需要使用接口定义状态。状态机从状态接口查询到用户的自定义状态就应该具备的属性。
-
名称,对应state接口的Name()方法
-
状态是否允许在同状态间转移,对应State接口的EnableSameTransit()方法。
-
能否从当前状态转移到指定的某一个状态,对应State接口的CanTransitTo()方法,除此之外,状态在转移时会发生的事件可以有状态机通过状态接口的方法通知用户自己的状态,对应的两个方法OnBegin()和OnEnd(),分别代表状态转移前和状态转移后。
代码如下:(state.go)
package state_trainsit import "reflect" type State interface { // 获取状态的名字 Name() string // 该状态是否允许同状态转移 EnableSameTransit() bool // 响应状态开始时 OnBegin() // 响应状态结束时 OnEnd() // 判断能否转移到某个状态 CanTransitTo(name string) bool } // 从状态实例获取状态名 func StateName(s State) string { if s == nil { return "none" } // 使用反射获取状态的名称 return reflect.TypeOf(s).Elem().Name() }
3, 状态基本信息
State接口中定义的方法,在用户自定义时都是重复的,为了避免重复编写代码,使用StateInfo来协助用户实现一些默认的实现。
StateInfo包含有名称,在状态初始化的时候被赋值。StateInfo同时实现了OnBegin()、OnEnd()方法。此外,StateInfo的EnableSameTransit()方法还能判断是否允许状态在同类状态中转移,CanTransiTo()方法能判断是否能转移到某个目标状态,详细实现如下:
package state_trainsit
// 状态的基础信息和默认实现
type StateInfo struct {
// 状态名
name string
}
// 状态名
func (s *StateInfo) Name() string {
return s.name
}
// 提供给内部设置名字
func (s *StateInfo) setName(name string) { // 表示不能被使用者在初始化状态后随意修改名称,而是被后面的状态管理器自动复制
s.name = name
}
// 允许同状态转移
func (s *StateInfo) EnableSameTransit() bool {
return false
}
// 默认将状态开启时实现
func (s *StateInfo) OnBegin() {
}
// 默认将状态结束时实现
func (s *StateInfo) OnEnd() {
}
// 默认可以转移到任何状态
func (s *StateInfo) CanTransitTo(name string) bool {
return true
}
4, 状态管理
状态管理器管理和维护状态的生命周期。用户根据需要,将需要进行状态转移和控制的状态实现后添加(StateManager的Add()方法)到状态管理器里,状态管理器使用名称对这些状态进行维护,同一个状态只允许一个实例存在。状态管理器使用名称对这些状态进行维护,同一个状态只允许一个实例存在。状态管理器可以通过回调函数(StateManager的OnChange成员)通过状态转移的通知。状态管理器对状态的管理和维护代码如下:
statemgr.go文件
package main
import "errors"
// 状态没有找到的错误
var ErrStateNotFound = errors.New("state not found")
// 禁止在同状态间转移
var ErrForbidSameStateTransit = errors.New("forbid same state transit")
// 不能转移到指定状态
var ErrCannotTransitToState = errors.New("cannot transit to state")
// 状态管理器
type StateManager struct {
// 已经添加的状态
stateByName map[string]State
// 状态改变时的回调
OnChange func(from, to State)
// 当前状态
curr State
}
// 添加一个状态到管理器
func (sm *StateManager) Add(s State) {
// 获取状态的名称
name := StateName(s)
// 将s转换为能设置名字的接口,然后调用接口
s.(interface {
setName(name string)
}).setName(name) // 通过类型断言转换为带有setName()方法(name string)的接口。接着调用这个接口的setName()方法设置状态名称。使用该方法可以快速调用另一个接口实现其他方法
// 根据状态名取已经添加的状态,检查是否已经存在
if sm.Get(name) != nil {
panic("duplicate state:" + name)
}
// 根据名字保存到map中
sm.stateByName[name] = s
}
// 根据名字获取指定状态
func (sm *StateManager) Get(name string) State {
if v, ok := sm.stateByName[name]; ok {
return v
}
return nil
}
// 获取当前的状态
func (sm *StateManager) CurrState() State {
return sm.curr
}
// 当前状态能否转移到目标状态
func (sm *StateManager) CanCurrTransitTo(name string) bool {
if sm.curr == nil {
return true
}
// 相同的不用转换
if sm.curr.Name() == name && !sm.curr.EnableSameTransit() {
return false
}
// 使用当前状态,检查能否转移到指定名字的状态
return sm.curr.CanTransitTo(name)
}
// 转移到指定状态
func (sm *StateManager) Transit(name string) error {
// 获取目标状态
next := sm.Get(name)
// 目标不存在
if next == nil {
return ErrStateNotFound
}
// 记录转移前的状态
pre := sm.curr
// 当前有状态
if sm.curr != nil {
// 相同的状态不用转换
if sm.curr.Name() == name && !sm.curr.EnableSameTransit() {
return ErrForbidSameStateTransit
}
// 不能转移到目标状态
if !sm.curr.CanTransitTo(name) {
return ErrCannotTransitToState
}
// 结束当前状态
sm.curr.OnEnd()
}
// 将当前状态切换为要转移到的目标状态
sm.curr = next
// 调用新状态的开始
sm.curr.OnBegin()
// 通知回调
if sm.OnChange != nil {
sm.OnChange(pre, sm.curr)
}
return nil
}
// 初始化状态管理器
func NewStateManager() *StateManager {
return &StateManager{
stateByName: make(map[string]State),
}
}
5,在状态间转移
状态管理器不仅管理状态的实例,还可以控制当前的状态及转移到新的状态。状态管理器从当前状态转移到给定名称的状态过程中,如果发现状态不存在,目标状态不能转移和同类不能转移时,将返回error错误对象,这些错误以Err开头,在包(package)里提前定义好
6, 最终的main
package main
import (
"fmt"
)
// 闲置状态
type IdleState struct {
StateInfo // 使用StateInfo实现基础接口
}
// 重新实现状态开始
func (i *IdleState) OnBegin() {
fmt.Println("IdleState begin")
}
// 重新实现状态结束
func (i *IdleState) OnEnd() {
fmt.Println("IdleState end")
}
// 移动状态
type MoveState struct {
StateInfo
}
func (m *MoveState) OnBegin() {
fmt.Println("MoveState begin")
}
// 允许移动状态互相转换
func (m *MoveState) EnableSameTransit() bool {
return true
}
// 跳跃状态
type JumpState struct {
StateInfo
}
func (j *JumpState) OnBegin() {
fmt.Println("JumpState begin")
}
// 跳跃状态不能转移到移动状态
func (j *JumpState) CanTransitTo(name string) bool {
return name != "MoveState"
}
// 封装转移状态和输出日志
func transitAndReport(sm *StateManager, target string) {
if err := sm.Transit(target); err != nil {
fmt.Printf("FAILED! %s --> %s, %s
", sm.CurrState().Name(), target, err.Error())
}
}
func main() {
// 实例化一个状态管理器
sm := NewStateManager()
// 响应状态转移的通知
sm.OnChange = func(from, to State) {
// 打印状态转移的流向
fmt.Printf("%s ---> %s
", StateName(from), StateName(to))
}
// 添加3个状态
sm.Add(new(IdleState))
sm.Add(new(MoveState))
sm.Add(new(JumpState))
// 在不同状态间转移
transitAndReport(sm, "IdleState")
transitAndReport(sm, "MoveState")
transitAndReport(sm, "MoveState")
transitAndReport(sm, "JumpState")
transitAndReport(sm, "JumpState")
transitAndReport(sm, "IdleState")
}
16, 反射
在Go中使用reflect.TypeOf()函数可以获取任意值的类型对象(reflect.Type)程序通过类型对象可以访问任意值的类型信息。
反射可以在运行时动态的获取变量的相关信息
- reflect.TypeOf,获取变量类型,返回的是reflect.Type类型
- reflect.ValueOf,获取变量的值,返回reflect.Value类型
- reflcet.Value.Kind,获取变量的类别,则返回一个常量
- reflect.Value.Interface(),转换为interface{}类型
package main
import (
"fmt"
"reflect"
)
func main() {
var a int
typeOfA := reflect.TypeOf(a)
fmt.Println(typeOfA.Name(), typeOfA.Kind())
}
① 理解反射的类型(Type)与种类(Kind)
在使用反射时,需要首先理解类型(Type)和种类(Kind)的区别。编程中,使用最多的是类型,但是在反射中,当需要区分一个大的品种类型的时候,就会用到种类(Kind)。例如,需要统一判断类型中的指针时,使用种类(Kind)信息就比较方便。
-
反射种类Kind的定义
Go中的类型(Type)指的是系统原生数据类型,如int、string、bool等以及使用type关键字定义的类型,这些类型的名称就是其类型本身的名称。例如:使用type A struct{} 定义结构体时,A就是struct{}的类型
种类(Kind)指的是对象归属的品种,在reflect包中有如下定义:
const ( Invalid Kind = iota // 非法类型 Bool Int Int8 Int16 Int32 Int64 Uint Uint8 Uint16 Uint32 Uint64 Uintptr Float32 Float64 Complex64 // 64位复数类型 Complex128 Array // 数组 Chan // 通道 Func Interface Map // 映射 Ptr // 指针 Slice String Struct UnsafePointer // 底层指针 )Map、Slice、Chan属于引用类型,使用起来类似指针,但是在种类常量定义中任然属于独立的种类,不属于Ptr
type A struct{} 定义的结构体属于Struct种类,A属于Ptr*
-
从类型对象中获取类型名称和种类的例子
Go语言中的类型名称对应的反射获取方法是reflect.Type中的Name()方法,返回表示类型名称的字符串
类型归属的种类(Kind)使用的是reflect.Type中的Kind()方法,返回的是reflect.Kind类型中的常量
package main import ( "fmt" "reflect" ) // 定义一个Enum类型 type Enum int const ( Zero Enum = 0 ) func main() { // 声明一个空结构体 type cat struct { } // 获取结构体实例的反射类型对象 typeOfCat := reflect.TypeOf(cat{}) // 显示反射类型对象的名称和种类 fmt.Println(typeOfCat.Name(), typeOfCat.Kind()) // 获取Zero常量的反射类型对象 typeOfA := reflect.TypeOf(Zero) // 显示反射类型对象的名称和种类 fmt.Println(typeOfA.Name(), typeOfA.Kind()) }结果如下:
cat struct
Enum int
② 指针与指针指向的元素
Go 对指针获取反射对象时,可以通过reflect.Elem()方法获取这个指针指向的元素类型。这个获取的过程被称为取元素,等效于对指针类型变量做了一个“*”操作,代码如下:
package main
import (
"fmt"
"reflect"
)
func main() {
// 声明一个空结构体
type cat struct {
}
// 获取结构体实例的反射类型对象
typeOfCat := reflect.TypeOf(cat{})
typeOfCats := reflect.TypeOf(&cat{})
fmt.Printf("Names:%s; Kinds:%s
", typeOfCats.Name(), typeOfCats.Kind())
typeOfCats = typeOfCats.Elem()
// 显示反射类型对象的名称和种类
fmt.Printf("Name:%s; Kind:%s
", typeOfCat.Name(), typeOfCat.Kind())
fmt.Printf("Names:%s; Kinds:%s", typeOfCats.Name(), typeOfCats.Kind())
}
Names:; Kinds:ptr
Name:cat; Kind:struct
Names:cat; Kinds:struct
在Go语言中所有反射的指针变量都是ptr,但注意:指针变量的类型名称是空!
③ 使用反射获取结构体的成员类型
任意值通过reflect.TypeOf()获得反射对象信息后,如果他的类型是结构体,可以通过反射值对象(reflect.Type)的NumField()和Field()方法获得结构体成员的详细信息。与成员获取相关的reflect.Type的方法如下表。
| 方法 | 说明 |
|---|---|
| Field(i int) StructField | 根据索引,返回索引对应的结构体字段的信息。当值不是结构体或索引超界时引发的宕机 |
| NumField() int | 返回结构体成员字段数量。当类型不是结构体或索引超界时发生宕机 |
| FieldByName(name string) (structField, bool) | 根据给定字符串返回字符串对应的结构体字段的信息。没有找到时bool返回false,当类型不是结构体或索引超界引发的宕机 |
| FieldByIndex(index []int) StructField | 多层成员访问时,根据[]int提供的每个结构体的字段索引,返回字段的信息。没有找到时返回零值。当类型不是结构体或索引超界时发生宕机 |
| FieldByNameFunc(match func(string) bool) (StructField, bool) | 根据匹配函数匹配需要的字段。当值不是结构体或索引超界时发生宕机。 |
1, 结构体字段类型
reflect.Type的Field()方法返回StructField结构,这个结构描述结构体的成员信息,通过这个信息可以获取成员和结构体的关系,如偏移,索引,是否为匿名字段、结构体标签(Struct Tag)等,而且还可以通过StructField的Type字段进一步获取结构体成员的类型信息,StructField的结构如下:
type StructField struct {
Name string // 字段名
PkgPath string // 字段路径
Type Type // 字段反射类型对象reflect.Type
Tag StructTag // 字段在结构体标签,为结构体字段标签的额外信息,可以单独提取
Offset uintptr // 字段在结构体中的相对偏移
Index []int // Type.FieldByIndex中的返回索引值(索引顺序)
Anonymous bool // 是否为匿名字段
}
2, 获取成员反射信息
下面代码中,实例化一个结构体并遍历其结构体成员,在通过reflect.Type的FieldByName()方法查找结构体中指定名称的字段,直接获取其类型信息。
package main
import (
"fmt"
"reflect"
)
func main() {
// 声明一个空结构体
type Cat struct {
Name string
// 带有结构体tag的字段
Type int `json:"type" id:"100"` // 增加Tag
}
// 创建cat实例
ins := Cat{Name: "mimi", Type: 1}
// 获取结构体实例的反射类型对象
typeOfCat := reflect.TypeOf(ins)
// 遍历结构体所有成员
for i := 0; i < typeOfCat.NumField(); i++ {
// 获取每个成员的结构体字段类型
fieldType := typeOfCat.Field(i)
// 输出成员名称和tag
fmt.Printf("name: %v tag:'%v'
", fieldType.Name, fieldType.Tag)
}
// 通过字段名,找到字段类型信息
if catType, ok := typeOfCat.FieldByName("Type"); ok {
// 从tag中取出需要的tag
fmt.Println(catType.Tag.Get("json"), catType.Tag.Get("id"))
}
}
使用reflect.Type()类型的NumField()方法获得一个结构体类型共有多少个字段。如果类型不是结构体,将会触发宕机错误;
一般reflect.Type()中的Field()方法和NumField()一般都是配对使用,用来实现结构体成员的遍历操作;
使用reflect.Type的Field()方法和FieldByName()返回的结构不再是reflect.Type而是StructField结构体;
④ 结构体标签(Struct Tag)————对结构体字段的额外信息标签
通过reflect.Type获取结构体成员信息reflect.StructField结构中的Tag被称为结构体标签(Struct Tag)
JSON、BSON等格式进行序列化及对象关系映射(object Relational Mapping,简称ORM)系统都会利用到结构体标签,这些系统使用标签设定字段在处理时应该具备特殊的属性和可能发生的行为。这些信息都是静态的,无须实例化结构体,可以通过反射获取到;
1, 结构体标签的格式
Tag在结构体字段后方书写的格式如下:
`key1:"value" key2:"value2"`
结构体标签由一个或多个键值对组成。键与值使用冒号分隔,值用双引号括起来。键值对之间使用一个空格分隔。
2, 从结构体标签中获取值
StructTag有一些方法,可以进行Tag的解析和提取:
-
func (tag StructTag) Get(key string) string: 根据Tag中的键获取对应的值,例如
`key1:"value" key2:"value2"`中的Tag中,可以传入”key1“获得”value“。
-
func (tag StructTag) Lookup(key string) (value string, ok bool):根据Tag中的键,查询是否存在。
3, 结构体标签错误导致的问题
编写Tag时,必须严格遵守键值对的规则。结构体标签的解析代码的容错能力很差,一旦格式错误,编译和运行都不会提示任何错误!
package main
import (
"fmt"
"reflect"
)
func main() {
type cat struct {
Name string
Type int `json: "type" id:"100"` // 注意json:后面多一个空格
}
typeOfCat := reflect.TypeOf(cat{"zhou", 1})
if catType, ok := typeOfCat.FieldByName("Type"); ok {
fmt.Println(catType.Tag.Get("json"))
}
}
⑤ 反射的值对象(reflect.Value)
反射不仅可以获取值类型信息,还可以动态的获取或者设置变量的值。Go语言中使用reflect.Value获取和设置变量的值
1,使用反射值对象包装任意值
Go语言中,使用reflect.ValueOf()函数获得值得反射值对象(reflect.Value)。书写格式如下:
value := reflect.ValueOf(rawValue)
Reflect.ValueOf()返回reflect.Value类型,包含有rawValue的值信息。reflect.Value与原值间可以通过值包装和值获取相互转化。reflect.Value是一些反射操作的重要类型。如反射调用函数。
2,从反射值对象获取被包装的值
Go可以通过reflect.Value重新获得原始值
⑴ 从反射值对象(reflect.Value)中获取值得方法
| 方法 | 说明 |
|---|---|
| Interface() interface{} | 将值以interface{}类型返回,可以通过类型断言转换为指定类型 |
| Int() int64 | 将值以int类型返回,所有有符号整形均可以此方式返回 |
| Uint() uint64 | 将值以uint类型返回,所有无符号整形均可以此方式返回 |
| Float() float64 | 将值以双精度(float64)类型返回,所有浮点数(float32、float64)均可以此方式返回 |
| Bool bool | 将值以bool类型返回 |
| Bytes() []bytes | 将值以字节数组[]bytes类型返回 |
| String() string | 将值以字符串类型返回 |
⑵ 从反射值对象(reflect.Value)中获取值的例子
下面代码中,将整形变量中使用reflect.Value获取反射值对象(reflect.Value)。
再通过reflect.Value的Interface()方法获得interface{}类型的原值,通过int类型对应的reflect.Value的Int()方法获得整形值。
package main
import (
"fmt"
"reflect"
)
func main() {
// 声明整形变量a并赋初值
var a int = 1024
// 获取变量a的反射值对象
valueOfA := reflect.ValueOf(a)
// 获取interface{}类型的值,通过类型断言转换
var getA int = valueOfA.Interface().(int) // 将ValueOf反射值对象通过interface()方法,以interface{}类型取出,通过类型断言变成int
// 获取64的值,强制类转换为int类型
var getA2 int = int(valueOfA.Int()) // 将ValueOf反射值对象通过Int()方法,以int64类型取出,通过强制类型转换,转为int
fmt.Println(getA, getA2)
}
⑥ 使用反射访问结构体成员字段的值
反射值对象(reflect.Value)提供对结构体访问的方法,通过这些方法可以完成对结构体任意值的访问
| 方法 | 说明 |
|---|---|
| Field(i int) Value | 根据索引,返回索引对应的结构体成员字段的反射值对象。当值不是结构体或索引超界时发生宕机 |
| NumField() int | 返回结构体成员字段数量。当值不是结构体护着索引超界的时候发生宕机 |
| FieldByName(name string) Value | 根据给定字符串返回字符创对应的结构体字段。没有找到时返回零值,当值不是结构体或索引超界时发生宕机 |
| FieldByIndex(index []int) Value | 多层成员访问时,根据[]int提供的每个结构体的字段索引,返回字段的值。没有找到时返回零值,当值不是结构体或索引超界时发生宕机 |
| FieldByNameFunc(matchfunc(string) bool) Value | 根据匹配函数匹配需要的字段。找到时返回零值,当值不是结构体或索引超界时引发宕机 |
| Method(n).Call([]reflect.Value) | 调用结构体中的方法(n表示第几个方法,从0开始) |
| Type() | 将result.Value转为reflect.Type |
下面构造一个结构体包含不同类型的成员。通过reflect.Value提供的成员访问函数,可以获得结构体值得各种数据。
package main
import (
"fmt"
"reflect"
)
type dummy struct {
a int
b string
// 嵌入字段
float32
bool
next *dummy
}
func main() {
d := reflect.ValueOf(dummy{next: &dummy{}})
// 获取字段数量
fmt.Println("NumField", d.NumField())
// 获取索引为2的字段(float32字段)
floatField := d.Field(2)
// 输出字段类型
fmt.Println("Field", floatField.Type())
// 根据名字查找字段
fmt.Println("FieldByName", d.FieldByName("b").Type())
// 根据索引查找值中,next字段的int字段的值
fmt.Println("FieldByIndex", d.FieldByIndex([]int{4, 0}).Type())
}
注意:
[]int{4, 0}中的4表示,在dummy结构中索引值为4的成员,也就是next。next的类型为dummy,也是一个结构体,因此使用[]int{4,0}中的0继续在next值得基础上索引,结构为dummy的索引值为0的a字段,类型为int。
NumField 5
Field float32
FieldByName string
FieldByIndex int
package main
import (
"fmt"
"reflect"
)
type T struct {
A string
B int
}
func main() {
t := T{"qq", 11}
s := reflect.ValueOf(&t).Elem()
typeOfT := s.Type()
fmt.Println(typeOfT)
var b interface{} = typeOfT
if result, ok := b.(reflect.Type); ok {
fmt.Println(result)
}
//fmt.Println(reflect.TypeOf(typeOfT))
for i := 0; i < s.NumField(); i++ {
f := s.Field(i) // 返回的也是value对象
var c interface{} = f
if result, ok := c.(reflect.Value); ok {
fmt.Println(result)
}
fmt.Println(typeOfT.Field(i).Name, f.Type(), f.Interface(), )
}
s.Field(0).SetString("qw")
s.Field(1).SetInt(22)
fmt.Println(t)
}
main.T
main.T
qq
A string qq
11
B int 11
{qw 22}
⑦ 反射对象的空和有效性判断
反射值对象(reflect.Value)提供一系列方法进行零值和空判定
| 方法 | 说明 |
|---|---|
| Is.Nil() bool | 返回值是否为nil,如果值类型不是通道(channel)、函数、接口、map、指针或切片时发生panic,类似于语言层的”v == nil“操作 |
| IsValid() bool | 判断值是否有效。当值本身非法时,返回false,例如reflect Value不包含任何值,值为nil等 |
下面的例子将会对各种方式的空指针进行IsNil和IsVaild的返回值判定检测。同时对结构体成员及方法查找map键值对的返回值进行IsValid判定
package main
import (
"fmt"
"reflect"
)
func main() {
// *int的空指针
var a *int
fmt.Println("var a *int:", reflect.ValueOf(a).IsNil())
// nil值
fmt.Println("nil:", reflect.ValueOf(nil).IsValid())
// *int类型的空指针
fmt.Println("(*int)(nil):", reflect.ValueOf((*int)(nil)).Elem().IsValid())
/* (*int)(nil)的含义是将nil转换为*int,也就是*int类型的空指针。此行将nil转换为*int类型,并取指针指向元素。由于nil不指向任何元素,*int
类型的nil也不能指向任何元素,值不是有效的。因此这个反射值使用IsValid判断返回false */
// 实例化一个结构体
s := struct{}{}
// 尝试从结构体查找一个不存在的字段
fmt.Println("不存在的结构体成员:", reflect.ValueOf(s).FieldByName("").IsValid())
// 尝试从结构体中查找一个不存在的方法
fmt.Println("不存在的结构体方法:", reflect.ValueOf(s).MethodByName("").IsValid())
// 实例化一个map
m := map[int]int{}
// 尝试从map中查找一个不存在的键
fmt.Println("不存在的键:", reflect.ValueOf(m).MapIndex(reflect.ValueOf(3)).IsValid())
}
var a int: true
nil: false
(int)(nil): false
不存在的结构体成员: false
不存在的结构体方法: false
不存在的键: false
⑧ 使用反射值对象修改变量的值
使用反射reflect.Value对包装的值进行修改时,需要遵循一些规则。如果没有按照规则进行代码设计和编写,有可能会引发宕机。
1, 判定及获取元素的相关方法
使用reflect.Value取元素、取地址及修改值得属性方法参照下表。
| 方法 | 说明 |
|---|---|
| Elem() Value | 取值指向的元素值,类似于语言层的”*“操作。当值类型不是指针或接口时发生宕机,空指针时返回nil的Value |
| Add() Value | 对可寻址的值返回其地址,类似语言层的”&“操作。当值不可寻址时发生宕机 |
| CanAdd() bool | 表示值是否可寻址 |
| CanSet() bool | 返回值是否能够修改,要求值可寻址且是导出的字段 |
2,值修改相关方法
| Set(x Value) | 将值设置为传入的反射值对象的值 |
|---|---|
| SetInt(x int64) | 使用int64设置值。当值得类型不是int、int8、int16、int32、int64时发生宕机 |
| SetUint(x uint64) | 使用uint64设置值。当值得类型不是uint、uint8、uint16、uint32、uint64时发生宕机 |
| SetFloat(x float64) | 使用float64设置值。当值类型不是float32、float64发生宕机 |
| SetBool(x bool) | 使用bool设置值,当值类型不是bool类型发生宕机 |
| SetBytes(x []byte) | 设置字节数组[]bytes值。当值不是[]byte发生宕机 |
| SetString(x string) | 设置字符串值。当值得类型不是string时发生宕机 |
以上方法在reflect.Value的CanSet返回false仍然修改值时会发生宕机
在已知值得类型时,应尽量使用值对应类型的反射设置值。
3, 值可修改条件之一:可被寻址
通过反射修改变量值的前提条件之一:这个值必须可以被寻址。简单的说就是这个变量必须能够被修改。
package main
import "reflect"
func main() {
// 声明整形变量a并赋初始值
var a int = 1024
// 获取变量a的反射值对象
valueOfA := reflect.ValueOf(a)
// 尝试将a修改为1(此处会崩溃)
valueOfA.SetInt(1)
}
程序运行出错,打印错误:
panic: reflect: reflect.flag.mustBeAssignable using unaddressable value
报错含义:reflect.flag.mustBeAssignable(使用不可寻址的值)。
从reflect.ValueOf传入的是a的值,并不是a的地址,这个reflect.Value当然是不能被寻址的。将代码修改一下,重新运行一下:
package main
import (
"fmt"
"reflect"
)
func main() {
// 声明整形变量a并赋初始值
var a int = 1024
// 获取变量a的反射值对象
valueOfA := reflect.ValueOf(&a) // 此时reflect.ValueOf()返回的valueOfA持有变量a的地址
// 取出a地址的元素(a的值)
valueOfA = valueOfA.Elem() // 使用Elem()方法获取a地址的元素,也就是a的值。reflect.Value的Elem()方法返回值类型也是reflect.Value
// 尝试将a修改为1(此处就不会崩溃)
valueOfA.SetInt(1) // 此时valueOfA表示的a的值并且可以寻址,因此不再崩溃
fmt.Println(a)
}
当reflect.Value不可寻址时候,使用Addr()方法也是无法获取到值的地址,同时会发生宕机。虽然说reflect.Value的Addr()方法类似于语言层的”&“操作;Elem()方法类似于语言层的”*“操作,但并不代表这些操作是等效的
4, 值可修改条件之一:被导出
结构体成员中,如果字段没有被导出,即便不使用反射也可以被访问,但不能通过反射修改,代码如下:
package main
import "reflect"
func main() {
type dog struct {
legCount int
}
// 获取dog实例的反射值对象
valueOfDog := reflect.ValueOf(dog{})
// 获取legCount字段的值
vLegCount := valueOfDog.FieldByName("legCount")
// 尝试设置legCount的值(这里会发生崩溃)
vLegCount.SetInt(4)
}
报错:panic: reflect: reflect.flag.mustBeAssignable using value obtained using unexported field
报错的意思:SetInt()使用之来自于一个未导出字段。
所以修改字段为大写
package main
import "reflect"
func main() {
type dog struct {
LegCount int
}
// 获取dog实例的反射值对象
valueOfDog := reflect.ValueOf(dog{})
// 获取legCount字段的值
vLegCount := valueOfDog.FieldByName("LegCount")
// 尝试设置legCount的值(这里会发生崩溃)
vLegCount.SetInt(4)
}
我擦,又报错?
panic: reflect: reflect.flag.mustBeAssignable using unaddressable value
仔细看一下,我们穿到ValueOf中的是结构体的值,所以,我们改传指针,并调用Elem()方法进行取值
package main
import "reflect"
func main() {
type dog struct {
LegCount int
}
// 获取dog实例的反射值对象
valueOfDog := reflect.ValueOf(&dog{}).Elem()
// 获取legCount字段的值
vLegCount := valueOfDog.FieldByName("LegCount")
// 尝试设置legCount的值(这里会发生崩溃)
vLegCount.SetInt(4)
}
⑨ 通过类型创建类型的实例
当已知reflect.Type时,可以动态的创建这个类型的实例,实例的类型为指针。例如:reflect.Type的类为int时,创建int的指针,即*int,代码如下:
package main
import (
"fmt"
"reflect"
)
func main() {
var a int
// 取变量a的反射类型对象
typeOfA := reflect.TypeOf(a)
// 根据反射可续对象创建类型实例
aIns := reflect.New(typeOfA)
// 使用reflect.New()函数传入变量a的反射类型对象,创建这个类型的实例值,值以reflect.Value类型返回。这步等效于:new(int),因此返回的是*int实例
// 输出Value的类型和种类
fmt.Println(aIns.Type(), aIns.Kind())
}
⑩ 使用反射调用函数
如果反射值对象(reflect.Value)中的值得类型为函数时,可以通过reflect.Value调用该函数。使用反射调用函数时,需要将参数使用反射值对象的切片[]reflect.Value构造后传入Call()方法中,调用完成时,函数的返回值通过[]reflect.Value返回
下面声明一个加法函数,传入两个整形值,返回两个整形值得和。将函数保存到反射值对象(reflect.Value)中,然后将两个整形值构造为反射值对象的切片[]reflect.Value,使用Call()方法进行调用。
package main
import (
"fmt"
"reflect"
)
func add(a, b int) int {
return a + b
}
func main() {
// 将函数包装为反射值对象
funcValue := reflect.ValueOf(add)
// 构造函数参数,传入两个整型值
paramList := []reflect.Value{reflect.ValueOf(10), reflect.ValueOf(20)}
// 反射调用函数
retList := funcValue.Call(paramList)
// 获取第一个返回值,取整数值
fmt.Println(retList[0].Int())
}
反射调用函数的过程需要大量构造reflect.Value和中间变量,对函数参数值进行逐一检查,还需要将调用参数复制到调用函数的参数内存中。
调用完毕后,还需要将返回值转换为reflect.Value,用户还需要从中取出调用值。因此反射调用函数性能不高,不建议大量使用反射。
17, 并发
① 轻量级线程(goroutine)——根据需要随时创建的”线程“
在编写Socket网络程序时候,需要提前准备一个线程池为每一个Socket收发包分配一个线程,开发人员需要在线程数量和CPU数量建立一个对应关系,以保证每个人物能及时的分配到CPU上进行处理,同时避免多个任务频繁的在线程间切换执行效率。
虽然线程池为逻辑编写者提供了线程分配的抽象机制。但是如果面对随时随地可能发生的并发和线程处理需求,线程池就不是非常直观和方便了。能否有一种机制:使用者分配足够多的任务,系统能自动帮助使用者把任务分配到CPU上,让这些任务尽量并发运行,那这种机制就是Go的Goroutine。
goroutine概念类似线程,但goroutine由Go程序运行时的调度和管理。Go程序会智能的将goroutine中的任务合理分配给CPU。
Go程序从main包中的main函数开始,在程序启动时,GO就会为main函数创建一个默认goroutine。
1, 使用普通函数创建goroutine
Go中使用关键字go来为一个函数创建一个goroutine。一个函数可以被创建多个goroutine,一个goroutine必定对应一个函数。
格式:
go 函数名(参数列表)
注意:使用go关键字来创建goroutine时,被调用函数的返回值会被忽略。
2, 示例:
使用go关键字,将running()函数并发执行,每隔一秒打印一次计数器,而main的goroutine则等待用户输入,两个行为可以同步进行。
package main
import (
"fmt"
"time"
)
func running() {
var times int
// 构建一个无限循环
for {
times++
fmt.Println("tick", times)
// 延时1s
time.Sleep(time.Second)
}
}
func main() {
// 并发执行
go running()
// 接受命令行输入,不做任何事情
var input string
fmt.Scanln(&input)
}
代码执行顺序图:
在这个例子中:在Go启动时,运行时(runtime)会默认为main()函数创建一个goroutine。在main()函数的goroutine中执行到go running语句时,归属于running()函数的goroutine被创建,running()函数开始在自己的goroutine中执行。此时main()继续执行,两个goroutine通过Go的调度机制同时运作。
3, 使用匿名函数创建goroutine
go关键字也可以为匿名函数或者闭包启动goroutine
1, 使用匿名函数创建goroutine的格式
使用匿名函数或闭包创建goroutine时,除了将函数定义部分写在go外面之外,还需要加上匿名函数的调用参数,格式如下:
go func(参数列表){
函数体
}(调用参数列表)
2, 示例
package main
import (
"fmt"
"time"
)
func main() {
go func() {
var times int
for {
times++
fmt.Println("tick", times)
time.Sleep(time.Second)
}
}()
var input string
fmt.Scanln(&input)
}
所有goroutine在main()函数结束时会一同结束。
goroutine虽然类似线程,但是并不是线程
3, 调整并发的运行性能(GOMAXPROCS)
在Go程序运行时(runtime)实现了一个小型的任务调度器。这套调度器的工作原理类似于操作系统调度线程,Go程序调度器可以高效的将CPU资源分配给每一个任务。传统逻辑中,开发者需要维护线程池中线程与CPU核心数量的对应关系。同样的,Go也可以通过runtime.GOMAXPROCS()函数做到,格式如下:
runtime.GOMAXPROCS(逻辑CPU数量)
这里的逻辑CPU数量可以有以下数值
- < 1:不修改任何数值
- = 1:单核心执行
>1: 多核并发执行
一般情况,可以使用runtime.NumCPU()查询CPU数量,并使用runtime.GOMAXPROCS()函数进行设置,例如:
runtime.GOMAXPROCS(runtime.NumCPU())
GOMAXPROCS同时也是一个环境变量,在应用程序启动前设置环境变量也可以起到相同的作用
当如果goroutine是非IO操作无法交出控制权时,可以使用runtime.Gosched()让其交出控制权,那就可以让别人有机会运行。
4, Go的goroutine和Python的coroutine
Python或者Go都可以做到将函数或者语句在独立环境中运行,但是他们之间有两点不同:
-
goroutine可能并行执行;但coroutine始终是顺序执行。
狭义的讲,goroutine可能发生在多线程环境下, goroutine无法控制自己获取高优先度支持;coroutine始终发生在单线程,coroutine需要主动交出控制权,宿主才能获得控制权交给其他coroutine。
-
coroutine的运行机制属于协作式任务处理,早期操作系统要求每一个应用必须遵守操作系统的任务处理规则,应用程序在不需要使用CPU时,会主动交出CPU的使用权。如果应用程序长时间霸占CPU,则会出现死机
goroutine属于抢占式任务处理,已经和现有的多线程和多进程任务处理非常类似。应用程序对CPU的控制最终需要操作系统来进行管理,操作系统如果发现一个应用程序长时间使用CPU,那么用户有权终止这个任务
② 通道(channel)——在多个goroutine间通信的管道
单纯的将函数并发执行时没有意义的,函数和函数间需要交换数据才能体现并发执行函数的意义。虽然可以使用共享内存进行数据交换,但是共享内存在不同的Goroutine中容易发生竞争的竞态问题,为了保证数据交换的正确性,必须使用互斥量对内存进行加锁,这种做法一定造成性能问题。
Go提倡使用通信的方式代替共享内存,这里通信的方法就是使用通道(channel)
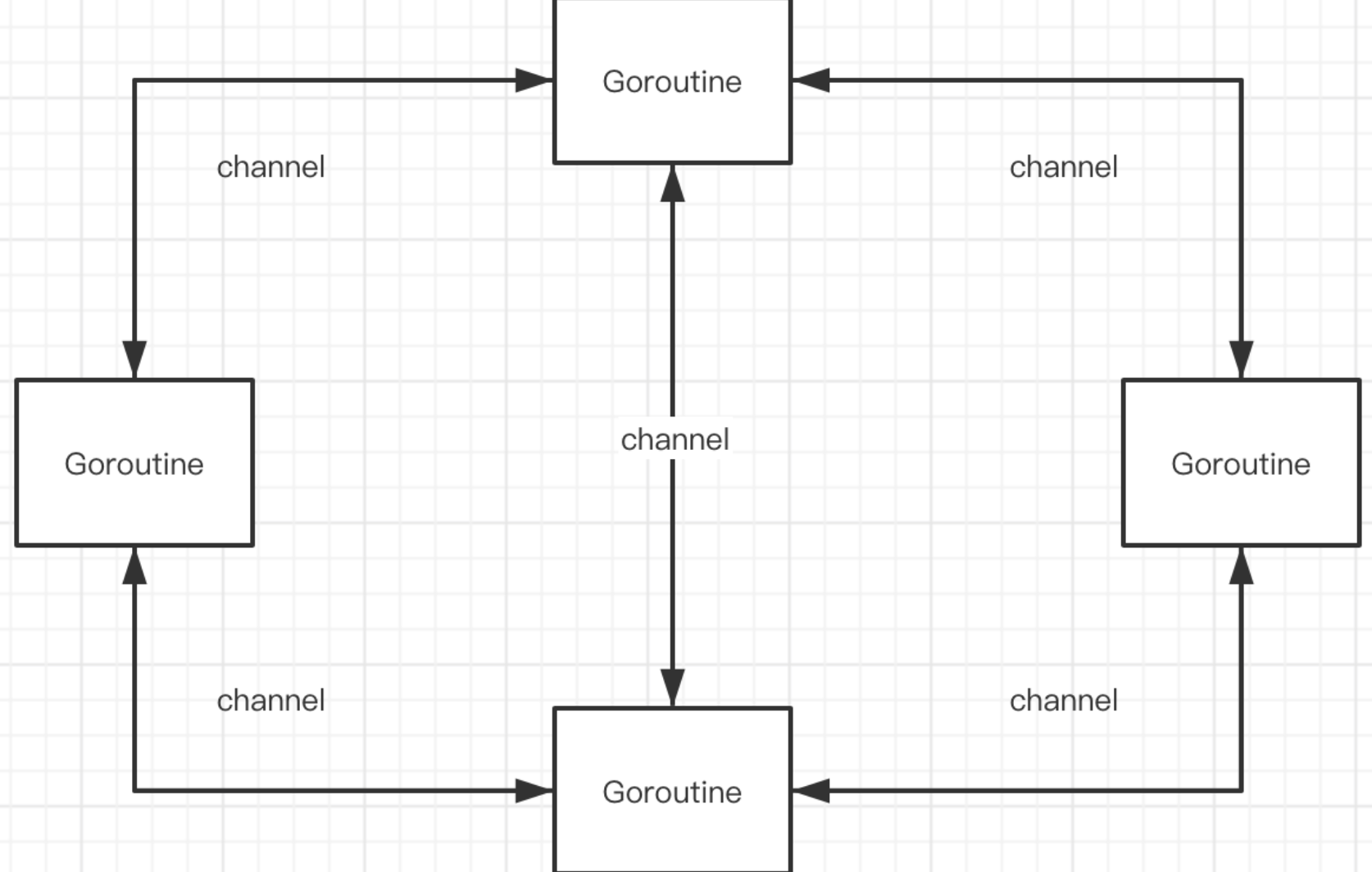
1, 通道的特性
Go语言中的通道(channel)是一种特殊的类型。在任何时候,同时只能有一个Goroutine访问通道进行发送和获取数据。Goroutine间通过通道就可以通信。
通道像是一个传送带或者队列,遵循的是先入后出(First in First out)的规则,保证收发数据的顺序。
2, 声明通道的类型
通道本省需要一个类型进行修饰,就像切片类型需要表示元素类型。通道的元素类型就是在其内部传输的数据类型,声明如下:
var 通道变量 chan 通道类型
- 通道类型:通道内数据类型
- 通道变量:保存通道的变量
chan类型的空值是nil,声明后需要make才能使用。
3, 创建通道
通道是引用类型,需要使用make进行创建,格式如下:
通道实例 := make(chan 数据类型)
- 数据类型: 通道内传输的元素类型
- 通道实例: 通过make创建的通道句柄
例如:
package main
import "fmt"
func main() {
ch1 := make(chan int) // 创建一个整数类型的通道
ch2 := make(chan interface{}) // 创建一个空接口类型的通道,可以存放任意格式
type Equip struct {
}
ch3 := make(chan *Equip) // 创建一个Equip指针类型的通道,只能放*Equip
ch4 := make(chan Equip) // 创建一个Equip指针类型的通道,只能放Equip
fmt.Println(ch1, ch2, ch3, ch4)
}
4, 使用通道发送数据
通道创建之后,就可以使用通道进行发送和接收操作。
通道发送数据的格式
通道的发送使用特殊的操作符<-,将数据通过通道发送的格式为:
通道变量 <- 值
- 通道变量: 通过make创建好的通道实例
- 值: 必须是类型和通道元素类型一致
使用通道发送数据的例子
使用make创建一个通道之后,就可以使用<-像通道发送数据:
package main
func main() {
ch2 := make(chan interface{}) // 创建一个空接口类型的通道,可以存放任意格式
ch2 <- "hello"
ch2 <- 222
}
发送将持续阻塞直到数据被接收
把数据往通道中发送时,如果对方一直都没有接收,那么发送操作将持续阻塞。Go程序运行时会智能的发现一些永远无法发送成功的语句并作出提示,还是上一个代码:运行报错
fatal error: all goroutines are asleep - deadlock!
报错的含义是:运行时发现所有的goroutine包括main的都处于等待goroutine。也就是说所有goroutine中的channel并没有形成发送和接收对应的代码。
5, 使用通道接收数据
通道接收数据同样使用<-操作符,通道接收有如下特性:
-
通道的收发操作在不同的两个goroutine间进行
由于通道的数据在没有接收方处理时,数据发送方会持续阻塞,因此通道的接收必定在另外一个goroutine中进行。
-
接收将持续阻塞直到发送方发送数据
如果接收方接收时,通道中没有发送方发送数据,接收方也会发生阻塞,直到发送方发送数据为止。
-
每次接收一个元素
通道一次只能接收一个数据元素。
通道的数据接收一共有以下4种写法。
阻塞接收数据
阻塞模式接收数据时,将接收变量作为<-操作符的左值,格式如下:
data := <-ch
执行该语句时将会阻塞,直到接收到数据并赋值给data变量
非阻塞接收数据
使用非阻塞方式从通道接收数据时,语句不会发生阻塞,格式如下:
data, ok := <-ch
- data: 表示接收到的数据。未接收到数据时,data为通道类型的零值
- ok:表示是否接收到数据。
非阻塞的通道的接收方法可能造成高的CPU占用,因此使用的非常少。如果需要实现接收超时检测,可以配合select和计时器channel进行。
接收任意数据, 忽略接收的数据
阻塞接收数据后,忽略从通道返回的数据,格式如下:
<-ch
执行该语句时将会发生阻塞,直到接收到数据,但接收到的数据会被忽略。这个方式实际上只是通过通道在goroutine间阻塞收发实现并发同步。
使用通道做并发同步的写法,可以参考下面的例子:
package main
import "fmt"
func main() {
// 构建一个通道
ch := make(chan int)
// 开启一个并发匿名函数
go func() {
fmt.Println("start goroutine")
// 通过通道通知main的goroutine
ch <- 0
fmt.Println("exit goroutine")
}()
fmt.Println("wait goroutine")
// 等待匿名goroutine
<-ch
fmt.Println("all one")
}
wait goroutine
start goroutine
exit goroutine
all one
循环接收
通道的数据接收可以借用 for range 语句进行多个元素的接收操作,格式如下:
for data := range ch {
}
通道ch是可以进行遍历的,遍历的结果就是接收到的数据。数据类型就是通道的数据类型。通过for遍历获得的变量只有一个,即上面例子的data。
package main
import (
"fmt"
"time"
)
func main() {
// 构建一个通道
ch := make(chan int)
// 开启一个并发匿名函数
go func() {
// 从3循环到0
for i := 7; i >= 0; i-- {
// 发送3到0之间的数值
fmt.Println("1111")
ch <- i
// 每次发送完时等待
time.Sleep(time.Second)
}
}()
// 遍历接收通道数据
for data := range ch {
// 打印通道数据
fmt.Println(data)
// 当遇到数据为0时,退出接收循环
if data == 0 {
break
}
}
}
6, 并发打印
上面的例子创建的都是无缓冲通道。使用无缓冲通道向里面装入数据时,装入方将被阻塞,直到另外通道在另一个goroutine中被取出。同样,如果通道中没有放入任何数据,接收方试图从通道中获取数据的时候,同样也是阻塞。发送和接收操作是同步完成的。
package main
import "fmt"
func printer(c chan int) {
// 进行无限循环打印数据
for {
// 从channel中获取一个数据
data := <-c
// 将0视为数据结束
if data == 0 {
break
}
fmt.Println(data)
}
c <- 0
}
func main() {
// 构建一个通道
ch := make(chan int)
// 开启一个并发执行的printer,传入channel
go printer(ch)
for i := 1; i <= 10; i++ {
// 将数据通过channel投送给printer
ch <- i
}
// 通知并发的printer结束循环
ch <- 0
// 等待printer结束
<-ch
}
本例的设计模式就是典型的生产者和消费者。生产者是循环,消费者是printer()函数。整个例子使用了两个goroutine,一个是main(),一个通过printer()函数创建的goroutine。两个goroutine通过ch这个通道进行通信。这个通道有两个功能。
- 数据传送: 发送和接收数据
- 控制指令: 类似于信号量的功能。同步goroutine的操作。功能简单描述为:通知goroutine结束。
7, 单向通道----通道中的单行道
Go的通道可以声明时约束其操作方向,如只发送或者只接收。这种被约束方向的通道被称为单向通道。
单向通道的声明格式
只能发送的通道类型为chan<-,只能接收的通道类型为<-chan,格式如下:
var 通道实例 chan<- 元素类型 只能发送的通道
var 通道实例 <-chan 元素类型 只能接收通道
单向通道的使用例子
示例代码如下:
// 构建一个通道
ch := make(chan int)
// 开启一个并发执行的printer,传入channel
var chSendOnly chan<- int = ch // 声明只能发送的通道类型,并赋值为ch
var chRecvOnly <-chan int = ch // 声明只能接收的通道类型,并赋值为ch
当然使用make创建通道的时候,也可以创建一个只发送或者只读取的通道:
ch := make(<-chan int)
var chReadOnly <-chan int = ch
<-chReadOnly
上面的代码编译可以正常通过,运行也是正确的。但是一个不能填充数据(发送)只能读取的通道是毫无意义的。
因此通常的做法是:创建双向通道channel,然后以单向channel的方式进行函数传递。
package main
import (
"fmt"
"time"
)
func fun1(ch chan string) {
ch <- "HI : 我是周先生,最近在干哈?"
data2 := <-ch
data3 := <-ch
fmt.Println("回应:", data2, data3)
}
// 功能:只有写入数据
func fun2(ch chan<- string) {
// 只能写入
ch <- "两脸懵逼"
}
// 功能:只有读取数据
func fun3(ch <-chan string) {
// 只能读取
data4 := <-ch
fmt.Println("只读状态:", data4)
}
func main() {
ch := make(chan string)
go fun1(ch)
data := <-ch
fmt.Println("聊天开始:", data, "
")
ch <- "我在玩Go"
ch <- "我在玩Python"
go fun2(ch)
go fun3(ch)
time.Sleep(time.Second)
fmt.Println("结束")
}
time包中的单向通道
time包中的计时器会返回一个timer实例,代码如下:
timer := time.NewTimer(time.Second)
timer的Timer类型定义如下:
type Timer struct {
C <-chan Time
r runtimeTimer
}
第二行的C通道类型就是一种只能接收的单向通道。如果此处不进行通道方向的约束,一旦外部向通道发送数据,将会造成其他使用到计时器的地方逻辑产生混乱。
因此单向通道有利于代码接口的严谨性。
8, 带缓冲的通道
在无缓冲通道的基础上,为通道增加一个有限大小的存储空间形成的缓冲通道。带缓冲通道在发送时无需等待接收方接收即可完成发送过程,并且不会发生阻塞,只有当存储空间满时才会发生阻塞。同理,如果带缓冲通道中有数据,接收时也不会发生阻塞,直到通道中没有数据可以读时,通道将再度阻塞。
创建待缓冲通道
如何创建带缓冲通道呢?
通道实例 := make(chan 通道类型, 缓冲大小)
用法和之前一致
package main
import (
"fmt"
)
func main() {
ch := make(chan string, 3)
fmt.Println(len(ch))
ch <- "22"
ch <- "21"
ch <- "23"
fmt.Println(len(ch), cap(ch))
}
可以看到我们创建3个字符串缓冲通道,即便没有goroutine接收,发送者也不会阻塞
阻塞条件
带缓冲通道很多特性都和无缓冲通道类似。无缓冲通道可以看做是长度为0的带缓冲通道。因此根据这个特点,带缓冲通道在以下情况依旧会发生阻塞
- 带缓冲通道被填满时,尝试再次发送数据时将会阻塞。
- 带缓冲通道为空时,尝试接收数据时发生阻塞。
9, 通道的多路复用-----同时处理接收和发送多个通道的数据
多路复用是通信和网络中的一个专业术语。多路复用通常表示在一个信道上传输多路信号或数据流的过程和技术。
在使用通道时,想同时接收多个通道数据时一件困难的事情,通道在接收数据时,如果没有数据接收时将会阻塞。虽然可以采用遍历。
for {
// 尝试接收通道ch
data, ok := <-ch
// 尝试接收通道ch2
data, ok := <-ch2
// 接收后续通道
……
}
这样操作性能会非常差
因此Go中提供了select关键字,可以同时响应多个通道的操作。select的每一个case都会对应一个通道的收发过程,当收发完成时,就会触发case中的响应的语句。多个操作在每次select中挑选一个进行响应。格式如下:
select {
case 操作1:
响应操作
case 操作2:
响应操作2
……
default:
没有操作情况
}
操作1,操作2:包含通道收发语句,请参考9-1
| 操作 | 语句示例 |
|---|---|
| 接收任意数据 | case<-ch: |
| 接收变量 | case d := <-ch: |
| 发送数据 | case ch<-100; |
select 语句的机制有点像switch语句,不同的是,select会随机挑选一个可通信的case来执行,如果所有case都没有数据到达,则执行default,如果没有default语句,select就会阻塞,直到有case接收到数据。
package main
import (
"fmt"
"time"
)
func main() {
ch1 := make(chan int)
ch2 := make(chan int)
go func() {
time.Sleep(time.Second)
ch1 <- 100
}()
go func() {
time.Sleep(time.Second)
ch2 <- 200
}()
select {
case data := <-ch1:
fmt.Println("ch1中读取数据:", data)
case data := <-ch2:
fmt.Println("ch2读取数据:", data)
}
}
可以看到的就是随机挑选的
package main
import (
"fmt"
"time"
)
func main() {
ch1 := make(chan int)
ch2 := make(chan int)
go func() {
time.Sleep(10 * time.Millisecond)
data := <-ch1
fmt.Println("ch1: ", data)
}()
go func() {
time.Sleep(2 * time.Second)
data := <-ch2
fmt.Println("ch2 ", data)
}()
select {
case ch1 <- 100: // 阻塞
close(ch1)
fmt.Println("ch1中写入数据:")
case ch2 <- 200: // 阻塞
close(ch2)
fmt.Println("ch2中写入数据: ")
case <-time.After(2 * time.Millisecond): // 阻塞
fmt.Println("执行延时通道")
//default:
// fmt.Println("default...")
}
time.Sleep(4 * time.Second)
fmt.Printf("over")
}
将default注释掉,select就发生了阻塞,直到有case接收到数据。
使用time包提供的函数After(),从字面意思上看,就是多少时间后,参数是time包中产量。表示指定时间后,通过通道返回当前时间。
③ sync包
sync包提供了互斥锁。除了Once和WaitGroup类型,其余多数适用于低水平的程序,大多数情况下,高水平的同步使用channel通信性能会更好一点。sync包类型的值不应被复制。
前面的一些示例都是使用time.Sleep()函数,通过水面将主Goroutine阻塞至所有Goroutine结束。而更好的做法是使用WaitGroup来实现。
1, 同步等待组
| 方法名 | 功能 |
|---|---|
| (wg *WaitGroup) Add(delta int) | 等待组的计数器+1 |
| (wg *WaitGroup) Done() | 等待组的计数器-1 |
| (wg *WaitGroup) Wait() | 当等待组计数器不等于0时阻塞直到变0 |
同步的sync是串行执行,异步的sync是同时执行。
WaitGroup同步等待组,定义方式如下:
type WaitGroup struct {
noCopy noCopy
// 64-bit value: high 32 bits are counter, low 32 bits are waiter count.
// 64-bit atomic operations require 64-bit alignment, but 32-bit
// compilers do not ensure it. So we allocate 12 bytes and then use
// the aligned 8 bytes in them as state, and the other 4 as storage
// for the sema.
state1 [3]uint32
}
// state returns pointers to the state and sema fields stored within wg.state1.
func(wg *WaitGroup) state()(statep*uint64, semap*uint32)
{
if uintptr(unsafe.Pointer(&wg.state1))%8 == 0 {
return (*uint64)(unsafe.Pointer(&wg.state1)), &wg.state1[2]
} else {
return (*uint64)(unsafe.Pointer(&wg.state1[1])), &wg.state1[0]
}
}
func (wg *WaitGroup) Add(delta int) {
statep, semap := wg.state()
if race.Enabled {
_ = *statep // trigger nil deref early
if delta < 0 {
// Synchronize decrements with Wait.
race.ReleaseMerge(unsafe.Pointer(wg))
}
race.Disable()
defer race.Enable()
}
state := atomic.AddUint64(statep, uint64(delta)<<32)
v := int32(state >> 32)
w := uint32(state)
if race.Enabled && delta > 0 && v == int32(delta) {
// The first increment must be synchronized with Wait.
// Need to model this as a read, because there can be
// several concurrent wg.counter transitions from 0.
race.Read(unsafe.Pointer(semap))
}
if v < 0 {
panic("sync: negative WaitGroup counter")
}
if w != 0 && delta > 0 && v == int32(delta) {
panic("sync: WaitGroup misuse: Add called concurrently with Wait")
}
if v > 0 || w == 0 {
return
}
// This goroutine has set counter to 0 when waiters > 0.
// Now there can't be concurrent mutations of state:
// - Adds must not happen concurrently with Wait,
// - Wait does not increment waiters if it sees counter == 0.
// Still do a cheap sanity check to detect WaitGroup misuse.
if *statep != state {
panic("sync: WaitGroup misuse: Add called concurrently with Wait")
}
// Reset waiters count to 0.
*statep = 0
for ; w != 0; w-- {
runtime_Semrelease(semap, false, 0)
}
}
// Done decrements the WaitGroup counter by one.
func (wg *WaitGroup) Done() {
wg.Add(-1)
}
// Wait blocks until the WaitGroup counter is zero.
func (wg *WaitGroup) Wait() {
statep, semap := wg.state()
if race.Enabled {
_ = *statep // trigger nil deref early
race.Disable()
}
for {
state := atomic.LoadUint64(statep)
v := int32(state >> 32)
w := uint32(state)
if v == 0 {
// Counter is 0, no need to wait.
if race.Enabled {
race.Enable()
race.Acquire(unsafe.Pointer(wg))
}
return
}
// Increment waiters count.
if atomic.CompareAndSwapUint64(statep, state, state+1) {
if race.Enabled && w == 0 {
// Wait must be synchronized with the first Add.
// Need to model this is as a write to race with the read in Add.
// As a consequence, can do the write only for the first waiter,
// otherwise concurrent Waits will race with each other.
race.Write(unsafe.Pointer(semap))
}
runtime_Semacquire(semap)
if *statep != 0 {
panic("sync: WaitGroup is reused before previous Wait has returned")
}
if race.Enabled {
race.Enable()
race.Acquire(unsafe.Pointer(wg))
}
return
}
}
}
WaitGroup,即等待一组Goroutine结束。父Goroutine调用Add()方法来设置应等待Goroutine的数量。
每个被等待的Goroutine在结束时应该调用Done()方法,与此同时,主Do肉体呢可调用Wait()方法阻塞至所有Goroutine结束。
Add()方法想内部计数加上delta,delta可以是负数;如果内部计数变为0, Wait()方法阻塞等待的所有Goroutine都会释放,如果计数小于0,该方法会panic。注意Add()加上正数的调用应该在Wait()之前,否则Wait()可能只会等待很少的Goroutine。通常来说,本方法应该在创建新的Goroutine或者其他应该等待的事件之前调用。
Done()方法减少WaitGroup计数器的值,应在Goroutine的最后执行。等于Add(-1)
而Wait()方法阻塞Goroutine直到WaitGroup计数为0。
package main
import (
"fmt"
"math/rand"
"strings"
"sync"
"time"
)
func printNum(wg *sync.WaitGroup, num int) {
for i := 1; i <= 3; i++ {
// 在每一个Goroutine前面添加多个制表符方便观看打印结果
pre := strings.Repeat(" ", num-1)
fmt.Printf("%s 第%d号子Goroutine, %d
", pre, num, i)
time.Sleep(time.Second)
}
wg.Done()
}
func main() {
var wg sync.WaitGroup
fmt.Printf("%T
", wg) // sync.WaitGroup
fmt.Println(wg) // {} [0, 0, 0]
wg.Add(3)
rand.Seed(time.Now().UnixNano())
go printNum(&wg, 1)
go printNum(&wg, 2)
go printNum(&wg, 3)
wg.Wait() // 进入阻塞状态,当计数为0时解除阻塞
defer fmt.Println("main over")
}
由上述例子可以看出,所有的子Goroutine运行结束后主Goroutine才退出
2, 互斥锁
Mutex是一个互斥锁,可以创建为其他结构体的字段;零值为解锁状态。Mutex类型的锁和Goroutine无关,可以由不同的Goroutine加锁和解锁.
方法有2个
func (m *Mutex) Lock()
func (m *Mutex) Unlock()
- Lock() Lock()方法锁住m,如果m已经加锁,则阻塞直到m解锁
- Unlock() unlock()方法解锁m,如果m未加锁会导致运行错误
package main
import (
"fmt"
"strconv"
"strings"
"sync"
"time"
)
var tickets int = 20
var wg sync.WaitGroup
var mutex sync.Mutex
func saleTickets(name string, wg *sync.WaitGroup) {
defer wg.Done()
for {
// 锁定
mutex.Lock()
if tickets > 0 {
time.Sleep(time.Second)
// 获取窗口的编号
num, _ := strconv.Atoi(name[:1]) // 字符串变整形
pre := strings.Repeat("-----", num) // 将字符串返回num次
fmt.Println(pre, name, tickets)
tickets--
} else {
fmt.Printf("%s 结束售票
", name)
mutex.Unlock()
break
}
// 解锁
mutex.Unlock()
}
}
func main() {
wg.Add(4)
go saleTickets("1号窗口", &wg)
go saleTickets("2号窗口", &wg)
go saleTickets("3号窗口", &wg)
go saleTickets("4号窗口", &wg)
wg.Wait()
defer fmt.Println("车票已售完")
}
-------------------- 4号窗口 20
-------------------- 4号窗口 19
--------------- 3号窗口 18
---------- 2号窗口 17
----- 1号窗口 16
-------------------- 4号窗口 15
--------------- 3号窗口 14
---------- 2号窗口 13
----- 1号窗口 12
-------------------- 4号窗口 11
--------------- 3号窗口 10
---------- 2号窗口 9
----- 1号窗口 8
-------------------- 4号窗口 7
--------------- 3号窗口 6
---------- 2号窗口 5
----- 1号窗口 4
-------------------- 4号窗口 3
--------------- 3号窗口 2
---------- 2号窗口 1
1号窗口 结束售票
4号窗口 结束售票
3号窗口 结束售票
2号窗口 结束售票
车票已售完
3, 读写互斥锁
RWMutex是读写互斥锁,简称读写锁。该锁可以被多个读取者持有或被唯一一个写入者持有。
RWMutex可以创建为其他结构体的字段;零值为解锁状态。RWMutex类型的锁也和Goroutine无关,可以由不同的Goroutine加读取锁/写入锁和解读锁/写入锁。
读写锁的使用中,写操作都是互斥的,读和写是互斥的,读和读不互斥。
该规则可以理解为,可以多个Goroutine同时读取数据,但是只允许一个Goroutine写入数据。
func (rw *RWMutex) Lock() Lock()方法将rw锁定为写入状态,禁止其他Goroutine读取或写入
func (rw *RWMutex) Unlock() Unlock()方法解除rw的写入锁,如果rw未加入写入锁会导致运行时错误
func (rw *RWMutex) RLock() RLock()方法将rw锁定为读状态,禁止其他Goroutine写入,但不禁止读取。
func (rw *RWMutex) RUnlock() RUnlock()方法解除rw的读取锁,如果rw未加读取锁会报错
func (rw *RWMutex) RLocker() Locker Rlocker()方法返回一个读写锁,通过调用rw.Rlock()和rw.RUnlock()实现了Locker接口
package main
import (
"fmt"
"sync"
"time"
)
func main() {
var rwm sync.RWMutex
for i := 1; i <= 3; i++ {
go func(i int) {
fmt.Printf("goroutine %d,尝试读锁定。
", i)
rwm.RLock()
fmt.Printf("goroutine %d,已经读锁定。
", i)
time.Sleep(5 * time.Second)
fmt.Printf("goroutine %d,读解锁。
", i)
rwm.RUnlock()
}(i)
}
time.Sleep(time.Second)
fmt.Println("main..尝试写锁定。")
rwm.Lock()
fmt.Println("main..已经写锁定")
rwm.Unlock()
fmt.Printf("main..写解锁。。")
}
4, 条件变量
条件变量定义方式如下所示。
type Cond struct {
noCopy noCopy
L Locker
notify notifyList
checker copyChecker
}
Cond实现一个条件变量,一个Goroutine集合地,供Goroutine等待或者宣布某件事的发生。
每个Cond实例都有一个相关的锁(一般是*Mutex或RWMutex类型的值),它须在改变条件时或者调用Wait()方法时保持锁定。Cond可以创建为其他结构体字段,Cond在开始使用后不能被复制。条件变量sync.Cond是多个Goroutine等待或接受通知的集合地。
Cond中的方法如下:
func NewCond(l Locker) *Cond 使用锁l创建一个*Cond。Cond条件变量总是要和锁结合使用。
func (c *Cond) Broadcast() Broadcast() 唤醒等待c的Goroutine。调用者在调用本方法时,建议(并非必须)保持c.L的锁定。
func (c *Cond) Signal() Signal()唤醒等待c的一个Goroutine(如果存在。调用者在调用本方法时,建议但并非必须)保持c.L的锁定。
func (c *Cond) Wait() Wait()自行解锁c.L并阻塞当前Goroutine,待线程恢复执行时,Wait()方法会在返回前锁定c.L。和其他系统不同,Wait()除非被Broadcast()或者Signal()唤醒,否则不会主动返回。此方法广播给所有人。
因为Goroutine中Wait()方法是第一个恢复执行的,而此时c.L未加锁,调用者不应假设Wait()恢复时条件已满足,相反,调用者应在循环中等待。
④ 示例:使用通道响应计时器的事件
Go中的time包提供了计时器的封装。由于Go中的通道和goroutine的设计,定时任务可以在goroutine中通过同步的方式完成,也可以通过goroutine中异步回调完成,分为两个方式进行展示。
1, 一段时间后(time.After)
package main
import (
"fmt"
"time"
)
func main() {
// 构建一个通道
exit := make(chan int)
fmt.Println("start")
// 过一秒后,调用匿名函数
time.AfterFunc(time.Second, func() {
fmt.Println("one second after")
// 通知main()的goroutine已经结束
exit <- 0
}) // 调用time.AfterFunc()函数,传入等待的时间和一个回调。回调使用一个匿名函数,在时间到达时,匿名函数会在另外一个goroutine中被调用
<-exit
}
time.AfterFunc()函数是在time.After基础上增加了时间到的时候的回调
package main
import (
"fmt"
"time"
)
func main() {
// 使用After(),返回值<- chan Time,同Timer.C
ch := time.After(5 * time.Second)
fmt.Println(time.Now())
data := <-ch
fmt.Printf("%T
, %d后执行", data, 5)
fmt.Println(data)
}
2020-03-15 21:12:14.39033 +0800 CST m=+0.000082060
time.Time
, 5后执行2020-03-15 21:12:19.391557 +0800 CST m=+5.001328190
2, 定点计时
计时器(Timer)的原理和倒计时闹钟类似,都是给定多少时间后触发。
打点器(Ticker)的原理和钟表类似,钟表每到整点就会触发。这两种方法创建后会返回time.Ticker对象和time.Timer对象
,里面通过一个C成员,类型是只能接收的时间通道(<-chan Time),使用这个通道就可以获得时间触发的通知。
下面代码创建一个打点器,每500毫秒触发一起;创建一个计时器,2秒后触发,只触发一次。
package main
import (
"fmt"
"time"
)
func main() {
// 创建一个打点器,每500毫秒触发一次
ticker := time.NewTicker(time.Millisecond * 500) // 返回*time.Ticker类型变量
// 创建一个计时器,2s后触发
stopper := time.NewTimer(time.Second * 2) // 返回*time.Timer类型变量
// 声明计数变量
var i int
// 不断的检查通道的情况
for {
// 多路复用通道
select {
case <-stopper.C: // 计时器到时了
fmt.Println("stop")
goto StopHere
case <-ticker.C: // 打点器触发了
// 记录触发了多少次
i++
fmt.Println("tick", i)
}
}
// 退出标签,使用goto挑战
StopHere:
fmt.Println("done")
}
3, 关闭通道后继续使用通道
通知是一个引用对象,和map类似。map在没有任何外部引用是,Go程序在运行时(runtime)会自动对内存进行垃圾回收。类似的,通道也可以被垃圾回收,但是通道也可以被主动关闭。
一, 格式
使用close()来关闭一个通道
close(ch)
关闭的通道依然可以被访问,访问被关闭的通道将会发生一些问题
二, 给被关闭通道发送数据将会触发panic
被关闭的通道并不会被置为nil,如果尝试对已经关闭的通道进行发送,将会触发宕机
package main
import "fmt"
func main() {
// 构建一个通道
ch := make(chan int)
close(ch) // 关闭通道
fmt.Printf("ptr:%p cap:%d, len:%d
", ch, cap(ch), len(ch))
// 给关闭的通道发送数据
ch <- 1
}
三, 从已关闭的通道接收数据时不会发生阻塞
从已经关闭的通道接收数据或者正在接收数据时,将会接收到通道类型的零值,然后停止阻塞并返回
package main
import "fmt"
func main() {
// 构建一个通道
ch := make(chan int, 2)
// 给通道放入两个数据
ch <- 0
ch <- 1
// 关闭通道
close(ch) // 带缓冲通道的数据不会被释放,通道也是没有消失
// 遍历缓冲所有数据,且多遍历1个
for i := 0; i <= cap(ch); i++ {
// 从通道中取出数据
v, ok := <-ch
// 打印取出数据的状态
fmt.Println(v, ok)
} // cap()函数可以获取对象的容量,这里获取的是带缓冲通道的容量,多遍历一个元素故意造成通道的越界访问
}
0 true
1 true
0 false
运行结果前两行正确输出带缓冲通道的数据,表明缓冲通道在关闭后依然可以访问内部的数据。
运行结果第三行的”0 false“表示没有获取成功,因此此时通道已经空了。我们发现,在通道关闭后,即便通道没有数据,在获取时也不会发生阻塞,但此时取出数据会失败。
⑤ 同步-----保证并发环境下数据访问的正确性
Go程序可以使用通道进行多个goroutine间的数据交换,但这仅仅是数据同步中的一种方法。
通道内部的实现依然使用了各种锁,因此优雅代码的代价是性能。在某些轻量级的场合,原子访问(atomic包)、互斥锁(sync.Mutex)以及等待组(sync.WaitGroup)能最大程度满足需求。
1, 竞态检测——检测代码在并发环境下可能出现的问题
当多线程并发运行时的程序竞争访问和修改同一块资源时,会发生竞态问题。
生成ID生成器,每一次调用生成器将会生成一个不会重复的顺序序号,使用10个并发生成的序号,观察10个并发后的结果。
package main
import (
"fmt"
"sync/atomic"
)
var (
// 序列号
seq int64 // 序列号生成器中的保存上次序列号的变量
)
func GenID() int64 {
// 尝试原子的增加序列号
atomic.AddInt64(&seq, 1)
// 使用原子操作函数atomic.AddInt64()的返回值作为GenID()函数的返回值,因此会造成一个竞态问题
return seq
}
func main() {
// 生成10个并发序列号
for i := 0; i < 3; i++ {
go GenID() // 忽略GenID()的返回值
}
fmt.Println(GenID()) // 单独调用一次GenID()
}
在运行程序时,为运行函数加入”-race“参数,开启运行时(runtime)对竞态问题的分析,命令如下:
go run -race main.go
根据报错信息,修改代码
package main
import (
"fmt"
"sync/atomic"
)
var (
// 序列号
seq int64 // 序列号生成器中的保存上次序列号的变量
)
func GenID() int64 {
// 尝试原子的增加序列号
return atomic.AddInt64(&seq, 1)
}
func main() {
// 生成10个并发序列号
for i := 0; i < 3; i++ {
go GenID() // 忽略GenID()的返回值
}
fmt.Println(GenID()) // 单独调用一次GenID()
}
再次运行go run -race main.go
便没有发生竞态问题,程序运行正常。
本例只对变量进行增减操作,虽然可以使用互斥锁(sync.Mutex)解决竞态问题,但是对性能消耗较大。在这种情况下,推荐使用原子操作(atomic)进行变量操作。
18, 测试和文档
Go中有一整套的单元测试和性能测试系统,仅需要添加很少的代码就可以快速测试一段需求代码。
性能测试系统就可以给出代码的性能数据,帮助测试者分析性能问题。
① 单元测试和验证代码框架
要开始一个单元测试,需要准备一个go源码文件,在命名文件时需要让文件必须以_test结尾。
单元测试源码文件可以由多个测试用例组成,每一个测试用例函数需要以Test为前缀,例如:
func TestXXX(t *testing.T)
- 测试用例文件不会参与正常编译,不会被包含到可执行文件中
- 测试用例文件使用go test 指令来执行,没有也不需要以main()作为函数入口。所有在以_test结尾的源码内以Test开头的函数会被自动执行。
- 测试用例可以不传入*testing.T参数。
package code
import "testing"
func TestHelloWorld(t *testing.T) {
t.Log("hello_world")
}
单元测试文件(_test.go)里的测试入口必须以Test为开始,参数为testing.T的函数。一个单元测试文件可以有多个测试入口。
使用testing包的T结构提供的Log()方法打印字符串。
1, 单元测试命令行
单元测试用go test命令启动,例如
go test helloworld_test.go
go test -v helloworld_test.go 加上-v会让测试显示出详细的流程。
2, 运行指定单元测试用例
go test指定文件时默认执行文件内所有测试用例。可以使用-run参数选择需要的测试用例单独执行,参考下面代码:
go test -v -run TestA main_test.go
可以看得到TestA和TestAK的测试用例都被执行,原因是-run跟随的测试用例的名称支持正则表达式,使用-run TestA$即可执行TestA测试用例。
go test -v -run TestA$ main_test.go

3, 标记单元测试结果
当需要终止当前测试用例时,可以使用FailNow,参考如下:
func TestFailNow(t *testing.T) {
t.FailNow()
}
func TestFail(t *testing.T) {
fmt.Println("before fail")
t.Fail()
fmt.Println("end fail")
}
=== RUN TestFailNow
--- FAIL: TestFailNow (0.00s)
=== RUN TestFail
before fail
end fail
--- FAIL: TestFail (0.00s)
FAIL
FAIL command-line-arguments 0.581s
FAIL
从运行结果可以看出,在调用Fail方法测试结果标记为失败,但是接下来依旧被打印出来了
4, 单元测试日志
每一个测试用例可能并发执行,使用testing.T提供的日志输出可以保证日志跟随这个测试上下文一起打印输出。testing.T提供了几种日志输出的方法。
| 方法 | 备注 |
|---|---|
| Log | 打印日志,同时结束测试 |
| Logf | 格式化打印日志,同时结束测试 |
| Error | 打印错误日志,同时结束测试 |
| Errorf | 格式化打印错误日志,同时结束测试 |
| Fatal | 打印致命日志,同时结束测试 |
| Fatalf | 格式化打印致命日志,同时结束测试 |
② 基准测试--获得代码内存占用和运行效率的性能数据
基准测试可以测试一段程序的运行性能及耗费CPU的程度。Go中提供了基准测试框架,使用方法类似于单元测试,使用者无需准备高精度的计时器和各种分析工具,基准测试本事可以打印出非常标准的测试报告。
1, 基础测试基本使用
先看一个示例:
package main
import "testing"
func Benchmark_Add(b *testing.B) {
var n int
for i := 0; i < b.N; i++ {
n++
}
}
这段代码使用基准测试框架测试加法性能。不能假设N的范围
go test -v -bench=. main_two_test.go

其中-bench=.表示运行main_two_test.go文件中的所有的基准测试,和单元测试中的-run类似
其中的100000000之前的是基准测试名称,数字表示测试次数,也就是testing.B中提供给程序使用的N。“0.33 ns/op”表示每一个操作耗费多少时间(纳秒)
2, 基准测试原理
基准测试框架对一个测试用例的默认测试时间是1s,开始测试时,当以Benchmark开头的基准测试用例函数返回时还不到1s,那么testing.B中的N值将按1,2,5,10,20,50……递增,同时以递增后的值重新调用基准测试用例函数。
3, 自定义测试时间
通过-benchtime函数可以自定义测试时间,例如:
go test -v -bench=. -benchtime=5s main_two_test.go

4, 测试内存
基准测试可以对一段代码可能存在的内存分配进行统计,下面是一段使用字符串格式化的函数,内部会进行一些分配操作。
package main
import (
"fmt"
"testing"
)
func Benchmark_Alloc(b *testing.B) {
for i := 0; i < b.N; i++ {
fmt.Sprintf("%d", i)
}
}

5, 控制计时器
有些测试需要一定的启动和初始化事件,如果从Benchmark()函数开始计时会很大程度上影响测试结果的准确性。testing.B提供了一系列的方法可以方便的控制计时器,从而让计时器只需要的区间进行测试。提供下面的代码来了解计时器的规则。
package main
import (
"testing"
)
func Benchmark_Add_TimeControl(b *testing.B) {
// 重置计时器
b.ResetTimer()
// 停止计时器
b.StartTimer()
// 开始计时器
b.StartTimer()
var n int
for i := 0; i < b.N; i++ {
n++
}
}
从Benchmark()函数开始,Timer就开始技术。StopTimer()可以停止这个计数过程,做一些耗时操作,通过StartTimer()重新开始计时。RestTimer()可以重置计数器的数据。
计数器内部不仅包含耗时数据,还包括内存分配的数据。