原文:http://cos.name/2015/08/some-basic-ideas-and-methods-of-model-selection/
作者:高涛 编辑:王小宁
0. 引言
有监督学习是日常使用最多的建模范式,它有许多更具体的名字,比如预测模型、回归模型、分类模型或者分类器。这些名字或来源统计,或来源于机器学习。关于统计学习与机器学习的区别已经有不少讨论,不少人认为机器学习侧重于目标预测,而统计学习侧重于机制理解和建模。个人更加直观的理解是,统计学习侧重于从概率分布来描述数据生成机制,除了预测之外,还关心结果(参数假设、误差分布假设)的检验,而机器学习侧重于从函数拟合角度来描述数据生成机制,基本目的就是为了拟合和预测,缺乏严谨的参数、误差的检验机制,比如下式:
1. 统计学习目标是获取Pr(Y|X)Pr(Y|X)的条件分布,通过对数据概率生成机制的理解与建模进而获取良好的预测效果,这个过程会涉及X,Y,ϵX,Y,ϵ的分布假设,因此最后会衍生出对参数假设和误差分布的假设检验,以验证整个概率分布的假设的正确性,比如经典的线性模型、非参数回归等模型,预测能力并不是其主要目的;
2. 而机器学习基本不会从概率分布的角度着手,虽然可能也会涉及X,YX,Y的分布假设,但目的就是学习到一个能够较好描述数据生成机制的函数ff,对误差的假设基本忽略,也不会涉及参数和误差的检验,模型好坏基本由预测效果来判断,同时也会提供一些比较一般的误差上界,所以机器学习中不会出现参数估计渐进性、一致性等结果的讨论,而多半最终结果的评判。比如SVM、神经网络、KNN等模型。
不过即使有上述区别,关于高维统计推断(Lasso类带正则项的线性模型)的理论也逐渐完善,但相对于传统的生物制药、生物实验、社会调查、经济分析等领域,当前图像、文本、推荐系统等应用领域中,人们更关心模型的预测能力,而不是解释能力甚至是模型的可靠性,主要原因即这些领域模型预测能力相比于模型的假设检验要重要得多,因此如何根据模型预测能力来选择最优模型变得越来越重要。本文下面就逐步介绍模型选择的思路和方法,主要参考ELS这本书。
1. 偏移、方差、复杂度和模型选择
模型的预测能力通常也被称作模型的泛化能力,表示模型在新的、独立的测试数据上的预测能力。在很多关于模型泛化能力的介绍中,我们总会看到这样一幅图:模型在训练集上的训练误差与在测试集上的测试误差的变化趋势对比。
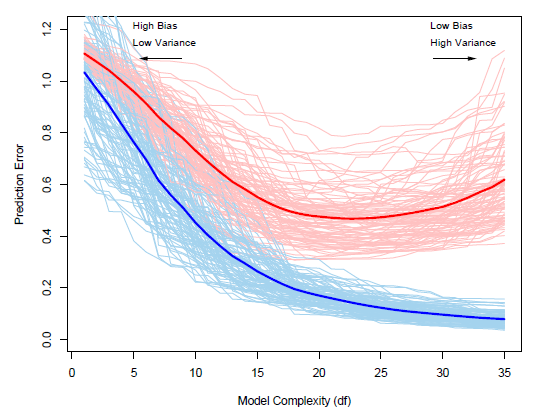 图上横轴表示模型的复杂度大小(比如线性模型中特征维度大小),纵轴表示预测误差,衡量预测值与真实值间的平均损失大小E(L(Y,f^(X)))E(L(Y,f^(X))),损失函数根据分类、回归问题做合适的选择,比如0-1损失、负似然函数、平方损失、对数损失、指数损失、交叉熵损失、Hinge损失等。平均损失大小在训练集上预测误差称作训练误差,在测试集上称作测试误差。图中每一条线都表示同一个训练集(浅蓝色)和测试集(浅红色)上的预测误差表现,从图上可以看到两个现象
图上横轴表示模型的复杂度大小(比如线性模型中特征维度大小),纵轴表示预测误差,衡量预测值与真实值间的平均损失大小E(L(Y,f^(X)))E(L(Y,f^(X))),损失函数根据分类、回归问题做合适的选择,比如0-1损失、负似然函数、平方损失、对数损失、指数损失、交叉熵损失、Hinge损失等。平均损失大小在训练集上预测误差称作训练误差,在测试集上称作测试误差。图中每一条线都表示同一个训练集(浅蓝色)和测试集(浅红色)上的预测误差表现,从图上可以看到两个现象
- 训练误差(浅蓝色)和测试误差(浅红色)都有波动,并不是一个稳定的值,并且随着模型复杂度的增加,训练误差(浅蓝色)波动越来越小,而测试误差(浅红色)波动则越来越大;
- 随着模型复杂度增加,训练误差(浅蓝色)和平均训练误差(粗蓝线)越来越小,但测试误差(浅红色)和平均测试误差(粗红线)先降低后减小,在相对中间的位置有一个最小值。
看到这上面的现象,我们的脑中可能会冒出下面几个问题:
- 为什么训练误差和测试误差会有波动?
- 训练误差和测试误差的变化趋势说明了什么问题?
- 造成这种变化趋势的原因是什么?
- 这种趋势对模型的选择和评价有什么指导意义?
这四个问题由浅入深,最终目的就是想获取泛化能力最好和最稳定的预测模型。在回答这四个问题前,我们首先需要做一个假设:模型能够较好的预测,说明预测集与训练集有较好的相似性,更严格来说,很可能来源于同一分布,下文做分析时均假设来源于统一总体分布。如果测试集相对于训练集发生了巨大的变化,那么从训练到预测的思路将不可行。下面我们逐步来解答这四个问题。
1.1 为什么训练误差和测试误差会有波动?
现假设我们有个研究项目,想根据学生的平时表现和性格的pp个指标XX来预测最终该学生的期末综合成绩YY。为达到这个目的,我们在一个学校中我们随机抽了一批学生,选用某个模型训练,估计其模型参数,然后找一批新的学生预测来评价模型好坏,发现预测误差的相对误差非常小。但是通常人们会问,这个模型预测能力真的那么好么?我咋不相信根据学生平时表现和性格就可以得到这么好的预测效果呢?是不是你们特意挑选的一批学生呐?为了让他们相信这个模型还不赖,我们从这个学校重新抽了好几批学生,分别根据这些学生的指标去训练模型和估计模型参数。随后我们发现,换了几批学生样本,估计的模型参数确实有些差别,而且预测效果也是时好时坏,整体而言,平均的预测误差也还差强人意,能够控制预测误差的相对误差在20%以内,此时再把结果拿给其他人看,估计很多人对你的模型可能就不会有那么大疑问了。
对应到上文的图,其实上图的波动产生的原因也和该例子操作是一样的,有多条线就意味着重复抽了多组训练集来分别训练,因此训练误差和测试误差的波动是由训练样本的变化带来的。在理想的实验条件下,为了能公正地衡量模型的预测能力,通常需要多换几组训练集和测试集来综合评价模型的预测能力,这样的结果才可能让人更信服模型的预测能力,而不是偶然结果。
但是实际情况中,我们却可能仅有一个训练集和一个测试集。用数学化语言描述,新的测试集中,目标变量Y0Y0和预测变量X0X0均从两者的联合分布中抽取,独立于训练集T=(X,Y)T=(X,Y),此时我们获取的测试误差(泛化误差)为某个训练集TT上测试集上损失的条件期望
这里训练集TT是固定的,即仅有一个训练集。而从统计分析(重复试验)上来说,我们可能更关注测试误差的期望,即去掉训练集随机性所带来的影响:
这个目标即上图预测误差波动想要表达的含义,想要通过多个训练集训练来获取平均的预测误差,抹平训练集变动带来的影响,这是评价模型预测能力最理想方法,可以防止某个训练集上训练所得模型表现过好而夸大模型的预测能力。但是实际情况中,我们手边通常可能只有一个训练集,实际的需求是在此训练集上模型做到最好,所以ErrTErrT又是我们最关心的目标,即希望在当前训练集下获取最佳的预测能力,也就是说我们想获取上图的一条线的趋势中最小的测试误差的点,如下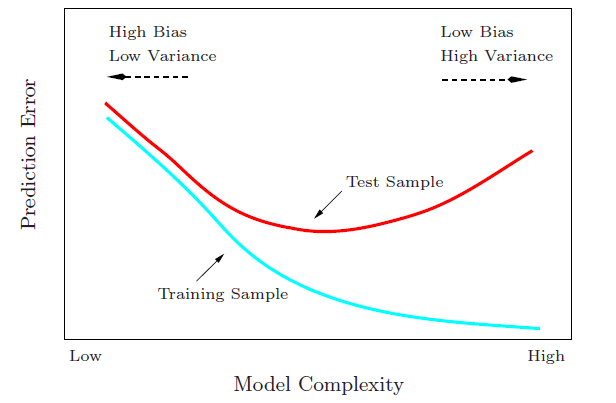
换句话说,很多时候人们给你一个训练集就希望你能够给他一个相对最稳定的预测模型,这个目标相对获取平均预测误差来说更难,后续模型选择方法比如CV法、bootstrap法、Cp法等其实都是估计测试误差的期望,即第一幅图中的红色均线。
1.2 训练误差和测试误差的变化趋势说明了什么问题?
图上反映的两个现象一句话表示即:随着模型复杂度增加,训练误差波动降低,平均训练误差降低趋向于0,而测试误差波动上升,平均测试误差先降低后升高。这个现象说明训练误差不能代替测试误差来作为模型选择和评价的手段。随着模型复杂度变化,训练误差与测试误差并不是一个良好的正相关关系,而是呈现较为复杂的非线性关系。用数学式子表示即
用更通俗的话说,复杂的模型可能在训练集上拟合的很好,但是面对新的测试集,预测误差不降反升,发生了所谓的“过拟合”现象。如果一个模型在不同的测试集上测试结果不仅波动性大,而且预测误差也比较大,就要警惕发生了过拟合现象,此时不妨将模型的复杂度降低些(关于模型的复杂度含义下文会做更细致的说明),即使用变量更少的简单模型,比如线性模型。
过拟合的原因有很多,其中一个很可能的原因是,随着模型复杂度升高,对于训练数据刻画的很细,但是训练数据中可能某些特征仅出现过一次或者很少,信息不足,而测试集中该特征却出现了很多其他的值,虽然模型在训练集上刻画的足够细致,但是由于测试集的变动,模型反而往测试机上的迁移性能下降,训练误差变化并不正比于测试误差。
1.3 造成预测误差变化趋势的原因是什么?
那究竟是什么原因导致了随着模型复杂度增加,训练误差与测试误差不呈现良好的正比关系呢?为何同样都是预测误差,训练误差很小的模型反而预测能力很差呢?下面我们以线性模型为例来阐释原因,假设
如果用线性函数fp(x)=xTβfp(x)=xTβ去近似f(x)f(x),其中pp表示特征个数,损失函数取平方损失,最小化1N∑i(yi–xTiβ)21N∑i(yi–xiTβ)2,则在训练集T=(X,Y)T=(X,Y)下得到参数估计为β^β^,同时记β∗β∗是f(x)f(x)最佳线性近似的估计参数
在某个新样本点X=x0X=x0处预测误差为
如果x0x0此时取所有训练集中的xixi,则其平均预测误差(该误差也被称作样本内(in-sample)误差,因为x0x0都是来自与训练样本内。不过y0y0都是新的观测,且真实的f(xi)f(xi)仍未知,因此该预测误差不是训练误差,后续会AIC等准则中会详细讲解):