Tortoise ORM 是异步的ORM,设计灵感来自 Django,官网:https://tortoise.github.io/
Tortoise ORM 目前支持以下数据库 :
1、PostgreSQL >= 9.4,使用asyncpg
2、SQLite,使用aiosqlite
3、MySQL/MariaDB,使用aiomysql或asyncmy
此时的最新版本:0.17.6
要求:python版本 >= 3.7
安装:pip install tortoise-orm

使用示例:
定义模型:需从tortoise引入Model类,然后所有模型都继承于Model即可,然后引入fields,fields模块提供了非常多的数据类型提供使用
然后使用官方提供的 register_tortoise 绑定 sanic 的实例 app 即可
register_tortoise 支持的参数
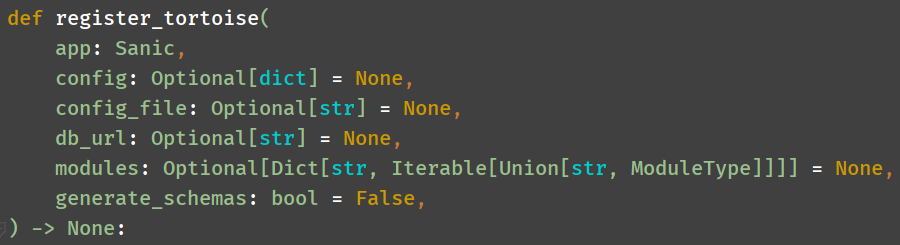
app: Sanic实例
config: 字典格式的配置
config_file: 配置文件路径
db_url: 数据库连接信息
modules: 字典的形式指定模型,可分组,指定模型所在的py文件,放在list中
generate_schemas: 为True则立即生成表信息
config示例:
{
'connections': {
# Dict format for connection
'default': {
'engine': 'tortoise.backends.asyncpg',
'credentials': {
'host': 'localhost',
'port': '5432',
'user': 'tortoise',
'password': 'qwerty123',
'database': 'test',
}
},
# Using a DB_URL string
'default': 'postgres://postgres:qwerty123@localhost:5432/events'
},
'apps': {
'user_info': {
'models': ['user', 'role'],
'default_connection': 'default',
},
'job_info': {
'models': ['project', 'job'],
'default_connection': 'default',
}
}
}
这里需要注意的是,models参数,支持用模型分组
第一种,只定义一个模型分组,名字是models,对应的模型所在的位置list:project.py,user.py

运行即可生成数据表

第二种,模型可以分组,当在模型映射关系的时候,需要使用 分组名.模型(详见后续文章)

user.py
from tortoise import Model, fields
class Users(Model):
id = fields.IntField(pk=True)
name = fields.CharField(50)
project.py
from tortoise import Model, fields
class Project(Model):
id = fields.BigIntField(pk=True)
name = fields.CharField(50)
task = fields.CharField(50)
main.py
from sanic import Sanic, response
from tortoise.contrib.sanic import register_tortoise
from user import Users
app = Sanic(__name__)
@app.route("/")
async def user_list(request):
users = await Users.all()
return response.json({"users": [str(user) for user in users]})
# # 第一种,只定义一个模型分组,名字是models,对应的模型所在的位置list:project.py,user.py
# register_tortoise(
# app,
# db_url="mysql://root:123456@localhost:3306/test?charset=utf8mb4", # MySQL
# # db_url="sqlite://db.sqlite3", # sqlite
# modules={"models": ["project", "user"]},
# generate_schemas=True # 启动时生成表
# )
# 第二种,根据模型的类型分组,各自指定自己对应的模型所在的位置list:project.py,user.py
register_tortoise(
app,
db_url="mysql://root:123456@localhost:3306/test?charset=utf8mb4", # MySQL
modules={
"user_info": ["user"],
"job_info": ["project"]
},
generate_schemas=True # 启动时生成表
)
if __name__ == '__main__':
import uvicorn
uvicorn.run('main:app', host='0.0.0.0', port=8000, debug=True)