1. DISTINCT 多列去重
1.1 select DISTINCT a,b 实际含义是?
正确:排除 (a列重复且b列重复)的记录
错误:排除 a b两列 值合并后 重复的记录。
举例1:
去重前,10个记录
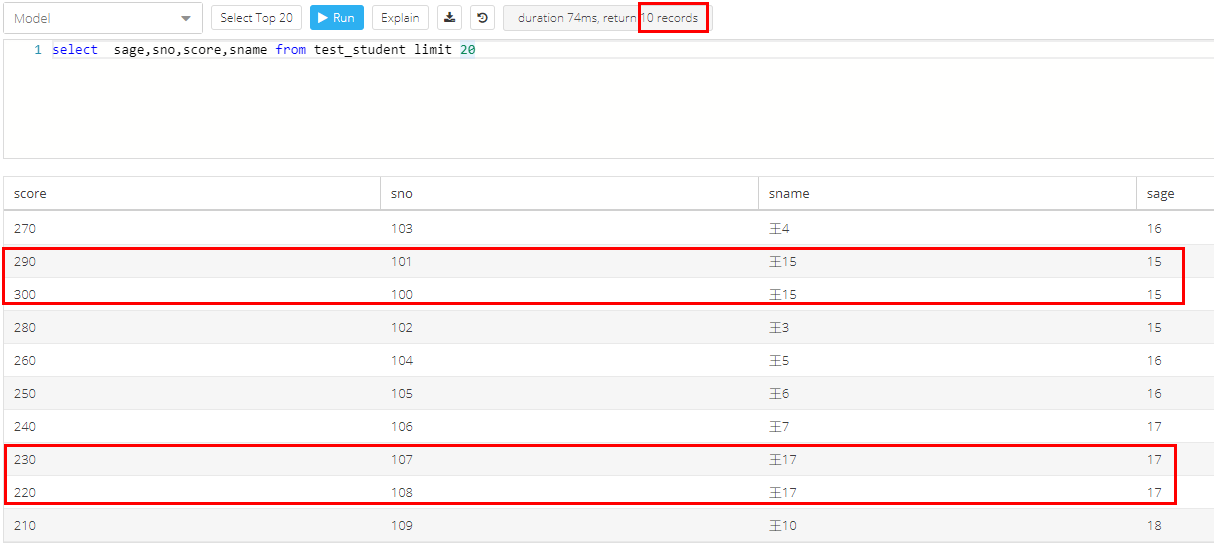
按照distinct a,b 去重,原来10个记录,现在查到了8个。
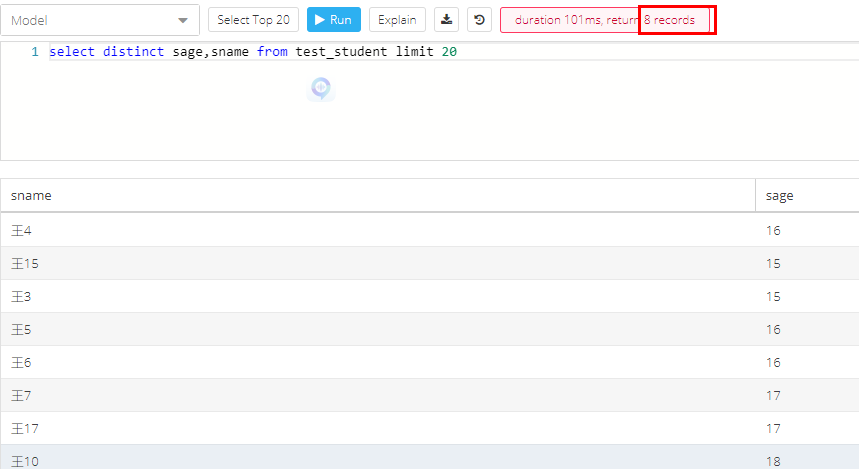
1.2 展示多列,但是只选择只去重一列的实现方法:使用group by
select a, b from tablename group by a;
举例1:
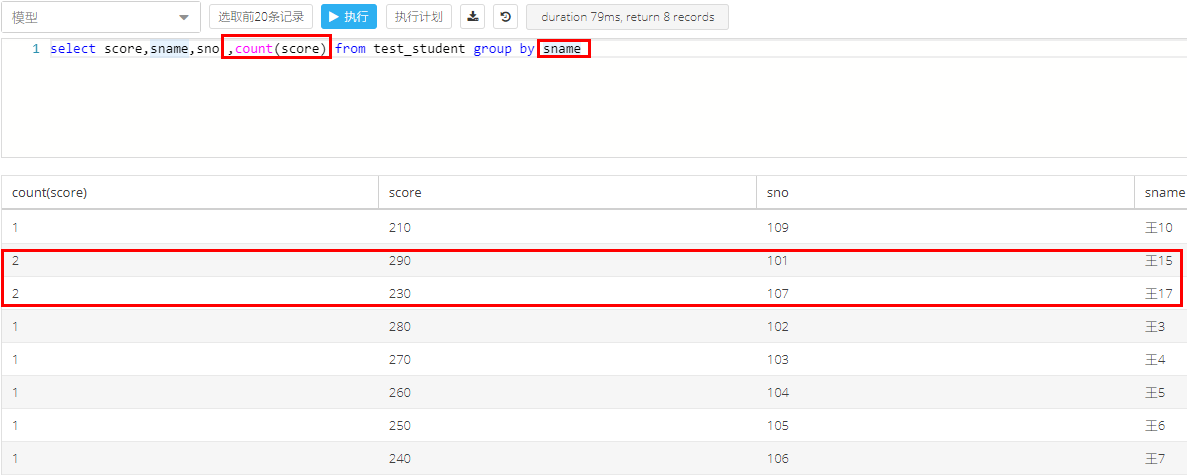
原纪录中重复的 王15 和王17,因为group by sname ,排除掉了,展示的时候,结果只选中和展示1个王15和1个王17
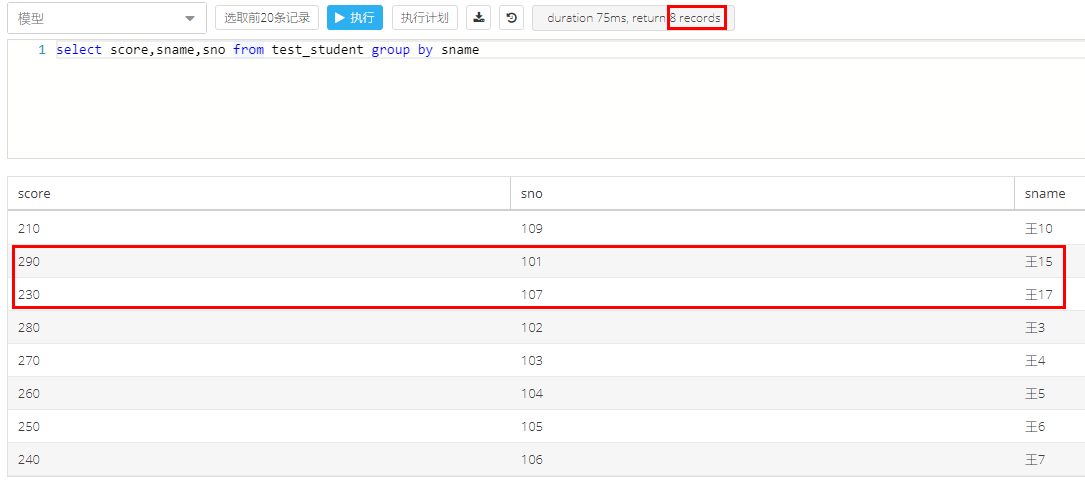
结论:无论是distinct还是group by,在单列去重的时候,都是只保留多个重复记录中的的一个记录,但是其他列可能数据实际上可能一样也可能不一样
1.3 DISTINCT关键字位置必须放在SQL语句的select之后,第一个列名之前。
1.4 与count()函数结合用例:
select count(distinct name) from A;(待确认mysql是否支持语句),
2. ORDER BY 多列排序
2.1 select * from tableA order by columnA [asc],columnB [asc]; //默认升序,先按照A列排序后,在A列排序的基础上按照B列排序。
存疑:当A列存在/不存在相同项,B列排序会影响原有顺序吗?
举例1:A(sage)列存在相同列

举例2:A列(score)不存在相同项举例
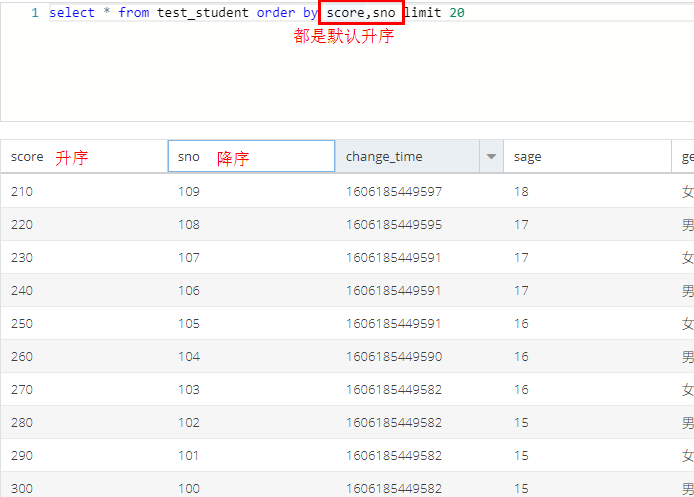
结论:
1.多列排序应用场景:在A列排序后,多个记录中A列值相同,且B列存在可进一步排序的值。若A列所有记录都是唯一的则没有必要使用多列排序。
2.ORDER BY 排列时,不写明ASC DESC的时候,默认是ASC。
3. GROUP BY
3.1 group by 函数结合count()函数,可以统计各个分组的记录数
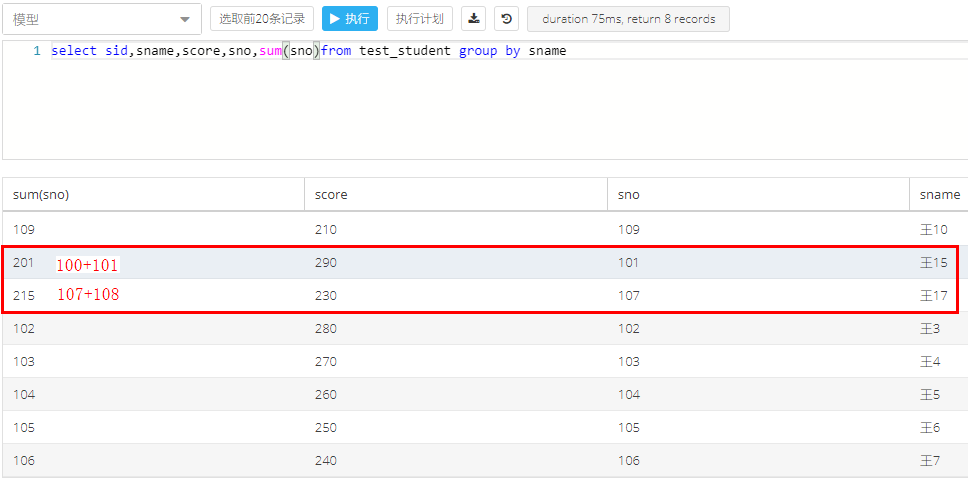
3.2 group by 函数结合sum(a)函数,可以分别统计各个分组的a列数值之和
4. HAVING 和 WHERE 区别
1. 使用位置不一样: where 是在GROUP BY前 ,HAVING 是在 GROUP BY后 ORDER BY前
2. 作用对象不一样:对 记录 进条件过滤, 对 分组 进行条件过滤
3. 与聚合函数一起使用:where不能和聚合函数一起使用,如...where sum(age)>50..是错误的,having一般结合聚合函数使用,如...having count(id)>10...
5. on 和 WHERE 区别
1. 生效阶段不同:on是在生成中间表(临时表)时生效,where是在生成临时表后,对临时表进行再次过滤。—重要,可以结合如下 例一,例二 理解
2. 对于inner join ,on 和 where 的结果是一样的,但是对于外链接(left/right/full),是不一样的。
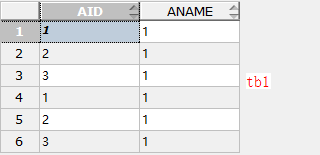
例一:
建表tb1,tb2如下:

执行1:SELECT a.AID,a.ANAME ,b.BID,b.BNAME FROM tb1 a LEFT JOIN tb2 b ON a.AID=b.BID;
执行2:SELECT a.AID,a.ANAME ,b.BID,b.BNAME FROM tb1 a LEFT JOIN tb2 b ON a.AID=b.BID AND b.BNAME='2';
执行3:SELECT a.AID,a.ANAME ,b.BID,b.BNAME FROM tb1 a LEFT JOIN tb2 b ON a.AID=b.BID WHERE b.BNAME='2';
执行4:SELECT a.AID,a.ANAME ,b.BID,b.BNAME FROM tb1 a INNER JOIN tb2 b ON a.AID=b.BID AND b.BNAME='2';
执行5:SELECT a.AID,a.ANAME ,b.BID,b.BNAME FROM tb1 a INNER JOIN tb2 b WHERE a.AID=b.BID AND b.BNAME='2';
执行6:SELECT a.AID,a.ANAME ,b.BID,b.BNAME FROM tb1 a INNER JOIN tb2 b ON a.AID=b.BID WHERE b.BNAME='2';
结果1: 结果2: 结果3:
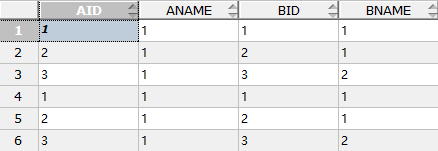
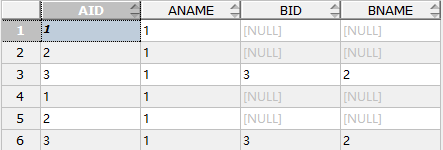

结果4: 结果5: 执行6:



例二:
假设建两张表如下:
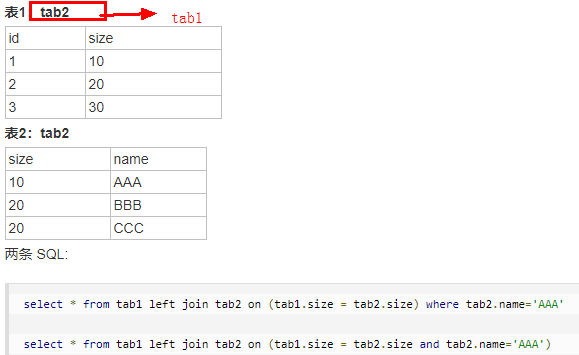

6. inner join 和 left join 区别
参考《MySQL-实体映射关系和连接查询》随笔