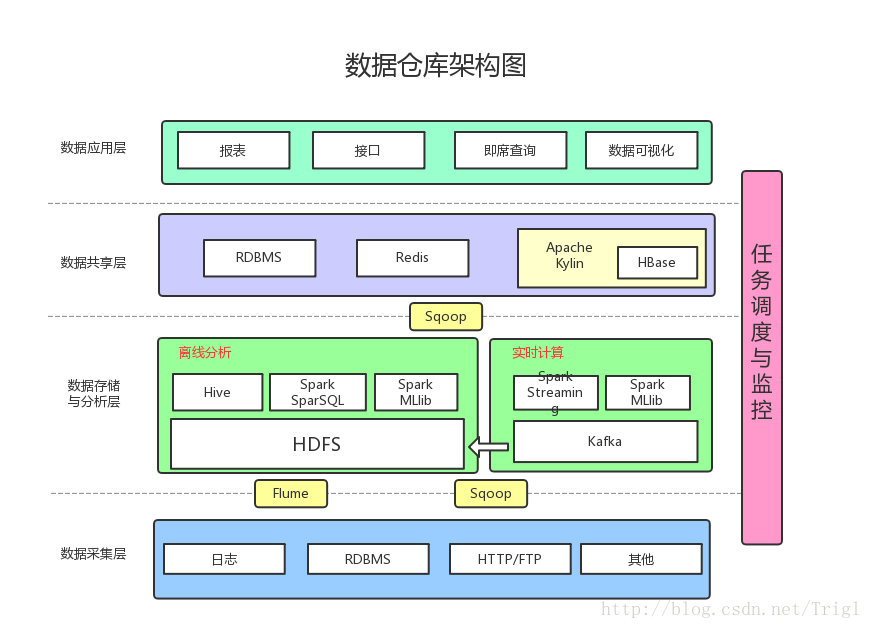
数据采集
数据采集层的任务就是把数据从各种数据源中采集和存储到数据存储上,期间有可能会做一些ETL操作。
数据源种类可以有多种:
日志:所占份额最大,存储在备份服务器上
业务数据库(RDBMS):如Mysql、Oracle
来自HTTP/FTP的数据:合作伙伴提供的接口
其他数据源:如Excel等需要手工录入的数据
。。。
数据存储于分析
Flume收集数据存储日志。
Sqoop 是一个在结构化数据和Hadoop之间进行批量数据迁移的工具,采用Sqoop将RDBMS以及NoSQL中的数据同步到HDFS上。
HDFS是大数据环境下数据仓库/数据平台最完美的数据存储解决方案。
Hive 用于离线数据分析与计算,针对实时性要求不高的部分。
MapReduce 用于分析与计算(使用JAVA),
Spark性能比MapReduce好很多,同时使用SparkSQL操作Hive。
数据共享
前面使用Hive、MR、Spark、SparkSQL分析和计算的结果,还是在HDFS上,但大多业务和应用不可能直接从HDFS上获取数据,那么就需要一个数据共享的地方,使得各业务和产品能方便的获取数据。
这里的数据共享,其实指的是前面数据分析与计算后的结果存放的地方,其实就是关系型数据库和NOSQL数据库。
Kafka防止数据丢失
实时计算:Spark Streaming,实时计算结果大多保存在Redis中
机器学习:使用了Spark MLlib提供的机器学习算法
多维分析OLAP:使用Kylin作为OLAP引擎
数据应用
报表:报表所使用的数据,一般也是已经统计汇总好的,存放于数据共享层。
接口:接口的数据都是直接查询数据共享层即可得到。
即席查询:即席查询通常是现有的报表和数据共享层的数据并不能满足需求,需要从数据存储层直接查询。一般都是通过直接操作SQL得到。
数据可视化:提供可视化前端页面,方便运营等非开发人员直接查询