面对众多动态网站比如说淘宝等,一般情况下用selenium最好
那么如何集成selenium到scrapy中呢?
因为每一次request的请求都要经过中间件,所以写在中间件中最为合适
from selenium import webdriver from scrapy.http import HtmlResponse class JSPageMiddleware(object): def process_request(self, request, spider): if spider.name == "xinlang": # 这只是一个示例表示爬虫为新浪,当然可以自定义比如正则表达式对于某一种网址来进行过滤 browser = webdriver.Chrome() browser.get(request.url) import time time.sleep(3) print("访问:{0}".format(request.url)) # 如何在这里发送完成之后就不发送给scrapy下载器了呢? return HtmlResponse(url=browser.current_url, body=browser.page_source, encoding="utf-8",request=request) # 一旦遇到HTMLResponse,scrapy就不会向download发送了,而是直接返回给spider了,上面所有值都是必须的
注意别忘了 将中间件写入到settings中!
是不是可以优化的空间了呢?
每一次请求都要打开一次Chrome,这个就很烦了,因为速度比较慢
from selenium import webdriver from scrapy.http import HtmlResponse class JSPageMiddleware(object): def __init__(self): self.browser = webdriver.Chrome super().__init__() def process_request(self, request, spider): if spider.name == "xinlang": # 这只是一个示例表示爬虫为新浪,当然可以自定义比如正则表达式对于某一种网址来进行过滤 self.browser.get(request.url) import time time.sleep(3) print("访问:{0}".format(request.url)) # 如何在这里发送完成之后就不发送给scrapy下载器了呢? return HtmlResponse(url=self.browser.current_url, body=self.browser.page_source, encoding="utf-8", request=request) # 一旦遇到HTMLResponse,scrapy就不会向download发送了,而是直接返回给spider了,上面所有值都是必须的
这样只需要打开一次Chrome了,但是,注意下,这样的话scrapy就不会关闭了,那怎么办?
我们把它放到spider中

那这样的话,中间件中改为
from scrapy.http import HtmlResponse class JSPageMiddleware(object): def process_request(self, request, spider): if spider.name == "xinlang": spider.browser.get(request.url) # 利用spider来进行调用 import time time.sleep(3) print("访问:{0}".format(request.url)) # 如何在这里发送完成之后就不发送给scrapy下载器了呢? return HtmlResponse(url=spider.browser.current_url, body=spider.browser.page_source, encoding="utf-8", request=request)
但是这样还是有问题,我咋知道什么时间关闭?
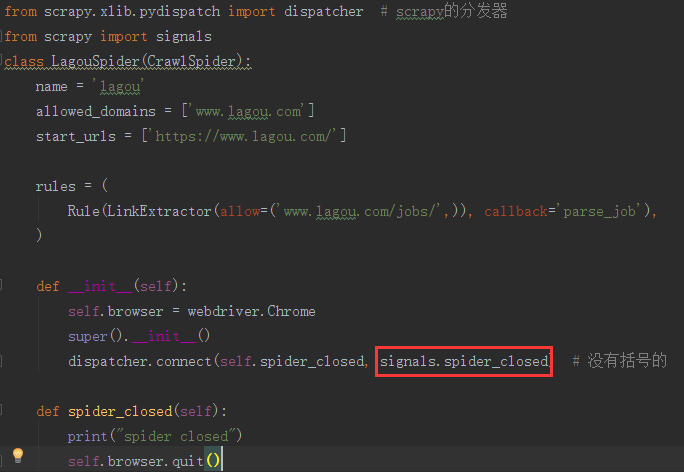
from selenium import webdriver from scrapy.xlib.pydispatch import dispatcher # scrapy的分发器 from scrapy import signals class LagouSpider(CrawlSpider): name = 'lagou' allowed_domains = ['www.lagou.com'] start_urls = ['https://www.lagou.com/'] rules = ( Rule(LinkExtractor(allow=('www.lagou.com/jobs/',)), callback='parse_job'), ) def __init__(self): self.browser = webdriver.Chrome super().__init__() dispatcher.connect(self.spider_closed, signals.spider_closed) # 没有括号的 def spider_closed(self): print("spider closed") self.browser.quit()
是不是和django的用法非常一致?
但是异步处理的时候,则么办,现在是一个同步的请求!
那么重写download
git 搜索scrapy download一搜便知