博客转载自:https://leileiluoluo.com/posts/kdtree-algorithm-and-implementation.html
k-d tree算法原理及实现
k-d tree即k-dimensional tree,常用来作空间划分及近邻搜索,是二叉空间划分树的一个特例。通常,对于维度为k
,数据点数为N的数据集,k-d tree适用于N
的情形。
1)k-d tree算法原理
k-d tree是每个节点均为k维数值点的二叉树,其上的每个节点代表一个超平面,该超平面垂直于当前划分维度的坐标轴,并在该维度上将空间划分为两部分,一部分在其左子树,另一部分在其右子树。即若当前节点的划分维度为d,其左子树上所有点在d维的坐标值均小于当前值,右子树上所有点在d维的坐标值均大于等于当前值,本定义对其任意子节点均成立。
1.1)树的构建
一个平衡的k-d tree,其所有叶子节点到根节点的距离近似相等。但一个平衡的k-d tree对最近邻搜索、空间搜索等应用场景并非是最优的。
常规的k-d tree的构建过程为:循环依序取数据点的各维度来作为切分维度,取数据点在该维度的中值作为切分超平面,将中值左侧的数据点挂在其左子树,将中值右侧的数据点挂在其右子树。递归处理其子树,直至所有数据点挂载完毕。
a)切分维度选择优化
构建开始前,对比数据点在各维度的分布情况,数据点在某一维度坐标值的方差越大分布越分散,方差越小分布越集中。从方差大的维度开始切分可以取得很好的切分效果及平衡性。
b)中值选择优化
第一种,算法开始前,对原始数据点在所有维度进行一次排序,存储下来,然后在后续的中值选择中,无须每次都对其子集进行排序,提升了性能。
第二种,从原始数据点中随机选择固定数目的点,然后对其进行排序,每次从这些样本点中取中值,来作为分割超平面。该方式在实践中被证明可以取得很好性能及很好的平衡性。
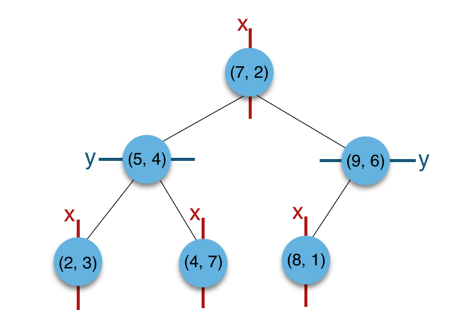
本文采用常规的构建方式,以二维平面点(x,y
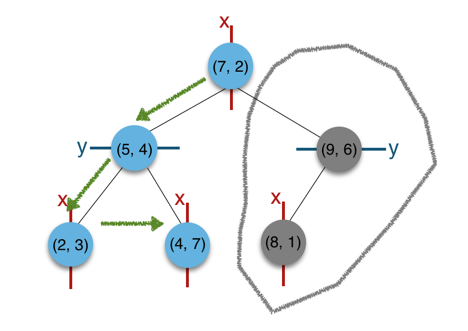
的集合(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)为例结合下图来说明k-d tree的构建过程。
a) 构建根节点时,此时的切分维度为x
,如上点集合在x
维从小到大排序为(2,3),(4,7),(5,4),(7,2),(8,1),(9,6);其中值为(7,2)。(注:2,4,5,7,8,9在数学中的中值为(5 + 7)/2=6,但因该算法的中值需在点集合之内,所以本文中值计算用的是len(points)//2=3, points[3]=(7,2))
b) (2,3),(4,7),(5,4)挂在(7,2)节点的左子树,(8,1),(9,6)挂在(7,2)节点的右子树。
c) 构建(7,2)节点的左子树时,点集合(2,3),(4,7),(5,4)此时的切分维度为y
,中值为(5,4)作为分割平面,(2,3)挂在其左子树,(4,7)挂在其右子树。
d) 构建(7,2)节点的右子树时,点集合(8,1),(9,6)此时的切分维度也为y
,中值为(9,6)作为分割平面,(8,1)挂在其左子树。至此k-d tree构建完成。
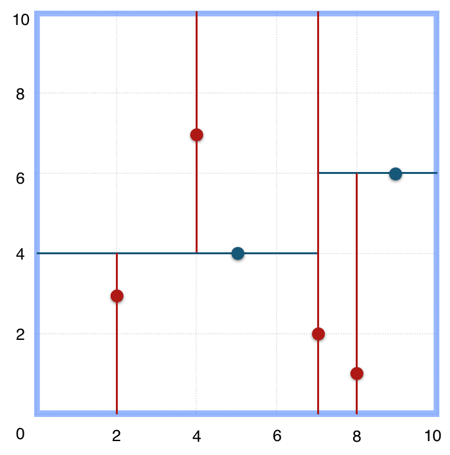
上述的构建过程结合下图可以看出,构建一个k-d tree即是将一个二维平面逐步划分的过程。
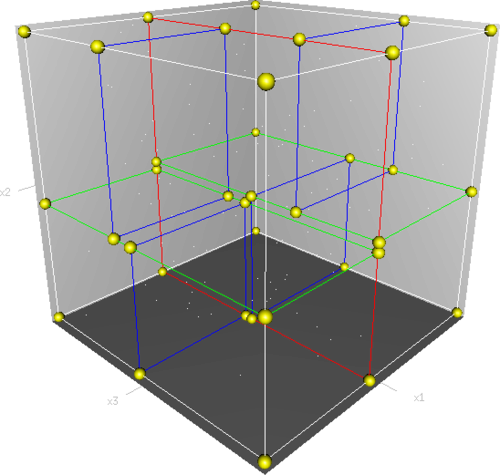
我们还可以结合下图(该图引自维基百科),从三维空间来看一下k-d tree的构建及空间划分过程。
首先,边框为红色的竖直平面将整个空间划分为两部分,此两部分又分别被边框为绿色的水平平面划分为上下两部分。最后此4个子空间又分别被边框为蓝色的竖直平面分割为两部分,变为8个子空间,此8个子空间即为叶子节点。
如下为k-d tree的构建代码:
def kd_tree(points, depth):
if 0 == len(points):
return None
cutting_dim = depth % len(points[0])
medium_index = len(points) // 2
points.sort(key=itemgetter(cutting_dim))
node = Node(points[medium_index])
node.left = kd_tree(points[:medium_index], depth + 1)
node.right = kd_tree(points[medium_index + 1:], depth + 1)
return node
1.2)寻找d维最小坐标值点
a)若当前节点的切分维度是d
因其右子树节点均大于等于当前节点在d维的坐标值,所以可以忽略其右子树,仅在其左子树进行搜索。若无左子树,当前节点即是最小坐标值节点。
b)若当前节点的切分维度不是d
需在其左子树与右子树分别进行递归搜索。
如下为寻找d维最小坐标值点代码:
def findmin(n, depth, cutting_dim, min):
if min is None:
min = n.location
if n is None:
return min
current_cutting_dim = depth % len(min)
if n.location[cutting_dim] < min[cutting_dim]:
min = n.location
if cutting_dim == current_cutting_dim:
return findmin(n.left, depth + 1, cutting_dim, min)
else:
leftmin = findmin(n.left, depth + 1, cutting_dim, min)
rightmin = findmin(n.right, depth + 1, cutting_dim, min)
if leftmin[cutting_dim] > rightmin[cutting_dim]:
return rightmin
else:
return leftmin
1.3)新增节点
从根节点出发,若待插入节点在当前节点切分维度的坐标值小于当前节点在该维度的坐标值时,在其左子树插入;若大于等于当前节点在该维度的坐标值时,在其右子树插入。递归遍历,直至叶子节点。
如下为新增节点代码:
def insert(n, point, depth):
if n is None:
return Node(point)
cutting_dim = depth % len(point)
if point[cutting_dim] < n.location[cutting_dim]:
if n.left is None:
n.left = Node(point)
else:
insert(n.left, point, depth + 1)
else:
if n.right is None:
n.right = Node(point)
else:
insert(n.right, point, depth + 1)
多次新增节点可能引起树的不平衡。不平衡性超过某一阈值时,需进行再平衡。
1.4)删除节点
最简单的方法是将待删节点的所有子节点组成一个新的集合,然后对其进行重新构建。将构建好的子树挂载到被删节点即可。此方法性能不佳,下面考虑优化后的算法。
假设待删节点T的切分维度为x,下面根据待删节点的几类不同情形进行考虑。
a)无子树
本身为叶子节点,直接删除。
b)有右子树
在T.right寻找x切分维度最小的节点p,然后替换被删节点T;递归处理删除节点p。
c)无右子树有左子树
在T.left寻找x切分维度最小的节点p,即p=findmin(T.left, cutting-dim=x),然后用节点p替换被删节点T;将原T.left作为p.right;递归处理删除节点p。
(之所以未采用findmax(T.left, cutting-dim=x)节点来替换被删节点,是由于原被删节点的左子树节点存在x维度最大值相等的情形,这样就破坏了左子树在x分割维度的坐标需小于其根节点的定义)
如下为删除节点代码:
def delete(n, point, depth):
cutting_dim = depth % len(point)
if n.location == point:
if n.right is not None:
n.location = findmin(n.right, depth + 1, cutting_dim, None)
delete(n.right, n.location, depth + 1)
elif n.left is not None:
n.location = findmin(n.left, depth + 1)
delete(n.left, n.location, depth + 1)
n.right = n.left
n.left = None
else:
n = None
else:
if point[cutting_dim] < n.location[cutting_dim]:
delete(n.left, point, depth + 1)
else:
delete(n.right, point, depth + 1)
2)最近邻搜索
给定点p,查询数据集中与其距离最近点的过程即为最近邻搜索。
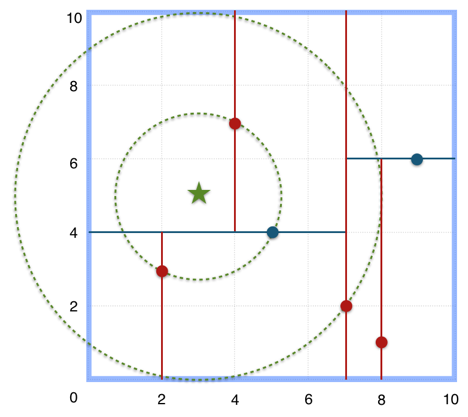
如在上文构建好的k-d tree上搜索(3,5)的最近邻时,本文结合如下左右两图对二维空间的最近邻搜索过程作分析。
a) 首先从根节点(7,2)出发,将当前最近邻设为(7,2),对该k-d tree作深度优先遍历。以(3,5)为圆心,其到(7,2)的距离为半径画圆(多维空间为超球面),可以看出(8,1)右侧的区域与该圆不相交,所以(8,1)的右子树全部忽略。
b) 接着走到(7,2)左子树根节点(5,4),与原最近邻对比距离后,更新当前最近邻为(5,4)。以(3,5)为圆心,其到(5,4)的距离为半径画圆,发现(7,2)右侧的区域与该圆不相交,忽略该侧所有节点,这样(7,2)的整个右子树被标记为已忽略。
c) 遍历完(5,4)的左右叶子节点,发现与当前最优距离相等,不更新最近邻。所以(3,5)的最近邻为(5,4)。
如下为最近邻搜索代码:
3)复杂度分析
操作 平均复杂度 最坏复杂度
新增节点 O(logn) O(n)
删除节点 O(logn) O(n)
最近邻搜索 O(logn) O(n)
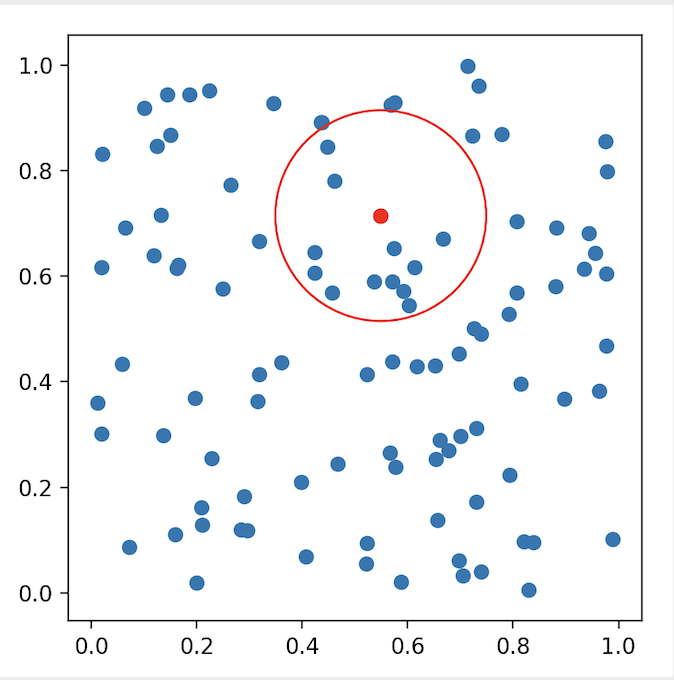
4)scikit-learn使用
scikit-learn是一个实用的机器学习类库,其有KDTree的实现。如下例子为直观展示,仅构建了一个二维空间的k-d tree,然后对其作k近邻搜索及指定半径的范围搜索。多维空间的检索,调用方式与此例相差无多。
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import numpy as np
from matplotlib import pyplot as plt
from matplotlib.patches import Circle
from sklearn.neighbors import KDTree
np.random.seed(0)
points = np.random.random((100, 2))
tree = KDTree(points)
point = points[0]
# kNN
dists, indices = tree.query([point], k=3)
print(dists, indices)
# query radius
indices = tree.query_radius([point], r=0.2)
print(indices)
fig = plt.figure()
ax = fig.add_subplot(111, aspect='equal')
ax.add_patch(Circle(point, 0.2, color='r', fill=False))
X, Y = [p[0] for p in points], [p[1] for p in points]
plt.scatter(X, Y)
plt.scatter([point[0]], [point[1]], c='r')
plt.show()