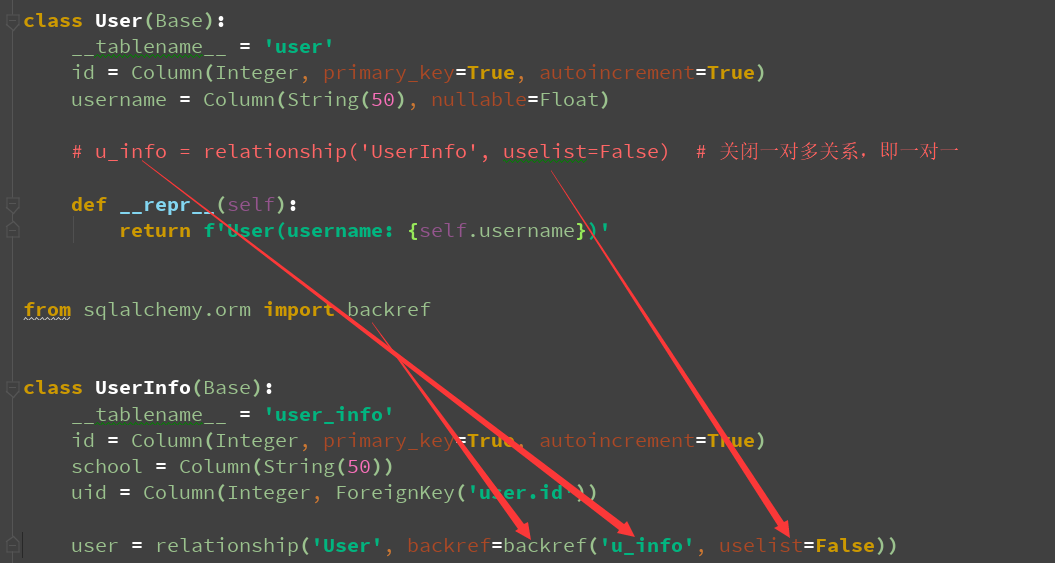
relationship()的uselist参数默认为True,即一对多,如果要一对一,则需让uselist=False
准备工作
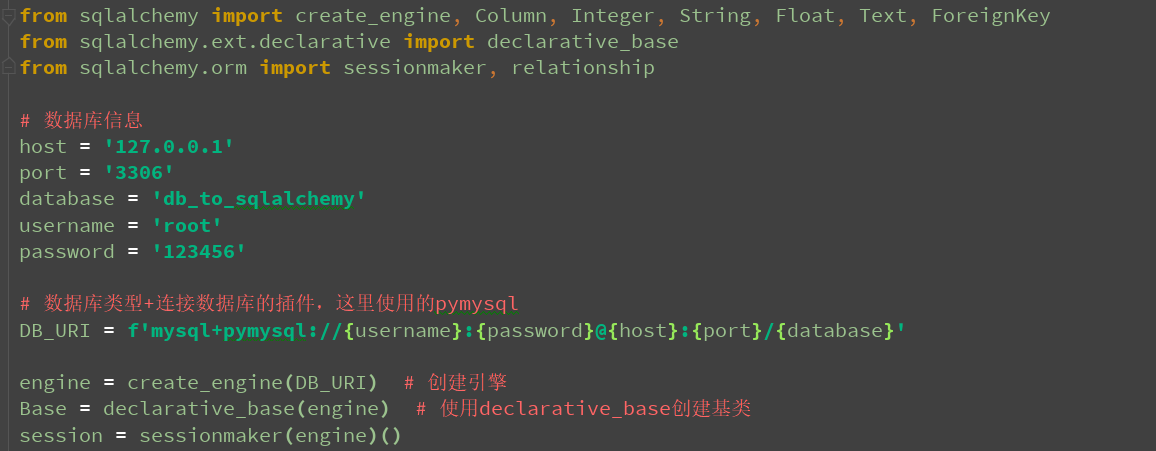
from sqlalchemy import create_engine, Column, Integer, String, Float, Text, ForeignKey
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker, relationship
# 数据库信息
host = '127.0.0.1'
port = '3306'
database = 'db_to_sqlalchemy'
username = 'root'
password = '123456'
# 数据库类型+连接数据库的插件,这里使用的pymysql
DB_URI = f'mysql+pymysql://{username}:{password}@{host}:{port}/{database}'
engine = create_engine(DB_URI) # 创建引擎
Base = declarative_base(engine) # 使用declarative_base创建基类
session = sessionmaker(engine)()
模型关系
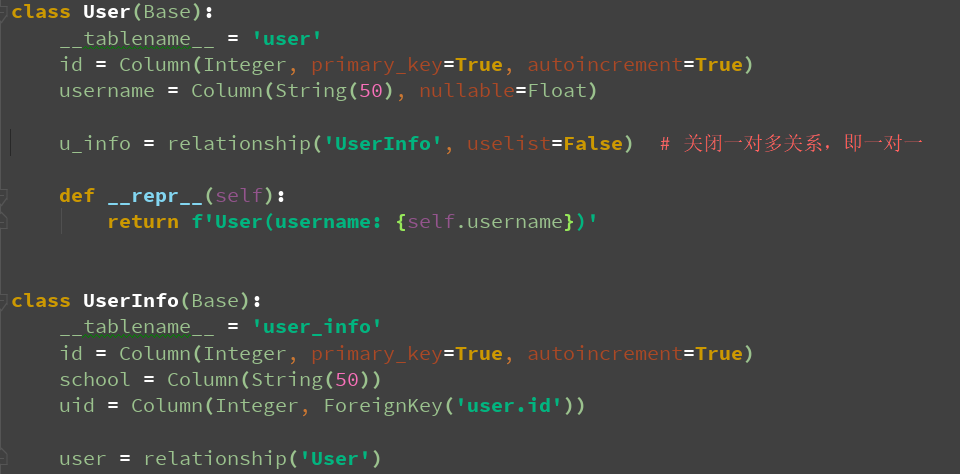
class User(Base):
__tablename__ = 'user'
id = Column(Integer, primary_key=True, autoincrement=True)
username = Column(String(50), nullable=Float)
u_info = relationship('UserInfo', uselist=False) # 关闭一对多关系,即一对一
def __repr__(self):
return f'User(username: {self.username})'
class UserInfo(Base):
__tablename__ = 'user_info'
id = Column(Integer, primary_key=True, autoincrement=True)
school = Column(String(50))
uid = Column(Integer, ForeignKey('user.id'))
user = relationship('User')

Base.metadata.drop_all() # 删除所有表
Base.metadata.create_all() # 创建表
user = User(username='abc')
info1 = UserInfo(school='xxxxx')
user.u_info = info1
session.add(user)
session.commit()
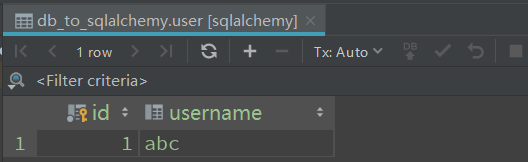
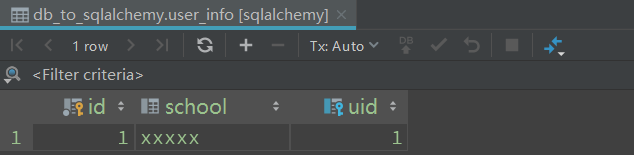
若采用一对多的关系则会报错
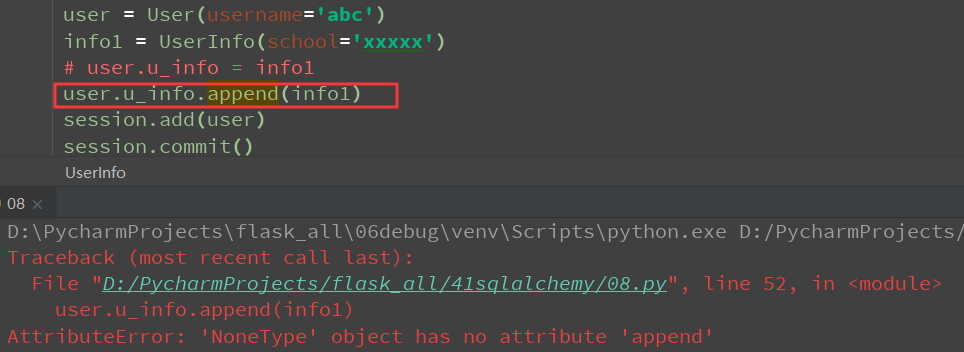
优化