1.MediaPipe为何提出
MediaPipe为移动、桌面/云、web和物联网设备构建世界级ML解决方案和应用程序。整个MediaPipe有以下四个特点:
- 端到端加速:内置的快速ML推理和处理框架甚至可以在普通硬件上加速
- 构建一次,部署在任何地方:统一的解决方案工作在Android, iOS,桌面/云,网络和物联网
- 现成的解决方案:尖端的ML解决方案,展示了框架的全部功能
- 免费和开放源码:Apache 2.0下的框架和解决方案,完全可扩展和可定制
2.MediaPipe框架的组件
2.1 计算单元(Calculator)
每个计算单元都是图的一个节点,下文主要描述怎样构建新的计算单元,怎样初始化计算单元,怎样执行计算单元的输入/输出流,时间戳和选项。一个计算单元可能不接受或接受多个输入流,输出零个或者多个输出流。
(1) 计算单元基类
通过定义CalculatorBase类的新子类、实现许多方法并向Mediapipe注册新子类来创建计算单元。一个新的计算单元至少必须实现以下四个方法。
-
GetContract()
计算单元可以在GetContract()中指定输入和输出的预期类型。当图形(Graph)初始化时,框架调用一个静态方法来验证连接的输入和输出数据包的类型是否与此规范中的信息匹配。 -
Open()
图启动后,框架调用Open()。输入端数据包在此刻处于准备状态。Open()解释节点配置操作,并准备计算单元的每个图运行状态。这个函数也可以将数据包写到计算单元的输出中。Open()期间出现的错误可能会终止图形运行。 -
Process()
对于有输入的计算单元,只要至少有一个输入流有可用的包,框架就会重复调用Process()。框架默认情况下保证所有输入都具有相同的时间戳。当启用并行执行时,可以同时调用多个Process()调用。如果Process()期间发生错误,框架调用Close(),图(Graph)运行终止。 -
Close
在所有对Process()的调用结束后或当所有输入流关闭时,框架调用close()。如果调用了Open()并成功了,则始终调用此函数,即使由于错误而终止了图形运行,也将始终调用此函数。在Close()期间,任何输入流都没有可用的输入,但它仍然可以访问输入端包,因此可以写入输出。在Close()返回后,计算节点应该被认为是死节点。图形完成运行后,计算单元对象将被销毁。
下面是来自CalculatorBase.h的代码片段。
class CalculatorBase {
public:
...
// The subclasses of CalculatorBase must implement GetContract.
// ...
static ::MediaPipe::Status GetContract(CalculatorContract* cc);
// Open is called before any Process() calls, on a freshly constructed
// calculator. Subclasses may override this method to perform necessary
// setup, and possibly output Packets and/or set output streams' headers.
// ...
virtual ::MediaPipe::Status Open(CalculatorContext* cc) {
return ::MediaPipe::OkStatus();
}
// Processes the incoming inputs. May call the methods on cc to access
// inputs and produce outputs.
// ...
virtual ::MediaPipe::Status Process(CalculatorContext* cc) = 0;
// Is called if Open() was called and succeeded. Is called either
// immediately after processing is complete or after a graph run has ended
// (if an error occurred in the graph). ...
virtual ::MediaPipe::Status Close(CalculatorContext* cc) {
return ::MediaPipe::OkStatus();
}
...
};
(2) 计算单元的生命周期
在MediaPipe图的初始化过程中,框架调用GetContract()静态方法来确定需要什么类型的包。该框架为每个图形运行构造和销毁整个计算单元(例如,一次视频或一次图像)。在图形运行中保持不变的昂贵或大型对象应该作为输入端包提供,这样计算就不会在后续运行中重复。
初始化后,对于图的每次运行,顺序如下:
Open()Process()(重复的)Close()
框架调用Open()来初始化计算单元。Open()应该解释所有选项,并设置计算单元的每个图形运行状态。Open()可以获取输入端数据包并将数据包写入计算单元输出。如果合适的话,它应该调用SetOffset()来减少输入流的潜在的数据流缓冲。
对于有输入的计算单元,只要至少有一个输入有可用的包,框架就调用Process()。该框架保证所有输入都具有相同的时间戳,并且时间戳会随着对Process()的每次调用而增加,并且所有数据包都被传递。因此,在调用Process()时,一些输入可能没有任何数据包。数据包丢失的输入似乎会产生一个空数据包(没有时间戳)。
在所有对Process()的调用之后,框架都会调用Close()。所有的输入都已耗尽,但是Close()可以访问输入端包并可以写输出。关闭返回后,计算单元被销毁。
没有输入的计算单元称为源。只要源计算单元返回Ok状态,它就继续调用Process()。源计算单元通过返回一个停止状态(即MediaPipe::tool::StatusStop)来指示它已被耗尽。
(3) 识别输入和输出
计算单元的公共接口由一组输入流和输出流组成。在CalculatorGraphConfiguration中,一些计算单元的输出使用命名流连接到其他计算单元的输入。流名称通常为小写,而输入和输出标记通常为大写。在下面的示例中,使用名为video_stream的流将标记名为VIDEO的输出连接到标记名为VIDEO_IN的输入。
# Graph describing calculator SomeAudioVideoCalculator
node {
calculator: "SomeAudioVideoCalculator"
input_stream: "INPUT:combined_input"
output_stream: "VIDEO:video_stream"
}
node {
calculator: "SomeVideoCalculator"
input_stream: "VIDEO_IN:video_stream"
output_stream: "VIDEO_OUT:processed_video"
}
输入和输出流可以通过索引编号、标签名称或标签名称和索引编号的组合来标识。在下面的示例中可以看到输入和输出标识符的一些示例。SomeAudioVideoCalculator通过标签识别其视频输出,通过标签和索引的组合识别其音频输出。带有标记VIDEO的输入连接到名为video_stream的流。标记AUDIO和索引0和1的输出连接到名为audio_left和audio_right的流。SomeAudioCalculator仅通过索引(不需要标签)识别它的音频输入。
# Graph describing calculator SomeAudioVideoCalculator
node {
calculator: "SomeAudioVideoCalculator"
input_stream: "combined_input"
output_stream: "VIDEO:video_stream"
output_stream: "AUDIO:0:audio_left"
output_stream: "AUDIO:1:audio_right"
}
node {
calculator: "SomeAudioCalculator"
input_stream: "audio_left"
input_stream: "audio_right"
output_stream: "audio_energy"
}
在计算单元实现中,输入和输出也通过标记名称和索引号来标识。在下面的函数中输入和输出都有标识:
- 根据索引号:组合后的输入流仅通过索引0来标识。
- 标签名称:通过标签名称“video”来标识视频输出流。
- 根据标签名和索引号:输出的音频流由标签名audio和索引号0和1的组合来识别。
// c++ Code snippet describing the SomeAudioVideoCalculator GetContract() method
class SomeAudioVideoCalculator : public CalculatorBase {
public:
static ::mediapipe::Status GetContract(CalculatorContract* cc) {
cc->Inputs().Index(0).SetAny();
// SetAny() is used to specify that whatever the type of the
// stream is, it's acceptable. This does not mean that any
// packet is acceptable. Packets in the stream still have a
// particular type. SetAny() has the same effect as explicitly
// setting the type to be the stream's type.
cc->Outputs().Tag("VIDEO").Set<ImageFrame>();
cc->Outputs().Get("AUDIO", 0).Set<Matrix>();
cc->Outputs().Get("AUDIO", 1).Set<Matrix>();
return ::mediapipe::OkStatus();
}
(4) 计算单元执行
在非源节点上调用Process()必须返回::mediapipe::OkStatus()来表示一切正常,或者返回任何其他状态代码来表示错误。如果一个非源计算单元返回tool::StatusStop(),那么这表示这个图被提前取消了。在这种情况下,所有源计算单元和图形输入流将被关闭(其余的包将通过图形传播)。图中的源节点将继续调用Process(),只要它返回::mediapipe::OkStatus()。为了表示不再生成数据,返回tool::StatusStop()。任何其他状态都表示发生了错误。Close()返回::mediapipe::OkStatus()表示成功。任何其他状态都表示失败。
下面是基本的Process()函数。它使用Input()方法(只有在计算单元只有一个输入时才可以使用)来请求输入数据。然后,它使用std::unique_ptr分配输出包所需的内存,并执行计算。完成后,它会在将指针添加到输出流时释放指针。
::util::Status MyCalculator::Process() {
const Matrix& input = Input()->Get<Matrix>();
std::unique_ptr<Matrix> output(new Matrix(input.rows(), input.cols()));
// do your magic here....
// output->row(n) = ...
Output()->Add(output.release(), InputTimestamp());
return ::mediapipe::OkStatus();
}
(5) 计算单元Demo
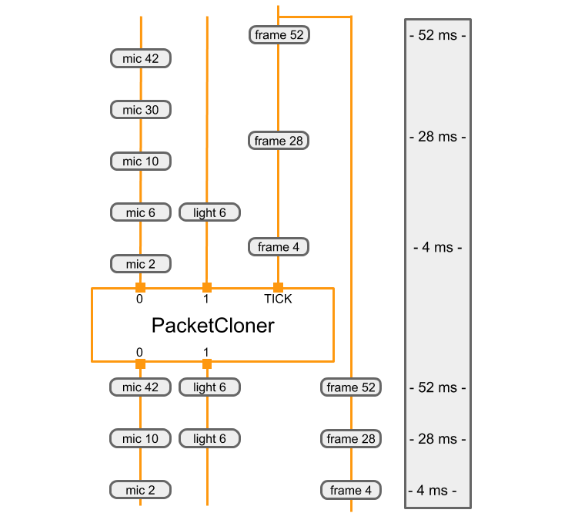
本节讨论PacketClonerCalculator的实现,它执行一项相对简单的工作,并在许多计算单元图中使用。PacketClonerCalculator只是根据需要生成其最近的输入数据流的副本。
当到达的数据包的时间戳没有完全对齐时,PacketClonerCalculator非常有用。假设我们有一个房间,里面有麦克风、光传感器和一个正在收集感官数据的摄像机。每个传感器独立工作,间歇地收集数据。设每个传感器的输出为:
- 传声器=响度(以房间内声音的分贝为单位)
- 光传感器=房间亮度(整数)
- 摄像机=房间RGB图像帧(ImageFrame)
我们的简单感知管道被设计来处理来自这3个传感器的数据,这样在任何时候当我们有来自相机的图像帧数据,与最后收集的麦克风音量数据和光传感器亮度数据同步。要用MediaPipe做到这一点,我们的感知管道有3个输入流: - room_mic_signal——这个输入流中的每个数据包都是整数数据,表示音频在的房间中有多响,并带有时间戳。
- room_lightening_sensor—这个输入流中的每个数据包都是整数数据,表示照亮房间的亮度,并带有时间戳
- room_video_tick_signal—该输入流中的每个数据包都是视频数据的图像帧,表示从房间内的摄像机收集的视频,并带有时间戳。
下面是PacketClonerCalculator的实现。您可以看到GetContract()、Open()和Process()方法以及实例变量current_,它包含最近的输入数据包。
// This takes packets from N+1 streams, A_1, A_2, ..., A_N, B.
// For every packet that appears in B, outputs the most recent packet from each
// of the A_i on a separate stream.
#include <vector>
#include "absl/strings/str_cat.h"
#include "mediapipe/framework/calculator_framework.h"
namespace mediapipe {
// For every packet received on the last stream, output the latest packet
// obtained on all other streams. Therefore, if the last stream outputs at a
// higher rate than the others, this effectively clones the packets from the
// other streams to match the last.
//
// Example config:
// node {
// calculator: "PacketClonerCalculator"
// input_stream: "first_base_signal"
// input_stream: "second_base_signal"
// input_stream: "tick_signal"
// output_stream: "cloned_first_base_signal"
// output_stream: "cloned_second_base_signal"
// }
//
class PacketClonerCalculator : public CalculatorBase {
public:
static ::mediapipe::Status GetContract(CalculatorContract* cc) {
const int tick_signal_index = cc->Inputs().NumEntries() - 1;
// cc->Inputs().NumEntries() returns the number of input streams
// for the PacketClonerCalculator
for (int i = 0; i < tick_signal_index; ++i) {
cc->Inputs().Index(i).SetAny();
// cc->Inputs().Index(i) returns the input stream pointer by index
cc->Outputs().Index(i).SetSameAs(&cc->Inputs().Index(i));
}
cc->Inputs().Index(tick_signal_index).SetAny();
return ::mediapipe::OkStatus();
}
::mediapipe::Status Open(CalculatorContext* cc) final {
tick_signal_index_ = cc->Inputs().NumEntries() - 1;
current_.resize(tick_signal_index_);
// Pass along the header for each stream if present.
for (int i = 0; i < tick_signal_index_; ++i) {
if (!cc->Inputs().Index(i).Header().IsEmpty()) {
cc->Outputs().Index(i).SetHeader(cc->Inputs().Index(i).Header());
// Sets the output stream of index i header to be the same as
// the header for the input stream of index i
}
}
return ::mediapipe::OkStatus();
}
::mediapipe::Status Process(CalculatorContext* cc) final {
// Store input signals.
for (int i = 0; i < tick_signal_index_; ++i) {
if (!cc->Inputs().Index(i).Value().IsEmpty()) {
current_[i] = cc->Inputs().Index(i).Value();
}
}
// Output if the tick signal is non-empty.
if (!cc->Inputs().Index(tick_signal_index_).Value().IsEmpty()) {
for (int i = 0; i < tick_signal_index_; ++i) {
if (!current_[i].IsEmpty()) {
cc->Outputs().Index(i).AddPacket(
current_[i].At(cc->InputTimestamp()));
// Add a packet to output stream of index i a packet from inputstream i
// with timestamp common to all present inputs
//
} else {
cc->Outputs().Index(i).SetNextTimestampBound(
cc->InputTimestamp().NextAllowedInStream());
// if current_[i], 1 packet buffer for input stream i is empty, we will set
// next allowed timestamp for input stream i to be current timestamp + 1
}
}
}
return ::mediapipe::OkStatus();
}
private:
std::vector<Packet> current_;
int tick_signal_index_;
};
REGISTER_CALCULATOR(PacketClonerCalculator);
} // namespace mediapipe
通常,计算单元只有一个.cc文件。不需要.h,因为mediapipe使用注册来让它知道计算单元。定义计算单元类之后,使用宏调用REGISTER_CALCULATOR(calculator_class_name)注册它。
input_stream: "room_mic_signal"
input_stream: "room_lighting_sensor"
input_stream: "room_video_tick_signal"
node {
calculator: "PacketClonerCalculator"
input_stream: "room_mic_signal"
input_stream: "room_lighting_sensor"
input_stream: "room_video_tick_signal"
output_stream: "cloned_room_mic_signal"
output_stream: "cloned_lighting_sensor"
}
下面的图表显示了PacketClonerCalculator如何根据它的一系列输入数据包(顶部)定义它的输出数据包(底部)。
2.2 图结构(Graphs)
(1) 图配置
GraphConfig是描述MediaPipe图的拓扑和功能的规范。在规范中,图中的节点表示特定计算单元的实例。节点的所有必要配置,如类型、输入和输出,都必须在规范中描述。节点的描述还可以包括几个可选字段,比如同步中讨论的特定于节点的选项、输入策略和executor。
GraphConfig还有其他几个字段来配置全局图形级设置,例如,图执行器配置、线程数量和输入流的最大队列大小。有几个图级别的设置对于在不同平台(例如桌面和移动平台)上调优图的性能非常有用。例如,在移动设备上,将一个重型模型推断计算单元附加到一个单独的执行器可以提高实时应用程序的性能,因为它支持线程局部化。
下面是一个简单的GraphConfig示例,其中我们有一系列的直通计算单元:
# This graph named main_pass_throughcals_nosubgraph.pbtxt contains 4
# passthrough calculators.
input_stream: "in"
node {
calculator: "PassThroughCalculator"
input_stream: "in"
output_stream: "out1"
}
node {
calculator: "PassThroughCalculator"
input_stream: "out1"
output_stream: "out2"
}
node {
calculator: "PassThroughCalculator"
input_stream: "out2"
output_stream: "out3"
}
node {
calculator: "PassThroughCalculator"
input_stream: "out3"
output_stream: "out4"
}
(2) 子图
要将CalculatorGraphConfig模块化为子模块并帮助重用感知解决方案,可以将MediaPipe图定义为子图。子图的公共接口由一组输入和输出流组成,类似于计算单元的公共接口。然后可以将子图像计算单元一样包含在CalculatorGraphConfig中。当从CalculatorGraphConfig加载MediaPipe图时,每个子图节点都被相应的计算单元图替换。因此,子图的语义和性能与相应的计算单元图是相同的。
下面是如何创建名为TwoPassThroughSubgraph的子图的示例。
- 定义子图
# This subgraph is defined in two_pass_through_subgraph.pbtxt
# and is registered as "TwoPassThroughSubgraph"
type: "TwoPassThroughSubgraph"
input_stream: "out1"
output_stream: "out3"
node {
calculator: "PassThroughculator"
input_stream: "out1"
output_stream: "out2"
}
node {
calculator: "PassThroughculator"
input_stream: "out2"
output_stream: "out3"
}
子图的公共接口包括:
- 图输入流
- 图形输出流
- 图形输入端包
- 图形输出端包
- 使用构建规则
mediapipe_simple_subgraph注册子图。参数register_as定义了新子图的组件名。
# Small section of BUILD file for registering the "TwoPassThroughSubgraph"
# subgraph for use by main graph main_pass_throughcals.pbtxt
mediapipe_simple_subgraph(
name = "twopassthrough_subgraph",
graph = "twopassthrough_subgraph.pbtxt",
register_as = "TwoPassThroughSubgraph",
deps = [
"//mediapipe/calculators/core:pass_through_calculator",
"//mediapipe/framework:calculator_graph",
],
)
- 使用主图中的子图
# This main graph is defined in main_pass_throughcals.pbtxt
# using subgraph called "TwoPassThroughSubgraph"
input_stream: "in"
node {
calculator: "PassThroughCalculator"
input_stream: "in"
output_stream: "out1"
}
node {
calculator: "TwoPassThroughSubgraph"
input_stream: "out1"
output_stream: "out3"
}
node {
calculator: "PassThroughCalculator"
input_stream: "out3"
output_stream: "out4"
}
(3) 循环
默认情况下,MediaPipe要求计算单元图是非循环的,并将图中的循环视为错误。如果图要具有循环,则需要在图配置中对循环进行注释。
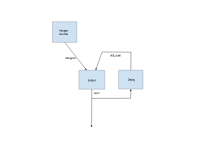
请使用CalculatorGraphTest。循环单元测试在mediapipe/framework/calculator_graph_test。cc作为示例代码。下面是测试中的循环图。加法器输出的和是整数源计算单元生成的整数的和。
-
背部边缘注释
我们要求每个循环中的一条边被标注为后边。这允许MediaPipe的拓扑排序在删除所有后边缘后工作。
通常有多种方法来选择后边缘。哪些边被标记为后边会影响哪些节点被认为是上游节点,哪些节点被认为是下游节点,进而影响MediaPipe分配给节点的优先级。
例如,CalculatorGraphTest.Cycle测试将old_sum边标记为后边,因此将延迟节点视为加法器节点的下游节点,并给予较高的优先级。或者,我们可以将延迟节点的输入和标记为后边,在这种情况下,延迟节点将被视为加法器节点的上游节点,并被给予较低的优先级。 -
初始化数据流
当整数源的第一个整数到达时,加法器计算单元可以运行,我们需要一个初始包,值为0,时间戳相同,在加法器的old_sum输入流上。这个初始包应该由Open()方法中的延迟计算单元输出。 -
循环延迟
每个循环都应该延迟前一个和输出与下一个整数输入的对齐。这也是由延迟节点完成的。因此延迟节点需要知道以下整数源计算单元的时间戳:
- 第一个输出的时间戳。
- 连续输出之间的时间戳增量。
我们计划添加一个替代的调度策略,它只关心包的顺序,而忽略包的时间戳,这将消除这种不便。
-
当一个输入流完成时,提前终止计算单元
默认情况下,当完成非源计算单元的所有输入流时,MediaPipe调用其Close()方法。在示例图行中,我们希望在完成整数源后立即停止加法器节点。这是通过使用另一个输入流处理程序EarlyCloseInputStreamHandler配置加法器节点来完成的。 -
相关的源代码
延迟计算单元
请注意Open()中输出初始数据包的代码和Process()中为输入数据包添加(单位)延迟的代码。如上所述,这个延迟节点假设它的输出流与数据包时间戳为0,1,2,3,…的输入流一起使用。
class UnitDelayCalculator : public Calculator {
public:
static ::util::Status FillExpectations(
const CalculatorOptions& extendable_options, PacketTypeSet* inputs,
PacketTypeSet* outputs, PacketTypeSet* input_side_packets) {
inputs->Index(0)->Set<int>("An integer.");
outputs->Index(0)->Set<int>("The input delayed by one time unit.");
return ::mediapipe::OkStatus();
}
::util::Status Open() final {
Output()->Add(new int(0), Timestamp(0));
return ::mediapipe::OkStatus();
}
::util::Status Process() final {
const Packet& packet = Input()->Value();
Output()->AddPacket(packet.At(packet.Timestamp().NextAllowedInStream()));
return ::mediapipe::OkStatus();
}
};
图配置
请注意back_edge注释和替代的input_stream_handler。
node {
calculator: 'GlobalCountSourceCalculator'
input_side_packet: 'global_counter'
output_stream: 'integers'
}
node {
calculator: 'IntAdderCalculator'
input_stream: 'integers'
input_stream: 'old_sum'
input_stream_info: {
tag_index: ':1' # 'old_sum'
back_edge: true
}
output_stream: 'sum'
input_stream_handler {
input_stream_handler: 'EarlyCloseInputStreamHandler'
}
}
node {
calculator: 'UnitDelayCalculator'
input_stream: 'sum'
output_stream: 'old_sum'
}
2.3 数据包(Packets)
每个计算单元都是图形的一个节点。我们将描述如何创建新的计算单元、如何初始化计算单元、如何执行其计算、输入和输出流、时间戳和选项
数据包通常是用MediaPipe::Adopt()(从package .h中)创建的。
// Create some data.
auto data = gtl::MakeUnique<MyDataClass>("constructor_argument");
// Create a packet to own the data.
Packet p = Adopt(data.release());
// Make a new packet with the same data and a different timestamp.
Packet p2 = p.At(Timestamp::PostStream());
通过packet::Get<T>()访问数据包内的数据
2.4 同步性(synchronization)
(1) 调度机制
MediaPipe图中的数据处理发生在定义为CalculatorBase子类的处理节点中。调度系统决定何时运行每个计算单元。
每个图至少有一个调度程序队列。每个调度器队列只有一个执行器。节点被静态地分配给一个队列(因此分配给一个执行器)。默认情况下,有一个队列,它的执行器是一个线程池,根据系统的能力有许多线程。
每个节点都有一个调度状态,可以是未就绪、就绪或正在运行。准备函数确定节点是否准备运行。在图形初始化时,每当节点结束运行,以及每当节点的输入状态发生变化时,都会调用此函数。
使用的就绪函数取决于节点的类型。没有流输入的节点称为源节点;源节点总是准备运行,直到它们告诉框架它们没有更多的数据要输出,这时它们就会关闭。
如果非源节点有要处理的输入,并且根据节点的输入策略设置的条件(下面将讨论),这些输入形成了一个有效的输入集,那么它们就准备好了。
大多数节点使用默认的输入策略,但有些节点指定不同的输入策略。
注意:因为更改输入策略会更改计算单元代码期望从其输入得到的保证,所以通常不可能将计算单元与任意输入策略混合匹配。因此,应该为使用特殊输入策略的计算单元编写它,并声明它。
当一个节点准备就绪时,一个任务被添加到相应的调度程序队列中,这是一个优先队列。优先级函数目前是固定的,考虑到节点的静态属性及其在图中的拓扑排序。例如,靠近图的输出端的节点具有更高的优先级,而源节点具有最低的优先级。
每个队列由一个执行器提供服务,执行器负责通过调用计算单元的代码实际运行任务。可提供和配置不同的执行器;这可以用来定制执行资源的使用,例如在低优先级线程上运行某些节点。
(2) 时间戳同步
MediaPipe图形执行是分散的:没有全局时钟,不同的节点可以同时处理来自不同时间戳的数据。这允许通过流水线获得更高的吞吐量。
然而,时间信息对于许多感知工作流是非常重要的。接收多个输入流的节点通常需要以某种方式协调它们。例如,一个对象检测器可以从一个帧中输出一列边界矩形,并且这个信息可以被输入到一个渲染节点,该节点应该与原始帧一起处理它。
因此,MediaPipe框架的关键职责之一是为节点提供输入同步。就框架机制而言,时间戳的主要作用是充当同步键。
此外,MediaPipe被设计为支持确定性操作,这在许多场景(测试、模拟、批处理等)中非常重要,同时允许图在需要满足实时约束的地方放松确定性。
同步和决定论这两个目标是几种设计选择的基础。值得注意的是,推入给定流的数据包必须具有单调递增的时间戳:这不仅是对许多节点有用的假设,而且同步逻辑也依赖于此。每个流都有一个时间戳限制,这是流上新包允许的最低时间戳。当一个时间戳为T的数据包到达时,边界自动推进到T+1,反映了单调要求。这允许框架确定没有更多时间戳小于T的数据包会到达。
(3) 输入策略
同步在每个节点上使用,节点指定的输入策略本地处理。
由DefaultInputStreamHandler定义的默认输入策略提供了确定性的输入同步,并提供了以下保证:
- 如果在多个输入流上提供具有相同时间戳的数据包,那么无论它们的到达顺序如何,它们总是一起被处理。
- 输入集严格按照时间戳升序进行处理。
- 没有数据包被丢弃,处理是完全确定的。
- 根据上述保证,节点可以尽快处理数据。
注意:这样做的一个重要结果是,如果计算单元在输出包时总是使用当前的输入时间戳,那么输出将必然服从单调递增的时间戳要求。
警告:另一方面,不能保证输入包总是对所有流可用。
为了解释它是如何工作的,我们需要引入固定时间戳的定义。如果流中的时间戳低于时间戳的限制,我们就说它是稳定的。换句话说,一旦输入在该时间戳处的状态不可挽回地已知,流的时间戳就确定下来了:要么存在一个包,要么确定具有该时间戳的包不会到达。
注意:由于这个原因,MediaPipe还允许流生成器显式地将时间戳的绑定比上一个包的绑定更进一步,即提供更紧密的绑定。这可以让下游节点更快地确定它们的输入。
如果时间戳在每个流上都已确定,那么它将跨多个流确定。而且,如果一个时间戳被解决了,就意味着之前所有的时间戳也被解决了。因此,已确定的时间戳可以按升序确定地处理。
根据这个定义,如果存在一个时间戳,该时间戳在所有输入流中都得到了解决,并且至少在一个输入流中包含了一个包,那么具有默认输入策略的计算单元就准备好了。输入策略将一个已解决时间戳的所有可用数据包作为单个输入集提供给计算单元。
这种确定性行为的一个结果是,对于具有多个输入流的节点来说,理论上可以无限制地等待时间戳的确定,同时可以无限制地缓冲数量的数据包。(考虑一个有两个输入流的节点,其中一个一直发送数据包,而另一个什么也不发送,并且不推进边界。)
因此,我们还提供了定制的输入策略:例如,将输入分割到由SyncSetInputStreamHandler定义的不同同步集中,或者完全避免同步并在输入到达时立即处理由立即inputstreamhandler定义的输入。
(4) 流控制
有两种主要的流量控制机制。当流上缓冲的数据包达到由CalculatorGraphConfig::max_queue_size定义的(可配置的)限制时,反压力机制会对上游节点的执行进行节流。此机制维护确定性行为,并包括一个死锁避免系统,该系统在需要时放松配置的限制。
第二个系统由插入特殊节点组成,这些节点可以根据FlowLimiterCalculator定义的实时约束(通常使用自定义输入策略)来丢弃数据包。例如,一种常见的模式将流控制节点放置在子图的输入处,并带有从最终输出到流控制节点的环回连接。流控制节点因此能够跟踪在下游图中有多少时间戳正在被处理,如果这个计数达到(可配置的)限制,就会丢弃数据包;由于数据包是在上游丢弃的,因此我们避免了部分处理时间戳然后在中间阶段丢弃数据包所造成的工作浪费。
这种基于计算单元的方法使图可以控制在哪里可以丢弃数据包,并允许根据资源约束灵活地适应和定制图的行为。
2.5 GPU
(1) 概述
MediaPipe支持用于GPU计算和渲染的计算单元节点,并允许合并多个GPU节点,以及将它们与基于CPU的计算单元节点混合。移动平台上有几个GPU APIs(如OpenGL ES、Metal和Vulkan)。MediaPipe并不尝试提供单一的跨API GPU抽象。各个节点可以使用不同的API编写,从而允许它们在需要时利用平台特定的特性。
GPU支持对于移动平台的良好性能至关重要,特别是对于实时视频。MediaPipe使开发者能够编写支持GPU使用的GPU兼容计算单元:
- 设备上的实时处理,而不仅仅是批处理
- 视频渲染和效果,不仅仅是分析
下面是MediaPipe中GPU支持的设计原则
- 基于gpu的计算单元应该能够出现在图的任何地方,而不一定用于屏幕上的渲染。
- 帧数据从一个基于gpu的计算单元传输到另一个计算单元应该是快速的,而且不会导致昂贵的复制操作。
- CPU和GPU之间的帧数据传输应该在平台允许的情况下尽可能高效。
- 因为不同的平台可能需要不同的技术来获得最佳性能,所以API应该允许在幕后实现方式上的灵活性。
- 一个计算单元应该被允许在使用GPU的全部或部分操作的最大灵活性,如果必要的话,将它与CPU结合。
(2) OpenGL ES支持
MediaPipe在Android/Linux上支持OpenGL ES到3.2版本,在iOS上支持es3.0版本。此外,MediaPipe还支持iOS上的Metal。
运行机器学习推理计算单元和图形需要OpenGL ES 3.1或更高版本(在Android/Linux系统上)。
MediaPipe允许图在多个GL上下文中运行OpenGL。举例来说,这可能是非常有用的在图表结合较慢的GPU推理路径(例如,在10帧/秒)和更快的GPU渲染路径(如30 FPS):因为一个GL上下文对应于一个连续的命令队列,这两个任务使用相同的背景将会减少渲染的帧速率。
MediaPipe使用多个上下文解决的一个挑战是跨它们进行通信的能力。一个示例场景是一个同时发送到呈现和推理路径的输入视频,呈现需要访问推理的最新输出。
一个OpenGL上下文不能被多个线程同时访问。此外,在某些Android设备上,在同一线程上切换活动GL上下文可能会很慢。因此,我们的方法是为每个上下文设置一个专用线程。每个线程发出GL命令,在其上下文上建立一个串行命令队列,然后由GPU异步执行。
(3) GPU计算单元的生命周期
本节介绍了基于GlSimpleCalculator基类派生的GPU计算单元处理方法的基本结构。GPU计算单元是一个例子。方法LuminanceCalculator::GlRender是从GlSimpleCalculator::Process中调用的。
// Converts RGB images into luminance images, still stored in RGB format.
// See GlSimpleCalculator for inputs, outputs and input side packets.
class LuminanceCalculator : public GlSimpleCalculator {
public:
::mediapipe::Status GlSetup() override;
::mediapipe::Status GlRender(const GlTexture& src,
const GlTexture& dst) override;
::mediapipe::Status GlTeardown() override;
private:
GLuint program_ = 0;
GLint frame_;
};
REGISTER_CALCULATOR(LuminanceCalculator);
::mediapipe::Status LuminanceCalculator::GlRender(const GlTexture& src,
const GlTexture& dst) {
static const GLfloat square_vertices[] = {
-1.0f, -1.0f, // bottom left
1.0f, -1.0f, // bottom right
-1.0f, 1.0f, // top left
1.0f, 1.0f, // top right
};
static const GLfloat texture_vertices[] = {
0.0f, 0.0f, // bottom left
1.0f, 0.0f, // bottom right
0.0f, 1.0f, // top left
1.0f, 1.0f, // top right
};
// program
glUseProgram(program_);
glUniform1i(frame_, 1);
// vertex storage
GLuint vbo[2];
glGenBuffers(2, vbo);
GLuint vao;
glGenVertexArrays(1, &vao);
glBindVertexArray(vao);
// vbo 0
glBindBuffer(GL_ARRAY_BUFFER, vbo[0]);
glBufferData(GL_ARRAY_BUFFER, 4 * 2 * sizeof(GLfloat), square_vertices,
GL_STATIC_DRAW);
glEnableVertexAttribArray(ATTRIB_VERTEX);
glVertexAttribPointer(ATTRIB_VERTEX, 2, GL_FLOAT, 0, 0, nullptr);
// vbo 1
glBindBuffer(GL_ARRAY_BUFFER, vbo[1]);
glBufferData(GL_ARRAY_BUFFER, 4 * 2 * sizeof(GLfloat), texture_vertices,
GL_STATIC_DRAW);
glEnableVertexAttribArray(ATTRIB_TEXTURE_POSITION);
glVertexAttribPointer(ATTRIB_TEXTURE_POSITION, 2, GL_FLOAT, 0, 0, nullptr);
// draw
glDrawArrays(GL_TRIANGLE_STRIP, 0, 4);
// cleanup
glDisableVertexAttribArray(ATTRIB_VERTEX);
glDisableVertexAttribArray(ATTRIB_TEXTURE_POSITION);
glBindBuffer(GL_ARRAY_BUFFER, 0);
glBindVertexArray(0);
glDeleteVertexArrays(1, &vao);
glDeleteBuffers(2, vbo);
return ::mediapipe::OkStatus();
}
以上设计原则导致MediaPipe GPU支持的设计选择如下:
-
我们有一个GPU数据类型,称为GpuBuffer,用于表示图像数据,为GPU使用而优化。这种数据类型的确切内容是不透明的,并且是特定于平台的。
-
基于composition的低级API,任何想要使用GPU的计算单元都会创建并拥有一个GlCalculatorHelper类的实例。这个类提供了一个平台无关的API,用于管理OpenGL上下文,为输入和输出设置纹理,等等。
-
一个基于子类化的高级API,其中实现图像过滤器的简单计算单元子类来自GlSimpleCalculator,只需要覆盖一对虚拟方法与它们的特定OpenGL代码,而超类负责所有管道。
-
需要在所有基于gpu的计算单元之间共享的数据被作为外部输入提供,它被实现为一个图服务,并由GlCalculatorHelper类管理。
-
calculator-specific助手和一个共享图服务让我们极大的灵活性在管理GPU资源:我们可以有一个单独的上下文/计算单元,共享一个上下文,分享一个锁或其他同步,等等,所有的这些都是由辅助管理和隐藏的个人计算单元。
(4) GpuBuffer到图像帧转换器
我们提供了两个计算单元称为GpuBufferToImageFrameCalculator和ImageFrameToGpuBufferCalculator。这些计算单元在ImageFrame和GpuBuffer之间转换,允许结合GPU和CPU计算单元的图形的构造。iOS和Android都支持它们
如果可能,这些计算单元使用特定平台的功能来在CPU和GPU之间没有复制的共享数据。
下图显示了移动应用程序中的数据流,该应用程序从摄像头捕获视频,通过MediaPipe图形运行视频,并实时将输出呈现在屏幕上。虚线表示哪些部分位于MediaPipe图内部。这个应用程序使用OpenCV在CPU上运行一个精巧的边缘检测过滤器,并使用GPU将其覆盖在原始视频上。
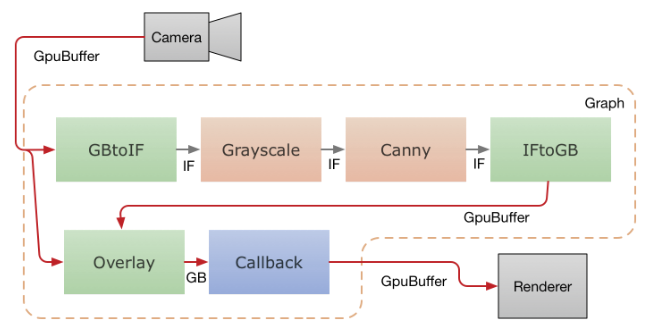
从摄像机的视频帧作为GpuBuffer数据包被馈入图。输入流由两个计算单元并行地访问。GpuBufferToImageFrameCalculator将缓冲区转换为ImageFrame,然后通过灰度转换器和canny过滤器(都基于OpenCV并在CPU上运行)发送,后者的输出然后再次转换为GpuBuffer。一个多输入GPU计算单元,GlOverlayCalculator,接受原始的GpuBuffer和从边缘检测器出来的作为输入,并使用着色器覆盖它们。然后使用回调计算单元将输出发送回应用程序,应用程序使用OpenGL将图像呈现到屏幕上。