1.解压安装文件,设置环境变量
这里我们使用的安装文件是已经编译好的spark,需要搭配hadoop-2.6.0使用。下载链接是:http://pan.baidu.com/s/1gdnW5mr
解压安装文件至/cloud目录
设置spark的环境变量:
export SPARK_HOME=/cloud/spark-1.5.1
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
2.设置相关配置文件
(1)spark-env.sh
cd /cloud/spark-1.5.1/conf
cp spark-env.sh.template spark-env.sh
vi spark-env.sh
在该文件中加入以下start-master.sh内容:
export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk.x86_64
export SCALA_HOME=/cloud/scala-2.10.6
export HADOOP_CONF_DIR=/cloud/hadoop-2.6.0/etc/hadoop
(2)slaves
cp slaves.template slaves
slaves文件指明worker在哪些主机上运行
在该文件中添加以下内容
master
slave1
slave2
即worker将在master,slave1,slave2上运行。
(3)因为storm web-ui已经占用了8080端口,需要更改spark端口,这里我们更改为8888
cd ../sbin
vi start-master.sh
修改后的端口号如下:
if [ "$SPARK_MASTER_WEBUI_PORT" = "" ]; then
SPARK_MASTER_WEBUI_PORT=8888
fi
3.分发安装文件
cd /cloud
scp -r spark-1.5.1/ root@slave1:/cloud
scp -r spark-1.5.1/ root@slave2:/cloud
4.启动spark集群(注意要先启动hadoop集群)
cd /cloud/spark-1.5.1/sbin
./start-all.sh
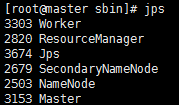
master 进程情况:
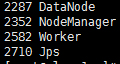
slave1和slave2进程情况:
5.测试集群工作是否正常
(1)访问spark master web_ui

(2)运行spark版WordCount
①首先将spark的介绍文件提交到hdfs
cd /cloud/spark-1.5.1
hdfs dfs -put README.md
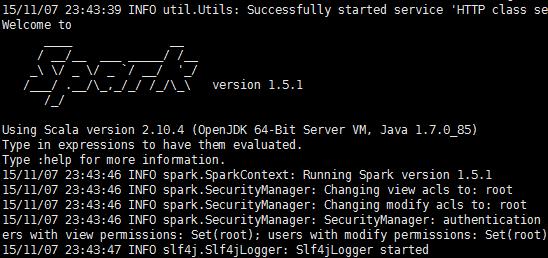
②启动spark-shell
cd bin
./spark-shell
②统计hdfs中README.md文件中文本行中包含单词Spark的数目
val textCount = sc.textFile("README.md").filter(line => line.contains("Spark")).count()

可见,spark已经安装成功,运行无误。