Fast Burst Images Denoising
Abstract
本文提出了一种快速去噪方法,从一组噪声图像中提取出一幅清晰的图像。我们通过引入一种称为单应流的轻量级摄像机运动模型来加速图像的对齐。将对齐后的图像融合在一起,在时间和空间域通过快速逐像素操作进行图像去噪。为了处理捕获场景运动,提出了一种选择一致像素进行时域融合的机制来“合成”一幅干净、无虚影的图像,大大减少了帧间跟踪运动的计算量。结合这些有效的解决方案,我们的方法比以前的工作快几个数量级,而去噪的质量是可比的。一个智能手机原型表明,我们的方法是实用的,并在大量的实际例子中工作良好。
关键词: 去噪,突发图像,单应流,无鬼影
1. Introduction
Burst是大多数相机的一种拍摄模式,通过按下或按住快门按钮,可以在短时间内连续拍摄多个镜头。它的设计允许选择最好的镜头或记录运动。最近,突发捕获在许多手持成像设备(如智能手机、紧凑型相机和单反相机)中变得无处不在。
Burst模式已被成功地应用于计算摄影中,以减少模糊[Cai等人2009],或改善阴影/高光细节[Reinhard等人2010],或提高分辨率[Farsiu等人2004],或清晰度[Joshi和Cohen 2010],或景深[Jacobs等人2012]。
在本文中,我们提出了一种实用的“突发图像去噪”解决方案——将突发的噪声图像(通常在低光照条件下捕获)转换为单个干净的图像,如图1所示。这个问题并不新鲜。它已经在多幅图像/视频去噪的背景下进行了研究[Buades et al. 2010;刘和弗里曼2010;Zhang等人,2009]。但我们注重实用性-我们的目标是设计一个高效的方法,同时生产高质量结果表明,该算法能够在有限的计算资源下在移动设备上运行。
一个切实可行的方法需要应对两个挑战。首先是效率。目前最先进的方法严重依赖于光流或patch匹配来建立时空对应关系,速度慢得令人无法接受。其次是质量。由摄像机运动(通过握手)或场景运动(通过动态)引起的噪声和“幽灵”伪影“幽灵”方面, 像平均或滤波这样的快速方法[Tomasi和Manduchi 1998]都是不够的。而且,即使是一些复杂的方法,在强噪声或复杂的动态运动情况下也会显得脆弱。
我们提出了一种快速降噪的方法,从一组图像中产生一幅清晰的图像。我们的方法的高速度是通过引入三个加速步骤来实现的。在第一步中,我们使用轻量级的参数化运动表示-单应流--模拟由摄像机运动引起的运动。这种表现形式的灵感来自最近的多重同伦模型[Grundmann et al. 2012;Liu等人2013]用于视频稳定。由于估计单应流只需要稀疏特征匹配,因此这一步是有效的和鲁棒的噪音。
在第二步中,我们通过识别一致的像素来处理场景运动。从所有对齐的图像(通过第一步)沿时间轴的每个像素位置。这些选定的一致像素通过平均用于我们的时间像素融合(在第三步)。因此,我们可以生成无伪影的结果,同时避免动态对象的复杂运动跟踪,这是太慢或太难了。这个想法在最近的HDR 去伪影(Granados等人,2013年)中得到了成功的应用。为了更好地去噪,我们扩展了这一思想,在每个像素位置找到尽可能多的一致像素。
在第三步中,我们依次应用时间和多尺度像素融合来获得去噪结果。时间融合是基于一个简单的,最优的线性估计。多尺度融合是时间融合的补充,进一步实现了显著的去噪。同时,整个步骤在设计上也非常高效,因为它只涉及像素级的操作。
我们已经在各种真实数据上评估了我们的算法。在中或强噪音情况下,我们的算法可与最先进的多幅图像去噪方法(例如:VBM3D [Dabov et al. 2007a], BM4D [Maggioni et al. 2013])。此外,我们的算法要快两到三个数量级。图1显示了一个比较。

2. Related Work
单幅图像去噪近几十年来取得了很大的进展。代表性的方法有双边滤波[Tomasi和Manduchi 1998]、小波(小波)(GSM) [Portilla等,2003]、Field-OfExpert [Roth和Black 2005]、非局部均值[Buades等,2005]、BM3D [Dabov等,2007b]等。为了提高效率,已经提出了一些快速变体,如快速双边滤波[Paris和Durand 2009]、高斯kd-tree [Adams等人2009]和测地线路径[Chen等人2013]。最近,Levin等人[2011]指出,单一图像去噪可能是接近性能极限。NoiseBrush [Chen et al. 2009]提出了一种交互方式进一步提高去噪质量。
多幅图像去噪比单幅图像去噪效果好,因为多幅图像去噪可以获得更多的信息。一些去噪技术已成功地应用于突发图像[Tico 2008;Buades等人,2009;Joshi和Cohen 2010],视频[Bennett和McMillan 2005;刘和弗里曼2010;Dabov等,2007a;Chen和Tang 2007],多视图图像[Zhang et al. 2009],以及容量MRI数据[Maggioni et al. 2013]。
估计摄像机运动。光流[Brox et al. 2004]是建立帧间通信最普遍的表示。最近的研究[Liu和Freeman 2010]表明它在视频去噪中的重要性。但光流本身存在着遮挡、位移大、易受噪声干扰等问题。Patch匹配对噪声的鲁棒性更强,在多幅图像处理中得到了广泛的应用[Tico 2008;Buades等人,2009;Zhang等,2009;Maggioni et al. 2013;Sen等人2012年;Kalantari等人,2013]。然而,在存在强噪声的情况下,这两种非参数方法的性能都会迅速下降。摄像机在突发模式下的运动类似于视频稳定中的运动研究。近期工作[Grundmann et al. 2012;Liu等人[2013]证明了对摄像机运动使用空间变异单应性的成功。在这项工作中,我们使用了一个类似但更轻量级的参数化运动表示——单应流。
处理场景运动。因为光流或patch匹配本质上讲比较困难,最近的研究[Gallo et al. 2009;在HDR重建中,Granados等人[2013]通过为每个像素寻找一致的颜色子集来绕过运动估计来重建无伪影图像。Granados等[2013]的一致性检验依赖于对噪声分布的准确估计,这可能需要复杂的校准和超像素计算。我们是受此启发,将其应用于图像去噪。
多尺度去噪是利用跨尺度相似性进行降噪的一种有效方法。最近,Zontak等人[2013]提出了一种定向金字塔技术来寻找跨尺度的对应Patch,获得了最先进的结果。Zhang和Gunturk[2008]在多尺度框架中扩展了双边滤波器。我们使用一种基于金字塔的像素融合方法来提高结果质量。
3. Algorithm
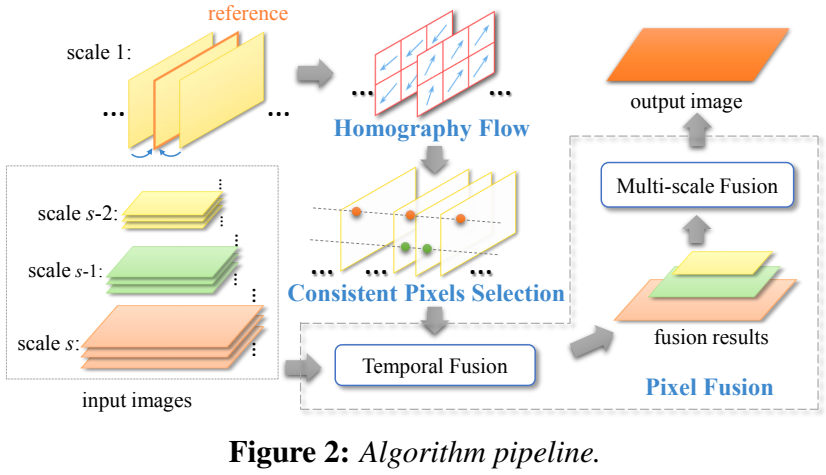
图2是我们的算法思路。我们首先对所有的噪声图像建立高斯金字塔,并将最中间的帧作为默认的参考帧。然后,我们估计单应射流(在3.1节中)来表示参考帧和任何其他帧之间的运动(通过摄像机)。通过对齐的图像(通过单应性流),在每个像素位置,我们选择一组一致的像素来处理场景运动(在章节3.2中)或可能由单应性流引起的未对齐情况。最后,我们应用像素融合(在3.3节中)来聚合所有尺度上的一致像素,以生成最终结果。
3.1 Homography Flow (for Camera Motion)
金字塔单应性图。我们通过一个金字塔单应图来表示两帧之间的运动,如图3 (a)所示精细级节点有助于产生细节。注意,独立估计每个节点的单应性是不可靠的,因为一些节点可能没有足够的匹配特征。接下来,我们介绍一个由粗到细的优化,以稳健地获得精确的结果。
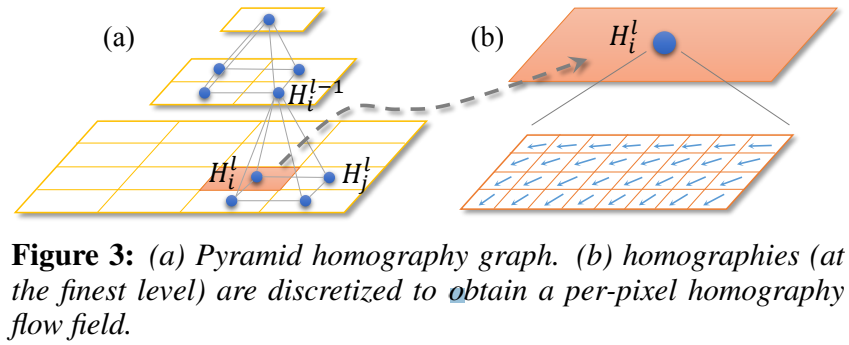
优化。我们从最粗的全局单应性 ( (l = 0) ) 开始逐级优化,令 (H^l_i)为节点 (i) 在 (l) 级的单应性,({H^l_j}) 为节点 (i) 的4个邻域同字型在同一层次。我们通过最小化以下能量函数来估计 ({H^l_i}) :
(lambda) (默认情况下,(lambda = 0.1) ) 控制空间正则的数量由第二项平滑项控制执行。在第一项 (R_{i}^{l}=operatorname{best}left(hat{H}_{i}^{l-1}, F_{i}^{l} ight)) 中,来自于两个候选,第一个是在 (l-1) 级上它的父单应性 (hat{H}^{l-1}_i) ,另一个是它自己估计的单应性 (F^l_i) (使用节点 (i) 网格内所有匹配的特征)。当我们不能很好的计算 (F^l_i) 时,就采用 (hat{H}^{l-1}_i) 作为备选方案。在我们实验中,如果在 (i) 的网格中特征数量小于8,或者 (F^l_i) 的刚性太弱,我们选择 (hat{H}^{l-1}_i) 。否则,我们选择网格内所有特征匹配误差较小的最佳模型。
因为目标函数(1)是二次的,我们可以通过Jacobi求解器[Bronshtein and Semendyayev 1997]获得全局最优。我们的运动模型的形式类似于基于网格的单应性[Liu et al. 2013]。但是我们的从粗到细的优化更有效。对于500个特征,我们的方法需要每帧5毫秒,而基于网格的单应性需要每帧50毫秒。
单应性流。由于金字塔单应性图是一种参数表示,我们需要在后面的去噪步骤中进行图像变形或坐标变换。但是,对所有像素(所有帧,所有尺度)进行这样的操作是非常昂贵的。为了解决我们应用程序中的这个关键问题,我们对单应性图(最细腻的水平)进行离散化,以获得逐像素平移向量---单应性流。
如图3 (b)所示,我们根据单应图将每个像素从一帧映射到另一帧来计算平移向量。最后,估计单应性流动按比例调整,四舍五入以供其他比例使用。
算法验证。我们在一组突发图像上评估全局单应性、光流、patch匹配和单应性流。我们要求4个不同的对象捕捉20组干净的突发图像(低ISO,在良好的照明条件下)。然后我们加入不同标准差的高斯噪声(从20到60)来合成100组有噪声的突发图像。为了注册这些有噪声的图像,我们比较了六种算法:全局单应性、光流[Liu 2009]、全局单应性+光流、patch匹配(穷举搜索)、全局单应性+ patch匹配和我们的单应性流。我们计算PSNR来测量已注册的干净图像对之间的差异。图4 (b)显示了结果。

从结果中,我们可以观察到两种基于光流的方法表现良好时噪音很小 ((σ= 20)) 。但是,当噪音水平增加,他们降解比其他更快;全局单应性能改善块状匹配,但不能改善光流。我们认为原因在于光流中由粗到细的机制已经处理了全局运动。我们的单应流在所有噪声水平下始终是最好的。
图4 (c)进一步显示了这些方法在不同大小的图像上的运行时间。由于全局单应性和我们的单应性流只依赖于稀疏特征的检测和匹配,因此,它们是一致的两者在速度上都优于patch match(穷行搜索甚至是随机搜索[Barnes et al. 2009])和optical flow [Liu 2009]。在两个运行时间曲线(全局单应性和我们的单应性流)之间只有一个小的边界,这表明我们的金字塔优化是非常有效的。
高效执行。这一步的瓶颈是稀疏特征提取和匹配。在我们的实现中,我们在亮度通道金字塔中的粗尺度(s = 1)上工作,以提高效率和鲁棒性(对噪声)。与原始尺度实现相比,时间成本大大降低(平均降低6倍),各种噪声sigma(从20到60)的PSNR(测量配准误差)提高了0.005dB到0.045dB。特别地,我们使用了Harris角点检测 [Harris and Stephens 1988]和128位简短描述符[Calonder et al. 2010],它甚至可以在移动电话上实现实时性能。我们使用局部RANSAC [Grundmann et al. 2012]来拒绝不正确匹配的特征。
此外,我们估计每个非重叠块(8×8像素)中的单应流,而不是每个像素。每个块中的所有像素共享相同的平移向量,这是通过映射计算得到的在两帧之间的块中心。这个近似值只是稍微降低了质量(PSNR接近0.01dB),但是却将像素映射加速了2.5倍。
3.2 Consistent Pixels Selection (for Scene Motions)
一致的像素。为了处理场景运动,我们借用了HDR deghosting [Granados et al. 2013]的一个简单想法,以避免复杂的运动跟踪。在每个像素位置(在一个参考帧上),我们在所有图像的一维轮廓上识别一组一致的像素(由估计的单应性流跟踪),用于时间像素融合。与HDR deghosting不同的是,选择一致像素的目的不仅是为了避免鬼影(由动态运动和帧未对齐引起的),而且是为了尽可能多的一致像素进行去噪。

有两种方法分别满足两个目标中的一个。一个是基于参考的:我们从参考帧的像素双向跟踪概要文件并收集一致的像素直到累积的像素差超过阈值 ( au)。另一种是median-based:我们收集像素中值一致(低于相同的阈值 (τ) )上的所有像素概要文件。参考方法可以保证无虚影的结果。但是对于动态对象上的一个像素,我们可能没有足够的样本进行去噪(如图5 (c)所示)。中位数方法收集更一致的像素,但可能导致重影,因为中位数可能恰好是移动对象上的一种颜色(如图5 (d)所示)。
相结合的策略。我们提出了两种方法的简单组合策略:对于每个像素(在参考帧上),我们通过中位数分别计算两组一致像素{M, R}以及参考方法。M(或R)记录每个像素的一致像素的帧索引。如果参考系属于M,我们取M和R的并集作为最终结果,因为两者都是同意的方法。否则,我们选择中位数结果,如果它是可靠的(即M的大小大于帧数的一半),如果参考结果不可靠,则选择参考结果。为了进一步减少伪影的机会(通过加强空间一致性),我们不逐个像素地测量可靠性。相反,我们找到未确定像素的所有连接组件(参考帧不属于M),然后通过多数投票来确定每个连接组件作为一个整体的可靠性。
组合后,得到所有像素的一致像素集。为了进一步实现无缝组合,我们运行一个3×3形态(多数)过滤[Gonzalez和Woods 2007]。在逐帧一致像素索引的堆栈上。图5 (a-b)显示了两个真实的例子和记录每个像素位置上一致像素的数量的地图。
高效执行。一致的像素也选择在粗尺度(即s = 1),目的是使快速计算和检测运动在一个相对干净的规模。在原尺度下以一半的时间进行操作,其近似值检出率可达98.7%。其他尺度只是通过上采样或下采样重复使用计算得到的一致像素的索引。在基于中位数和参考文献的方法中,我们使用patch(5×5)差分而不是单一的方法像素差和使用阈值 ( au=10)。我们使用积分图像[Viola和Jones 2001]来更有效地计算patch差异。
3.3 Pixels Fusion
给定每个像素在所有尺度上的一致性像素,我们将它们融合在一个时间和多尺度的融合中。我们保持融合尽可能简单,同时能够显着去噪。
时域融合。假设 ({x_t}) 是每个像素位置(在一定的范围内)上的一致像素,其中 (x_t) 是来自第t帧的像素颜色。我们通过线性最小均方误差(LMMSE)估计来计算的融合结果 (hat{x}) ,这是广泛应用于以前的工作(例如,[张、吴2005])最优无偏去噪:
其中 (mu) 为所有一致像素 ({x_t}) 的平均值。真实像素的方差 (sigma^2_c) 近似 (max(0, sigma^2_t-sigma^2))。(sigma_t) 和 (sigma) 分别是 ({x_t}) 和噪声的标准差。
LMMSE估计器可以帮助我们自适应地处理异常值。一些严重未对齐的像素出现在深度的不连续点(我们的单应流更适合于空间平滑深度变化)或细微的残留移动像素在一个精细的尺度(我们的场景运动检测是在一个粗糙的尺度上进行的)将使 (x_t) 的方差远远大于噪声方差。因此,我们融合结果将是(hat{x}→x_t) (没有去噪)。否则,结果(hat{x})值接近意味着 ({x_t}) 的平均值 (mu)。
时间融合在每个尺度上独立运行。接下来,我们将描述如何聚合所有尺度的结果。
多尺度融合。我们以点的方式自顶向下聚合结果。在两个相邻尺度 (s) 和 (s-1) 下, (x^s) 和 (x^{s-1}) 表示时域融合的结果。我们通过下面公式更新 (x^S) 结果:
其中 (uparrow) 是双线性扩大算子。(omega=sqrt{m / N}) 是一个自适应融合权重。(N) 为总帧数,(m) 为输入帧数()。(omega) 越大,意味着我们在当前尺寸下有更多的一致的像素和我们应该相信当前的估计;否则,我们更多参考父尺度。此外,多尺度处理对于处理真实成像管道中的非高斯类型的噪声(例如,斑点[Chatterjee et al. 2011])是有效的。
上述融合没有利用空间信息,而空间信息在单幅图像去噪算法中起着核心作用[Zontak et al. 2013]。在这里,我们将时间融合结果 (x^s) 代入上述方程在空间域进行非常快速的滤波:
其中滤波算子 (f(x^s)) 为方向空间像素融合。我们在一个 (5 imes 5) 的窗口内沿着最可能的边缘方向找到所有空间一致的像素。然后是LMMSE估计如式(2)所示,对这些像素进行处理。为了提高效率,我们只对纹理像素进行空间融合((p_{tex} > 0.01))。
纹理概率 函数 (p_{tex}) 计算通过sigmoid函数 (1 / (1 + exp (−5×(g /σ−3)))) ,(g) 是像素和它的4个相邻像素之间的最大绝对差,(σ) 噪声的估计标准差。为了提高效率,我们估计标准差 (σ) 通过计算像素的中值图像和参考图像之间的差异。在这些区域,中值图像(生成在粗糙的尺度)是一个很好的近似于一个干净的版本参考图像。对于真实的噪声,我们使用类似的方法[Liu et al. 2008]将照度分为10个离散箱并估计相应的 (σ) 。
扩展补丁。将时域融合和多尺度融合相结合的思想也可以扩展到patch级别,以获得更好的去噪质量。与点对点融合不同的是,patch的LMMSE估计器应用于频域,这与变换域中使用的维纳滤波器相似[Dabov et al. 2007b]。此外,基于patch的LMMSE估计器为每个像素提供重叠估计,这些像素需要patch聚合(沿时间轴或空间边缘方向)才能得到最终的融合结果。
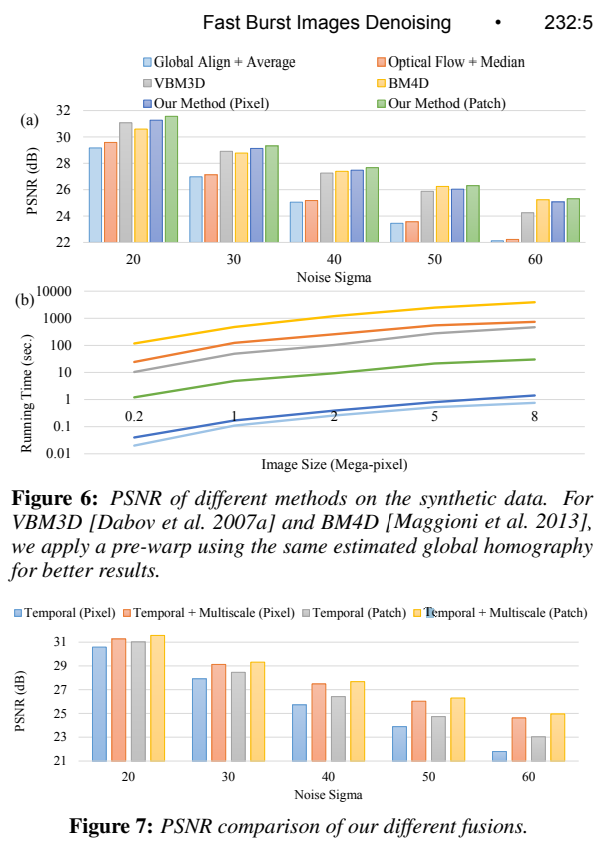
算法验证。我们对一个合成数据集进行定量评估。ground-truth clean图像来自于BSD300的68张图像[Martin et al. 2001]。模拟摄像机在移动中,我们重复使用来自真实数据的估计全局同形结构(图4),并将它们随机应用到一个干净的图像上,以生成一系列图像(10帧)。然后,我们添加高斯噪声与各种噪音水平(σ= 20∼60)。注意,我们的合成数据集忽略了真实数据中的许多关键因素:视差、非高斯噪声和非刚体运动。忽视这些关键因素可能导致不完整的结论。但是,我们还是在这里提供了一个初步的评价,以供参考,帮助我们更好的了解。
图6(a)显示了:平均(基线)、光流+中值滤波、VBM3D [Dabov et al. 2007a]、BM4D [Maggioni et al. 2013]、我们的方法(像素融合)和我们的方法(patch融合)的平均PSNRs。为了获得更好的结果,我们对所有方法应用了相同的全局单应性。
总的来说,我们的方法(使用像素融合)与VBM3D和BM4D(两种最先进的去噪方法)相比,在所有噪声水平上都优于平均和光流。当噪音水平增加,我们的方法执行稍微比BM4D差,但VBM3D下降比我们更快。这个评估部分地证明了我们的方法在真实的摄像机运动和配准误差存在的情况下的真正威力。请记住,我们的方法比VBM3D、光流和BM4D快2-3个数量级。图6(b)显示了这些方法在不同大小的图像上的运行时间。
此外,我们可以通过将融合扩展到patch级别来获得最好的结果。与两种基于patch的方法(VBM3D和BM4D)相比,我们的基于patch的融合仍然是有效的(1-2)数量级更快)。图7还展示了补丁在时间和多尺度融合方面都比像素表现得更好。这个结论与之前的工作是一致的,因为补丁通常可以使用比像素更多的空间相关信息。更有趣的是,多尺度融合作为时间像素融合的补充,在基于像素的方法中发挥着重要的作用。它大大减少了基于像素的方法和基于补丁的方法之间的差距。
4. Experiments
我们用5台相机采集了20套不同内容的突发图像,其中包括3台手机,1台单反相机,1台小型相机。每组包含10个镜头。我们所有的结果都是由一组固定的参数和基于像素的融合产生的。所有的原始序列和更多的结果都提供了我们的网页。
4.1 Comparisons
我们将我们的方法与三点方法(时空滤波[Bennett and McMillan 2005]、幸运成像[Joshi and Cohen 2010]、光流[Liu 2009] +时间中值滤波)以及两种最先进的基于patch的方法(VBM3D [Dabov et al. 2007a]和BM4D [Maggioni et al. 2013])进行了比较。前两个是基于我们自己的实现,和光流和后两者均来自作者。对于所有的方法,我们采用相同的全局单应性估计,以帮助他们获得更可靠的对应。由于某些算法需要已知的噪声方差,我们尝试所有可能的噪声水平,并通过细节恢复和噪声降低之间的平衡权衡,选择具有最佳视觉质量的结果。

静态场景。图8中的示例是由HTC 802d Android手机捕获的。运动主要是由相机的运动引起的。这种情况下的挑战是如何消除空中的强噪声和恢复建筑结构。如我们所见,时空滤波、VBM3D和BM4D仍然在平坦区域(如天空区域)留下一定的噪声。图8(b)(f)中所示的建筑结构,并没有通过VBM3D和BM4D得到很好的修复。这是因为,在存在结构噪声的情况下,无论是时空双边滤波器还是patch匹配都存在发现不匹配对应的风险,最终会导致不期望的结果。总的来说,光流、幸运成像的结果和我们的结果是相当的,我们的结果稍微干净一些。
肖像与小运动。这是在昏暗灯光下拍摄人像的典型场景。图9中的示例由JVC GC-PX10摄像机记录。时空滤波、幸运成像和光流法产生了眼睛周围的“阶梯”伪影(图9 (b)(c)(d))。这是因为主体的小的非刚性运动。VBM3D和BM4D没有这个问题,但是模糊了围巾上的细节(图9 (e)(f))。我们的结果在这两个地区都是最好的。

复杂场景的运动。图10和图11显示了两种情况复杂的动态场景。第一个例子是由带有ISO 6400的EOS 500D加农炮。噪音水平相对较低低。后来的例子是由诺基亚Lumia920获得的。作为我们可以从两个例子中看到,幸运成像和光流(+中值滤波)基于结果包含明显的重影VBM3D结果被过度平滑。BM4D比前两种方法,但仍然留下一定数量的色度噪声模式的背景。在我们的解中,我们可以自动选择与参考帧一致的像素颜色在动态区域上收集更多一致的像素点静态区域(如布和门)。结果,我们的结果令人震惊最好的平衡消除噪音,重建细节,避免重影。
4.2 More Results

运动模糊处理。在捕捉过程中,一些单独的帧(例如,10% ~ 30%的总帧)可能由于相机的突然抖动或物体的运动而变得模糊。图12显示了用iPhone 5S捕获的这样一个示例。我们研究了如果选择一个模糊的框架作为参考框架会发生什么。为了了解这一点,我们分别选择框架4 (sharp)和框架5 (blurry)作为参考框架,并生成两个结果。图12 (b)和(d)显示我们的方法对选择不敏感。这是因为我们的方法能够从大多数帧中找到一致的像素。在视频去模糊中也提出了类似的方法[Cho]等人[2012],他们在锐帧上发现了类似的去模糊补丁。
处理极低的光线。图13是iPhone 4S在极低光照条件下拍摄的序列。由于输入极暗,我们通过增压对输入进行预处理亮度(应用阴影/高光调整)。虽然升压后的噪声非常强,但我们的方法仍然成功地生成了具有精细细节的干净图像(空气中的细线和左边的钢塔)。
处理大遮挡。图14显示了一个具有快速移动的大前景(person)的序列。图中一致的像素映射揭示了我们的算法如何能够可靠地处理(快速)大遮挡。
4.3 Time Complexity
我们在拥有16G RAM的Intel i5 3.2GHZ机器上运行我们的方法。我们未经优化的c++实现(单核,没有SSE SIMD加速)平均需要920ms来处理10帧5Mpixel图像。具体来说,我们的方法采用82ms, 177ms, 51ms, 30ms, 253ms, 328ms来构建金字塔,提取和匹配稀疏特征,估计单应性流,选择一致的像素点,进行时间融合,并执行多尺度融合。我们在智能手机(诺基亚Lumia 920)上的原型平均花费约4.7秒,不使用多核或NEON指令或GPU加速。由于我们的解决方案主要基于点向操作,我们预计它可以显著加快。表1进一步展示了图8、9、10和11在同一台机器上不同方法的处理时间。
5. Concluding Remarks
在突发图像中,我们期望相机的运动来自于主体的握手和小/中等的运动。我们的方法不是设计来处理剧烈的运动(例如,在体育运动中),或去噪一般的视频。当我们的单应性流不能很好地表示两帧之间的运动时,如场景转换或快速摄像机平移,甚至非刚性变形(如水波运动、旗帜飘扬),我们的方法就会中断。
此外,有两种情况下,我们一致的像素选择可能会失败。第一种情况是由动态对象引起的运动模糊出现在大多数帧上(超过所有帧的一半)。在动态区域,我们的像素选择会自动选择基于参考帧的策略。如果参照帧包含模糊,我们的结果将保留模糊效果。但是如果选择一个锐利的框架作为参考,这个问题是可以避免的。图15 (a)显示了这样一个例子。因此,我们需要一个更好的选择参考系的策略。此外,快速移动的物体将自动删除的中值为基础的策略,积极去噪。为了避免这个问题,我们可以提供另一个选项,允许用户选择参考帧并约束像素选择的参考区域。
第二种情况是不同的移动对象和背景可能在相同的像素位置有相似的颜色。我们的像素选择算法依赖于每像素的色差,色差太弱,无法区分这类对象。图15 (b)显示了一个示例。不同移动的人有非常相似的颜色区域,这种模糊区域(高亮框表示)出现在大多数帧(即,超过所有帧的一半)。最后,它会导致重影,因为我们的选择错误地把它作为背景。这个问题也出现在无伪影的HDR重建[Granados et al. 2013]中,它需要相互作用来排除这些模糊区域。
尽管有上述问题,我们相信我们的高效解决方案是足够的实际部署,以改善用户在广泛的照明条件下的照片体验。
