文章简要的讨论了in,exists 与 not in, not exists在使用中的问题,主要是关键字的选择,SQL的优化
*注:下面示例都是用Oracle内置用户的表,如果安装Oracle时没有选择不安装数据库示例表应该都会安装的
1、IN和EXISTS
IN语句:
SELECT * FROM hr.employees t1 WHERE t1.employee_id IN ( SELECT t2.employee_id FROM hr.job_history t2 );
EXISTS语句:
SELECT * FROM hr.employees t1 WHERE EXISTS ( SELECT 1 FROM hr.job_history t2 WHERE t2.employee_id = t1.employee_id );
可以看到两者的结果是一样的,这意味着两个查询都能够满足我们业务的需求。但是问题来了,那个以查询更快呢?
用in和exists都可以实现对数据的选择,但是两者的效率往往会因为场景不同而不同。原因如下:
in是把主表和子查询的表作hash连接;而exists是对主表作loop循环,每次loop循环再对内表进行查询。所以我们一直以来认为exists比in效率高的说法是不准确的。如果查询的两个表大小相当,那么用in和exists差别不大;如果两个表中一个较小一个较大,则子查询表大的用exists,子查询表小的用in;
即:表A(小表),表B(大表)
select * from A where cc in(select cc from B) -->效率低,用到了A表上cc列的索引; select * from A where exists(select cc from B where cc=A.cc) -->效率高,用到了B表上cc列的索引。
相反的:
select * from B where cc in(select cc from A) -->效率高,用到了B表上cc列的索引 select * from B where exists(select cc from A where cc=B.cc) -->效率低,用到了A表上cc列的索引。
2、NOT IN和NOT EXISTS
NOT IN语句:
SELECT * FROM HR.EMPLOYEES T1 WHERE T1.EMPLOYEE_ID NOT IN ( SELECT T2.EMPLOYEE_ID FROM HR.JOB_HISTORY T2 );
NOT EXISTS语句:
SELECT * FROM HR.EMPLOYEES T1 WHERE NOT EXISTS ( SELECT 1 FROM HR.JOB_HISTORY T2 WHERE T2.EMPLOYEE_ID = T1.EMPLOYEE_ID );
not in,not exists的对比与in,exists有比较大的不同,原因在于:
如果查询语句使用了not in,那么对主表,子查询表都进行全表扫描,没有用到索引;而not exists的子查询依然能用到表上的索引。所以无论哪个表大,用not exists都比not in 要快。
而且坑爹的事情还没有这么快就结束!
再演示一个比较坑爹的事情
--构造临时表tmp1 WITH tmp1 AS ( SELECT 1 AS field1,2 AS field2 FROM dual UNION ALL SELECT 1 AS field1,3 AS field2 FROM dual ),--多个with as用逗号隔开 --构造临时表tmp2 tmp2 AS ( SELECT 1 AS field1,2 AS field2 FROM dual UNION ALL SELECT 1 AS field1,NULL AS field2 FROM dual ) SELECT * FROM tmp1 t1 WHERE NOT EXISTS ( SELECT 1 FROM tmp2 t2 WHERE t1.field2 = t2.field2 );
结果如下:
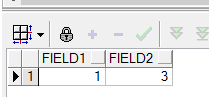
没有什么异常,但是用 not in的话坑爹的事情就会出现了!
--构造临时表tmp1 WITH tmp1 AS ( SELECT 1 AS field1,2 AS field2 FROM dual UNION ALL SELECT 1 AS field1,3 AS field2 FROM dual ),--多个with as用逗号隔开 --构造临时表tmp2 tmp2 AS ( SELECT 1 AS field1,2 AS field2 FROM dual UNION ALL SELECT 1 AS field1,NULL AS field2 FROM dual ) SELECT * FROM tmp1 t1 WHERE t1.field2 NOT IN ( SELECT t2.field2 FROM tmp2 t2 );
结果如下:

WTF!!!!!!!
为什么会不同??????
原来使用not in时,它会调用子查询;而使用not exists时,它会调用关联子查询。如果子查询中返回的任意一条记录含有空值,则查询将不返回任何记录。这就是导致我们上述问题的原因,所以一般情况下,我们都会用not exists而不用not in