先上结论。
功能上:druid sql parser(支持分区、WITH、DUAL等。使用mysql语法解析时,已知oracle的一些操作符会被转为mysql,如|| 转为OR。使用oracle解析器时,union all里面的括号会被移到外面,从而导致可能执行出错) > jsqlparser(不支持分区及((id)) in ((?))) > fdb-sql-parser(不支持很复杂的SQL)。因此,首先排除fdb-sql-parser。都不支持不执行SQL语句解析语义,可通过调用preparestatement达到目标(我们就是这么做的),不是问题。
-- druid能解析、jsqlparser解析不了 SELECT * FROM ( SELECT * FROM biz_fund_info WHERE tenant_code = ? AND ( (ta_code, manager_code) IN ((?,?)) OR department_type IN (?) ) )
易用性:jsqlparser > druid sql parser(文档和javadoc实在TMD懒了)。就druid sql parser和jsqlparser而言,核心只要理解访问者模式,其中核心又为com.alibaba.druid.sql.dialect.mysql.visitor.MySqlOutputVisitor#visit及其父类,使用例子可以参见https://www.jianshu.com/p/3fb67691d3c8。
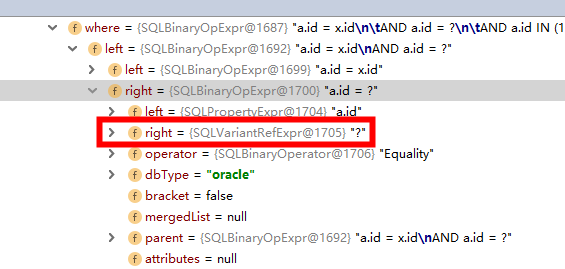
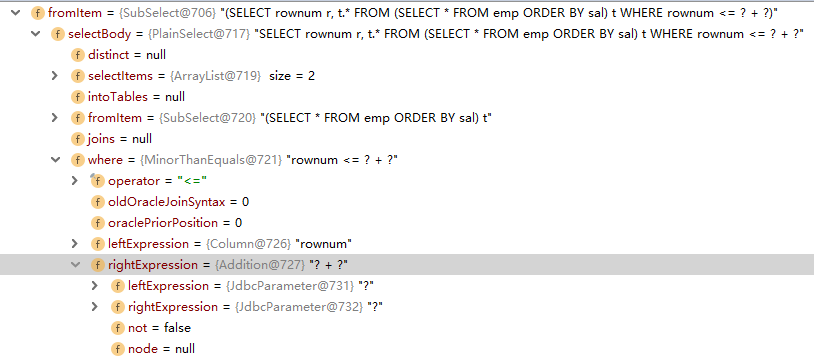
可见差异不要太大,如果两个都上的话,不能说不行,其实成本有点高(不过LZ确实两个都广泛在框架里使用了,主要是jsqlparser先上的,一下子也没时间完全重构,而且druid sql parser也有一些实现不合理的地方,比如子查询的toString并不是原sql的子集,多了额外的 或 )。
所以,如果需要广泛使用,可考虑优先选择druid sql parser而不是jsqlparser。
注:除了自己写过滤器外,druid也支持sql注入过滤器,可参考:https://my.oschina.net/yysue/blog/1618558,https://www.oschina.net/question/928524_106630
druid sql parser的官方文档:https://github.com/alibaba/druid/wiki/SQL-Parser。后续补充实战手册,我们在分布式查询引擎的重写、分库分表合并、用户名映射、基于sql自动生成智能的查询页面都是基于druid扩展实现的(一开始用jsqlparser,但是在解析方面相比druid sql parser偏弱,后面大部分用druid重写了)。
jsqlparser官方文档:http://jsqlparser.sourceforge.net/example.php
最后,这俩都是通过自己从头到尾解析实现AST,sharding-jdbc采用的是antlr实现的(其实就是分库分表中间件来说,借助jsqlparser和druid也差不多了,重点本身是merge和pushdown重写,并非解析)。
除了这两个主流的外,还有一个apache calcite,LZ没有研究过,可见https://www.cnblogs.com/zhihuifan10/p/11124724.html。