1.flume安装
将压缩包减压到当前目录 tar -zxf apache-flume-1.8.0-bin.tar.gz
配置环境变量 编辑当前目录中的 .bashrc 文件(这影响当前用户的环境变量文件若修改全局的可以修改其他文件)
vi ~/.bashrc
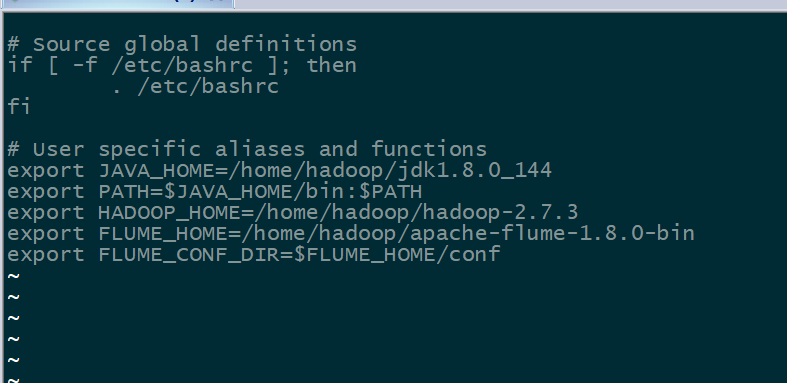
添加环境变量
export FLUME_HOME=/home/hadoop/apache-flume-1.8.0-bin
export FLUME_CONF_DIR=$FLUME_HOME/conf
使文件生效
source ~/.bashrc
进入conf文件
cd /home/hadoop/apache-flume-1.8.0-bin/conf
复制文件 cp flume-env.sh.template flume-env.sh
vi flume-env.sh
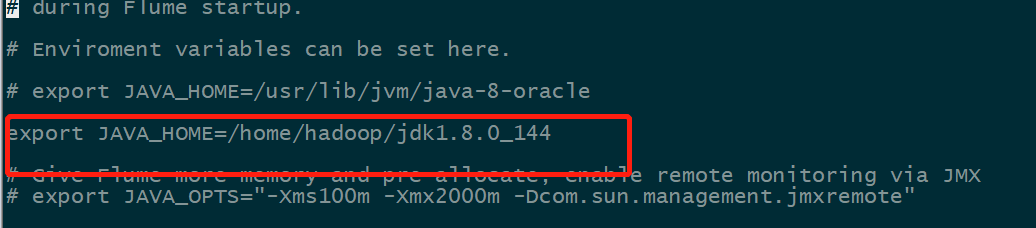
添加jdk
export JAVA_HOME=/home/hadoop/jdk1.8.0_144
安装完成
2.配置flume文件说明
1、
#定义agent名称,source,channel,sink的名称
#a1就是我们给agent起的名字,我们知道有多个agent,那么我们就是通过这个来进行区别
#我们知道agent包含了三个重要的组件,有source,channel,sink
#那么我们也给这个三个组件分别取名字
a1.sources = r1
a1.channels = c1
a1.sinks = k1
#定义具体的source内容
#我这个source具体是什么类型的,读取什么样的数据
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /home/hadoop/bigdata/logs
#定义具体的channel信息
#我们source定义好了,就要来定义我们的channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000
a1.channels.c1.transactionCapacity = 100
#定义具体的sink信息
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://192.168.56.2:9000/flume/event
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.fileType = DataStream
#不按照条数生成文件
a1.sinks.k1.hdfs.rollCount = 0
#HDFS上的文件达到128M生成一个文件
a1.sinks.k1.hdfs.rollSize = 134217728
#HDFS上的文件达到60秒生成一个文件
a1.sinks.hdfs.rollInterval = 60
#定义拦截器,其实可以来拦截一些没用的数据,这里是为了让消息添加时间戳,这样我就知道这个数据是什么时候发送过来的
#那么我们可以将这个数据动态的写入到某个目录下面,比如1月1号的数据我写到1月1号这个目录,2号写入对应的2号目录
#这样更方便查找和查看
a1.sources.r1.interceptors =
#最后来组装我们之前定义的channel和sink
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
2、
#定义agent名称,source,channel,sink的名称
#a1就是我们给agent起的名字,我们知道有多个agent,那么我们就是通过这个来进行区别
#我们知道agent包含了三个重要的组件,有source,channel,sink
#那么我们也给这个三个组件分别取名字
a2.sources = r1
a2.channels = c1
a2.sinks = k1
#定义具体的source内容
#这里是执行命令以及下面对应的具体命令
#这个命令执行后的数据返回给这个source
a2.sources.r1.type = exec
a2.sources.r1.command = tail -F /home/hadoop/bigdata/logs/log
#定义具体的channel信息
#我们source定义好了,就要来定义我们的channel
a2.channels.c1.type = memory
a2.channels.c1.capacity = 10000
a2.channels.c1.transactionCapacity = 100
#定义具体的sink信息
#这个logger sink,就是将信息直接打印到控制台
#就是打印日志
a2.sinks.k1.type = logger
#最后来组装我们之前定义的channel和sink
a2.sources.r1.channels = c1
a2.sinks.k1.channel = c1