数据的预处理和特征工程
a.数值型特征,如:长度、宽度、像素值等
b.数值范围归一化(feature normalization)可能会提高模型的性能,如:线性回归,kNN,SVM,神经网络等
c.最大最小归一化:将原始数据变换映射到0-1之间,消除量纲的影响

将数据中最大的值转化为1,最小的值转化为0
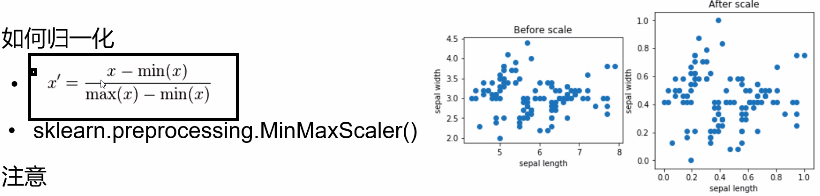
MinMaxScaler是个归一化工具,将数据的取值范围转换成0到1之间。
比如所有数据中的最大值为max,最小值为min,一个数值x通过MinMaxScaler转换之后,取值为(x - min) / (max - min)。
机器学习中,不同属性的取值范围可能存在不同的跨度,比如人类身高的取值可能是0.5到2.5米,而体重取值可能是3到200公斤。当把不同量纲的数值放到一起训练的时候,会存在偏向性,取值范围小的数值会被忽略。比如身高2.5看起来比0.5只大了2,这个值在身高差中已经很大了,但50公斤跟52公斤之间这个2的差别却远不应该受到同样的重视。
于是需要使用Scaler对数值的取值范围进行重新整理。
from sklearn.preprocessing import MinMaxScaler scaler = MinMaxScaler() # 默认归一化是0-1 X_train_scaled = scaler.fit_transform(X_train) # 上面其实做了两件事情①拿到训练集的最大最小值②将数值进行转换 X_test_scaled = scaler.transform(x_test) # 这个地方不能再进行fit,因为在此之前的训练集上已经获取到最大和最小值了,因此这一步只需要进行映射到测试集即可 knn.fit(X_train_scaled, y_train) # 在归一化的训练集上进行调整 # 进行测试 knn.score(X_test_scaled, y_test)
从上述代码可以看出:
先对训练集进行归一化,然后对测试集进行归一化
在测试集上的scaler和训练集上的scaler要保持一致;不要在训练集和测试集分别使用不同的scaler
拟合:
①过拟合:
a.模型对于训练数据拟合程度过当,以致太适应训练数据而非一般情况。
b.在训练数据上表现非常好,但是在测试数据或验证数据上表现很差。
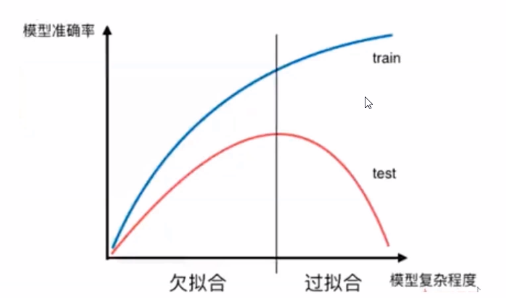
欠拟合与之相反!
造成过拟合的原因:
- 训练数据过少
- 模型过于复杂
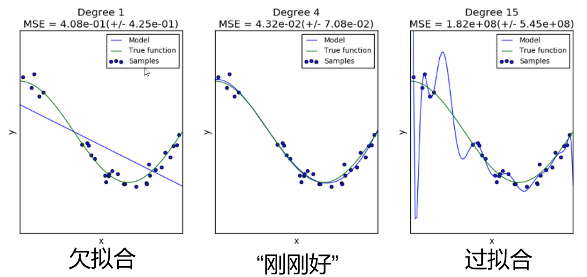
过拟合的解决方法:
收集更多的数据
降低模型复杂度(正则化:控制模型复杂度,模型复杂度越高,越容易过拟合)

模型的调参:
模型参数包括两种
a.模型自身参数,通过样本学习得到的参数。如:逻辑回归及神经网络中的权重及偏置的学习等(不要我们操作)
b.超参数,模型框架的参数,如kNN中的k,SVM中的C。通常由手工设定
如何调参
a.依靠经验
b.依靠实验:k折-交叉验证(cross validation)
如何进行模型调参呢?
按照之前的想法是先分为训练集和测试集;但现在我们需要在训练集上的再次分为训练集和测试集

按照上图的切割方法进行5次交叉验证
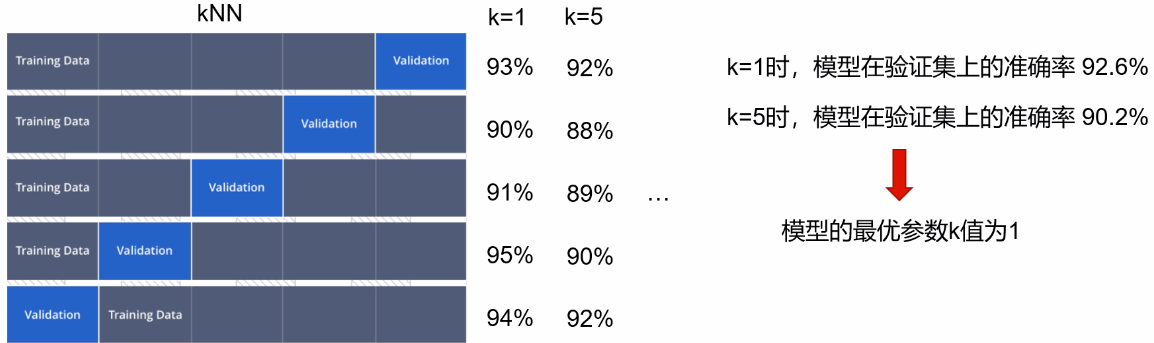
根据数据量的情况定多少折进行交叉验证,在拿到最优参数之后在整个的训练集上再去做一个实验
模型调参的方法:
1,交叉验证
sklearn.model_selection.cross_val_score()
在代码中:
from sklearn.model_selection import cross_val_score # k近邻距离算法 k_list = [1,3,5,7,9] # 首先需要提供调参的范围 for k in k_list: jnn = KNeighborsClassifier(n_neighbors=k) var_scores = cross_val_score(jnn, X_train, y_train,cv=3) # cv表示做一个三折的交叉验证 val_score = var_scores.mean() # 选择最优参数,重新训练模型 best_knn = KNeighborsClassifier(n_neighbors=3) best_knn.fit(X_train, y_train) print(best_knn.score(X_test, y_test)) # 测试模型
2,网格搜索(Grid Search),适用于多个超参数需要调整的情况,单个参数也可以使用
aklearn.model_selection.GridSeachCV()

代码的实现
from sklearn.model_selection import GridSearchCV params = {'n_neighbors': [1.3.5.7.9], 'c': [1,4,7]} knn = KNeighborsClassifier() clf = GridSearchCV(knn, params, cv=3) clf.fit(X_train, y_train) clf.best_params_ # 最优参数 best_model = clf.best_estimator_ # 获取最优模型 # 注意:GridSearchCV默认会使用最优的参数自动重新训练,所以不需要手工操作(refit=True) print(best_model.score(X_test, y_test))
所以使用第二种方式做法更加方便
模型的测试及评价
那模型是不是只有准确率一个评价的参数呢?当然不是了
模型评价指标介绍:
真正例(TP),预测值是1,真实值是1。被正确分类的正例样本。
假正例(FP),预测值是1,但真实值是0
真反例(TN),预测值是0,真实值是0
假反例(FN),预测值是0,但真实值是1
召回率(Recall):TP/(TP + FN)
表示在所有正样本中,被预测正确的个数,即查全率
精确率(Precision): TP/(TP + FP)
表示在所有预测为正样本中,被预测正确的个数,即查准率
注意:Recall和precision只适用于二分类问题
sklearn.metrics中包含常用的评价指标
accuracy_score
precision_score
recall_score
f1_score
用于多分类模型的评价
混淆矩阵(confusion matrix)
scikit-learn方法:sklearn.metrics.confusion_matrix()