最近有一个需求,需要爬取东方财富网的机构调研数据.数据所在的网页地址为: 机构调研
网页如下所示:
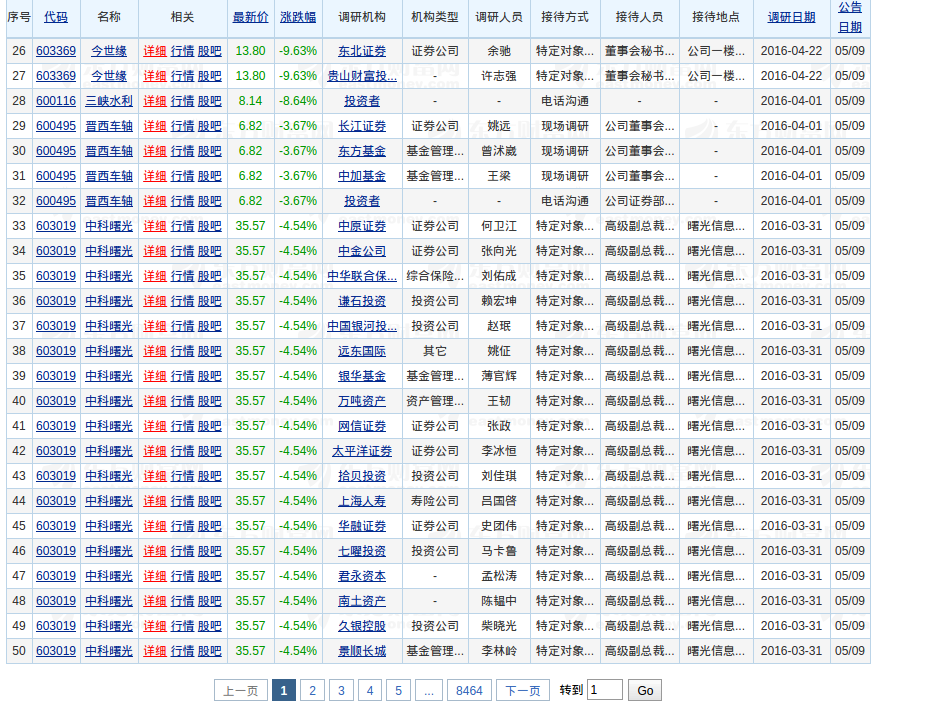
可见数据共有8464页,此处不能直接使用scrapy爬虫进行爬取,因为点击下一页时,浏览器只是发起了javascript网络访问,然后将服务器返回的数据插入网页,无法通过网址直接获取对应页的的页面数据.
通过chrome的开发者工具,我们可以看到点击下一页按钮背后发起的网页访问:
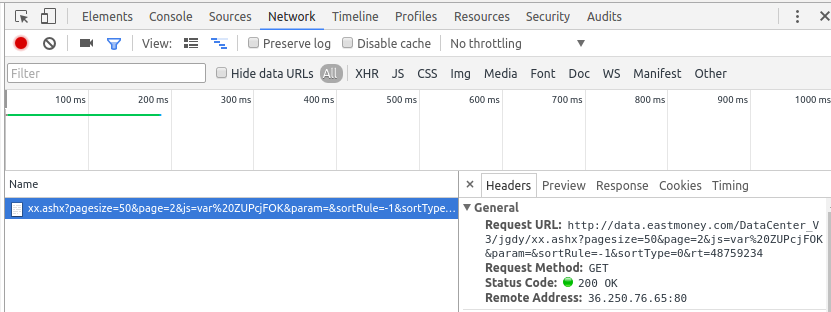
在点击下一页时,浏览器向地址发起了访问.我们分析一下这个地址的结构:
http://data.eastmoney.com/DataCenter_V3/jgdy/xx.ashx?pagesize=50&page=2&js=var%20ZUPcjFOK¶m=&sortRule=-1&sortType=0&rt=48759234
上述地址中的&page= 之后指定的是需要获取第几个页面的数据.所以我们可以通过修改&page=后面的数字来访问不同页面对应的数据.
现在看一下这个数据的结构:

可见这个数据是一个字符串,根据第一个出现的等于号对该字符串进行切分,切分得到的后半段是一个json字符串,里面存储了我们想要获取的数据. json数据中的字段pages的值就是页面的总数.根据这一特性我们可以写出下述函数获取页面的总数:
# 获取页数 def get_pages_count(): url = '''http://data.eastmoney.com/DataCenter_V3/jgdy/xx.ashx?pagesize=50&page=%d''' % 1 url += "&js=var%20ngDoXCbV¶m=&sortRule=-1&sortType=0&rt=48753724" wp = urllib.urlopen(url) data = wp.read().decode("gbk") start_pos = data.index('=') json_data = data[start_pos + 1:] dict = json.loads(json_data) pages =dict['pages'] return pages
在给定页数范围的情况下可以获取数据地址列表,如下所示:
# 获取链接列表 def get_url_list(start,end): url_list=[] while(start<=end): url = '''http://data.eastmoney.com/DataCenter_V3/jgdy/xx.ashx?pagesize=50&page=%d''' %start url += "&js=var%20ngDoXCbV¶m=&sortRule=-1&sortType=0&rt=48753724" url_list.append(url) start+=1 return url_list
为了保存这些数据,我使用sqlalchemy中的orm模型来表示数据模型,数据模型定义如下:
# 此处需要设置charset,否则中文会乱码 engine =create_engine('mysql+mysqldb://user:passwd@ip:port/db_name?charset=utf8') Base =declarative_base() class jigoudiaoyan(Base): __tablename__ = "jigoudiaoyan" # 自增的主键 id =Column(Integer,primary_key=True) # 调研日期 StartDate = Column(Date,nullable=True) # 股票名称 SName =Column(VARCHAR(255),nullable=True) # 结束日期 一般为空 EndDate=Column(Date,nullable=True) # 接待方式 Description =Column(VARCHAR(255),nullable=True) # 公司全称 CompanyName =Column(VARCHAR(255),nullable=True) # 结构名称 OrgName=Column(VARCHAR(255),nullable=True) # 公司代码 CompanyCode=Column(VARCHAR(255),nullable=True) # 接待人员 Licostaff=Column(VARCHAR(800),nullable=True) # 一般为空 意义不清 OrgSum=Column(VARCHAR(255),nullable=True) # 涨跌幅 ChangePercent=Column(Float,nullable=True) # 公告日期 NoticeDate=Column(Date,nullable=True) # 接待地点 Place=Column(VARCHAR(255),nullable=True) # 股票代码 SCode=Column(VARCHAR(255),nullable=True) # 结构代码 OrgCode=Column(VARCHAR(255),nullable=True) # 调研人员 Personnel=Column(VARCHAR(255),nullable=True) # 最新价 Close=Column(Float,nullable=True) #机构类型 OrgtypeName=Column(VARCHAR(255),nullable=True) # 机构类型代码 Orgtype=Column(VARCHAR(255),nullable=True) # 主要内容,一般为空 意义不清 Maincontent=Column(VARCHAR(255),nullable=True) Session =sessionmaker(bind=engine) session =Session() # 创建表 Base.metadata.create_all(engine) # 获取链接列表
在上述基础上,我们就可以定义下属函数用于抓取链接的内容,并将其解析之后存入数据库,如下所示:
#记录并保存数据 def save_json_data(user_agent_list): pages =get_pages_count()
len_user_agent=len(user_agent_list) url_list =get_url_list(1,pages) count=0 for url in url_list: request = urllib2.Request(url) request.add_header('Referer','http://data.eastmoney.com/jgdy/') # 随机从user_agent池中取user pos =random.randint(0,len_user_agent-1) request.add_header('User-Agent', user_agent_list[pos]) reader = urllib2.urlopen(request) data=reader.read() # 自动判断编码方式并进行解码 encoding = chardet.detect(data)['encoding'] # 忽略不能解码的字段 data = data.decode(encoding,'ignore') start_pos = data.index('=') json_data = data[start_pos + 1:] dict = json.loads(json_data) list_data = dict['data'] count+=1 for item in list_data: one = jigoudiaoyan() StartDate =item['StartDate'].encode("utf8") if(StartDate ==""): StartDate = None else: StartDate = datetime.datetime.strptime(StartDate,"%Y-%m-%d").date() SName=item['SName'].encode("utf8") if(SName ==""): SName =None EndDate = item["EndDate"].encode("utf8") if(EndDate==""): EndDate=None else: EndDate=datetime.datetime.strptime(EndDate,"%Y-%m-%d").date() Description=item['Description'].encode("utf8") if(Description ==""): Description= None CompanyName=item['CompanyName'].encode("utf8") if(CompanyName==""): CompanyName=None OrgName=item['OrgName'].encode("utf8") if(OrgName ==""): OrgName=None CompanyCode=item['CompanyCode'].encode("utf8") if(CompanyCode==""): CompanyCode=None Licostaff=item['Licostaff'].encode("utf8") if(Licostaff ==""): Licostaff=None OrgSum = item['OrgSum'].encode("utf8") if(OrgSum ==""): OrgSum=None ChangePercent=item['ChangePercent'].encode("utf8") if(ChangePercent ==""): ChangePercent=None else: ChangePercent=float(ChangePercent) NoticeDate=item['NoticeDate'].encode("utf8") if(NoticeDate==""): NoticeDate=None else: NoticeDate=datetime.datetime.strptime(NoticeDate,"%Y-%m-%d").date() Place=item['Place'].encode("utf8") if(Place==""): Place=None SCode=item["SCode"].encode("utf8") if(SCode==""): SCode=None OrgCode=item['OrgCode'].encode("utf8") if(OrgCode==""): OrgCode=None Personnel=item['Personnel'].encode('utf8') if(Personnel==""): Personnel=None Close=item['Close'].encode("utf8") if(Close==""): Close=None else: Close =float(Close) OrgtypeName =item['OrgtypeName'].encode("utf8") if(OrgtypeName==""): OrgtypeName=None Orgtype=item['Orgtype'].encode("utf8") if(Orgtype==""): Orgtype=None Maincontent=item['Maincontent'].encode("utf8") if(Maincontent==""): Maincontent=None one.StartDate=StartDate one.SName=SName one.EndDate=EndDate one.Description=Description one.CompanyName=CompanyName one.OrgName=OrgName one.CompanyCode=CompanyCode one.Licostaff=Licostaff one.OrgSum=OrgSum one.ChangePercent=ChangePercent one.NoticeDate=NoticeDate one.Place=Place one.SCode=SCode one.OrgCode=OrgCode one.Personnel=Personnel one.Close=Close one.OrgtypeName=OrgtypeName one.Orgtype=Orgtype one.Maincontent=Maincontent session.add(one) session.commit() print 'percent:' ,count*1.0/pages,"complete!,now ",count # delay 1s time.sleep(1)
为了加快抓取速度,我设置了user_agent池,每次访问设置user_agent时随机从池中取一条作为这次访问的user_agent.对应列表user_agent_list ,定义如下:
# user_agent 池 user_agent_list=[] user_agent_list.append("Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 ") user_agent_list.append("Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50") user_agent_list.append("Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1") user_agent_list.append("Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11") user_agent_list.append("Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 ") user_agent_list.append("Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36")
请注意,为了自动识别网页编码并解码,我使用了chardet模块识别网页的编码.为了应对极端情况下解码失败的问题,我在解码时设置跳过那些不能正确解码的字符串.相关代码截取如下:
encoding = chardet.detect(data)['encoding'] # 忽略不能解码的字段 data = data.decode(encoding,'ignore')
补充:
网址中最后一个字段代码时间戳,用于确定获取哪一个时刻的最新价(maybe for ban crawler?),在查看网页源代码之后,我确定时间戳的生成代码如下,给有需要的人(我发现东方财富网的这个字段都是这么生成的):
# 获取当前的时间戳 def get_timstamp(): timestamp =int(int(time.time())/30) return str(timestamp)