https://zhuanlan.zhihu.com/p/161007340
应用下载地址
Elasricsearch版本:6.3.2 ,下载地址:https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.3.2.zip
Kibana版本:6.3.2 ,下载地址:https://artifacts.elastic.co/downloads/kibana/kibana-6.3.2-linux-x86_64.tar.gz
FileBeat版本6.3.2,下载地址:https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.3.2-darwin-x86_64.tar.gz
FileBeat比logstash更轻量级,这里以filebeat收集Java应用日志为例;
★★★★★:es6.3.2需要分配用户,不能使用root启动,同时,安装过程中会遇到各种各样的问题,一点点解决吧;
启动方式:
1、Elasticsearch
./bin/elasticsearch -d # 后台启动
2、kibana
nohup ./bin/kibana & # 后台启动
关闭kibana使用 netstat -tunlp|grep 5601 然后kill pid
如:tcp 0 0 0.0.0.0:5601 0.0.0.0:* LISTEN 13082/./bin/../node
pid为 13082
3、filebeat
nohup ./filebeat -e -c filebeat-01.yml -d "Publish" & > nohup.out # 后台启动
关闭 kill pid
ElasticSearch配置文件elasticsearch.yml
cluster.name: ard-es # 集群中的名称
node.name: master-node # 该节点名称
node.master: true # 意思是该节点为主节点
node.data: false # 表示这是数据节点
discovery.zen.ping.unicast.hosts: ["192.168.1.1", "192.168.1.2", "192.168.1.3"] # 配置自动发现
http.cors.enabled: true # sticsearch中启用CORS
http.cors.allow-origin: "*"
xpack.security.enabled: True
xpack.ml.enabled: true
network.host: 0.0.0.0
http.port: 9200
# 在这里我做了三台集群,另外两台的配置文件
node.name: node-data-01/02
node.master: false # 意思是该节点为主节点
node.data: true # 表示这是数据节点
# 一主两从,主节点不作为数据节点
Kibana配置文件kibana.yml
server.port: 5601 # 配置kibana的端口
server.host: "0.0.0.0"
elasticsearch.url: "http://127.0.0.1:9200" # 配置es服务器的ip,如果是集群则配置该集群中主节点的ip
logging.dest: /data/ELK6.3.0/kibana-6.3.2-linux-x86_64/logs/kibana.log # 配置kibana的日志文件路径,不然默认是messages里记录日志
filebeat配置文件filebeat.yml
#最头疼的就是filebeat的配置文件了,也遇到了各种各样的问题,配置文件如下:
# 是否开启自定义字段作为顶级字段存储到文档中,如果自定义字段名称与其他字段名称冲突,则自定义字段将覆盖其他字段
fields_under_root: true
# 自定义字段(我这里是定义的当前应用的ip地址,用于应用多节点部署时,明确日志输入来源,尝试过修改beat.name和hostname,均以失败告终)
fields:
applyIp: 192.168.1.2
filebeat.inputs:
- type: log # 日志输入类型,文件日志以log标记
paths:
- /htdocs/my-base/logs/my-base.log # 日志在服务器的绝对位置
fields:
type: my-base # 相当于标签的意思,在这里给打一个标签,在输入到ES的时候可以用来区分输送的ES索引
tail_files: true # 配置为true时,filebeat将从新文件的最后位置开始读取
#指定正则表达式去匹配指定的行,例如multiline.pattern: '^[',意思是去匹配以[开头的行,下面的正则是 以日期开头的、以空格开头的、以Caused by开头的、以INFO开头的等.....
#下面这正则有很多问题,关于多行日志这一块,参考了很多的文章,目前项目中的那种打印的json串多行的,filebeat还没解决
multiline.pattern: '^[[0-9]{4}-[0-9]{2}-[0-9]{2}|^[[:space:]]|^Caused by:|^INFO|^at'
#定义pattern是否被否认,默认值是false,若为true,意思是对上面的匹配进行反转(就是实际去匹配不以pattern的行)
multiline.negate: false
# 将上面的匹配条件的(或者是不匹配的,取决上面是true还是false) 结果,是放到行首 还是放到行位 after和before
multiline.match: after
- type: log
paths:
- /htdocs/my-gateway/logs/my-gateway.log
fields:
type: my-gateway
tail_files: true
multiline.pattern: '^[[0-9]{4}-[0-9]{2}-[0-9]{2}|^[[:space:]]|^Caused by:|^INFO|^at'
multiline.negate: false
multiline.match: after
#-------------------------- Elasticsearchbled output ------------------------------
output.elasticsearch:
hosts: ["192.168.1.1:9200"] # 指定es服务器的ip端口
indices:
- index: "my-gateway" # es索引
when.equals:
fields.type: "my-gateway" # filebeat中的标签 区分索引
- index: "my-base"
when.equals:
fields.type: "my-base"
#============================= Filebeat modules ===============================
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
#==================== Elasticsearch template setting ==========================
setup.template.settings:
index.number_of_shards: 5
index.number_of_replicas: 1
index.codec: best_compression
在filebeat的配置文件中,遇到的问题比较多,并且都还没有解决,不过不影响ELK的使用;
1、多行日志问题
异常日志目前已经解决完毕,不过json串输出的多行日志这种还是没有得到解决
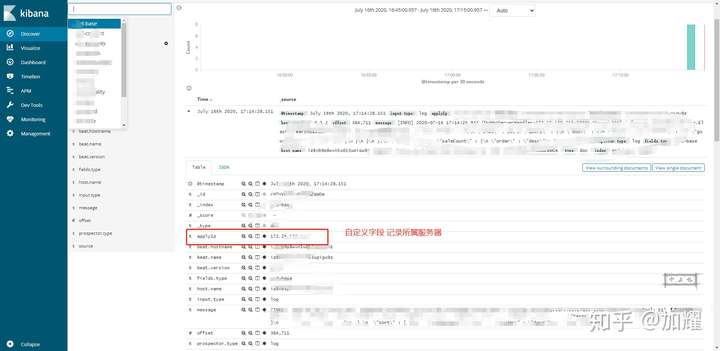
2、记录日志所属服务器
在文档中说的修改beat.name和beat.hostname,尝试了各种写法,目前还是没有得到解决;最后是使用的自定义字段来解决的这个问题;
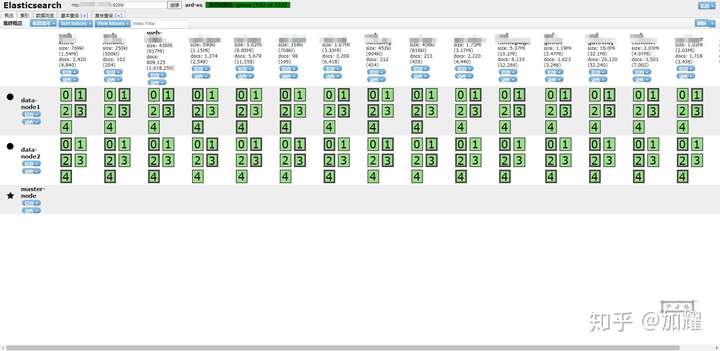
看看最终的成效
发布于 07-16