代码仓库位于: Azure
可执行程序 (Windows .exe) 位于:可执行文件 (不是病毒)
合作方式
首先我们采用的程序语言是 C++,我们采用的平台是 Azure DevOps。 总体的合作方式是采用官僚式,即每个人都负责各自的一个功能,本次程序中一共有4个功能需要实现:字母占比、单词统计、词组统计、动词-介词统计,我负责字母占比、词组统计,舒曼莉负责单词统计、动词-介词统计。采用 git 来管理代码,每个功能个维护一个分支。主分支是一个程序并行流水线框架,定义了基本的API接口(实际上是一个基类),其他功能分支遵从主分支的基本框架,在这个基础上进行相应功能的开发测试,最后全部分支测试完毕后都合并到主分支中形成最终全功能版程序。
设计框架
项目框架设计
框架的总体流程是我提出的,决定采用并行流水线的原因也是因为这个程序的逻辑存在着明显的分离、并行空间。关于代码的风格,我们采用的 Google Style Guide,注释规范从用的是 Doxygen 注释规范,整体的源码框架遵循C++开源工程项目的规范(包括 src, include 等文件路径)。
代码框架设计
由于采用C++,而这些功能基本都围绕着一个中心主题:统计词频,所以我们采用的设计方式是:
- 通过建立一个基类,这个类提供了所有功能中可能用到的方法:如读取文件、分离单词、输出结果等,并定义了数据存储类型:对于动词表,存储在
std::unordered_map<std::string, std::string>中,介词、动词原形、停词表都存储在std::unordered_set<std::string>中,排序结果均存储在std::unordered_map<std::string, int>中。为了追求运行速度,所以以上的数据结构都采用哈希。这个框架定义在主分支中。 - 每个功能都有一个自己的类,并且都会继承这个主框架上的基类,以及在原有提供的方法上定义新的方法,或重载原有的方法,然后实现相应的功能。
代码优化
首先我们基于的是并行流水线的框架,一共有三个线程,分别负责:读取文件(IO), 文本分词(计算), 统计(访存),两个线程间采用生产者-消费者模型,所以一共有两组生产者-消费者,其中文本分词线程既担任第一个生产者-消费者模型中的消费者,又担任第二个生产者-消费者中的生产者。所以这里的一个优化主要针对于对锁的优化,我们希望线程持有锁的时间能尽量的短,这样并行的程度就能更大。所以一个重要的优化是我们将所有设计到计算的任务都放置于锁的外面,锁内只负责读取、存放相应的数据。
其次我们是对文本读取的优化,原先的代码在第一个线程读取文件的一个块时会判断是否都完整一个单词,即所读的最后一个字节是否是字母或数字,如果可能不是一个完整的单词,我们需要再读取一些字符来,直到是非字母且非数字的字符,才发送读取的块。然而我们发现,IO线程往往是整个程序的运行瓶颈,所以我们将判断是否为完整单词的这一部分放到文本分词的位置,即在这个线程中,我们维护一个缓冲区,如果发现最后一个获得的字节是字母或数字,那么我们只会先处理之前的单词,留下最后一个等待下一次的读入进行合并。这样我们程序的运行速度能比原来提高25%(粗略)。
其他还有些细节的优化,如一次读取块的大小,我们往往会取系统页大小的整数倍(即4K的倍数),防止出现低效的页置换。
可优化的部分
事实上这个程序还有很多可以优化的部分,有一个最重要的点是更细粒度的并行,这可以通过两点做到:第一个是使用更多的线程,维护一个优先队列表,这样可以不需要等到全部都统计完成后再进行排序,可以边统计边排序;同时还可以使用OpenMP 多线程库,来做到比如分词、排序的并行。
由于时间上的限制,我们并没有在这方面展开更多的优化。
优点和缺点
我的结对编程同伴是舒曼莉。
她的优点:
- 勤奋
- 对新工具的学习速度快
- 善于使用GUI界面
她的缺点:
- 对 git 命令不是很熟
性能分析
我们采用的性能分析工具为Visual Studio Performance Profiler
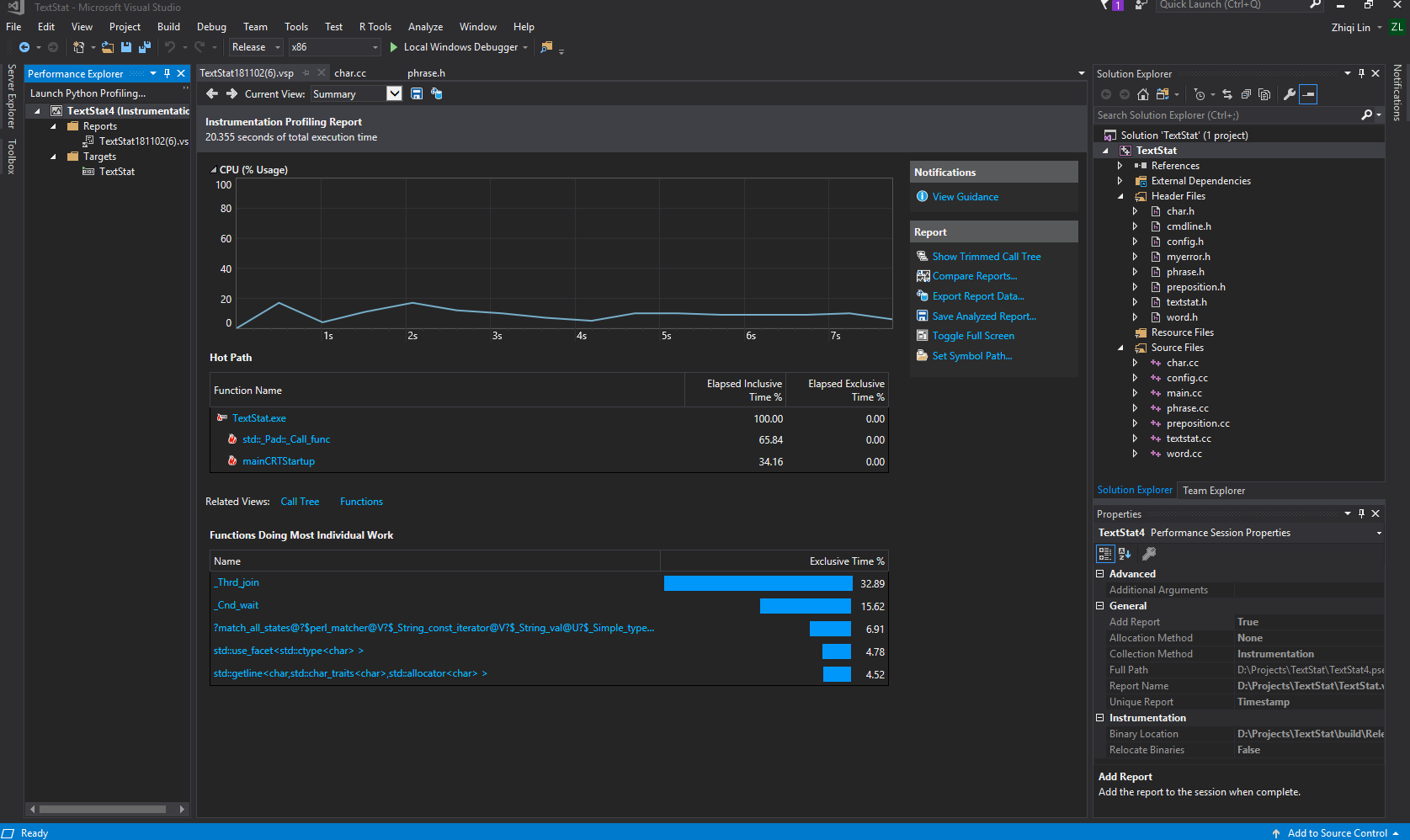
我们主要统计的是热点函数,针对热点函数做优化来下降整体的运行时间。
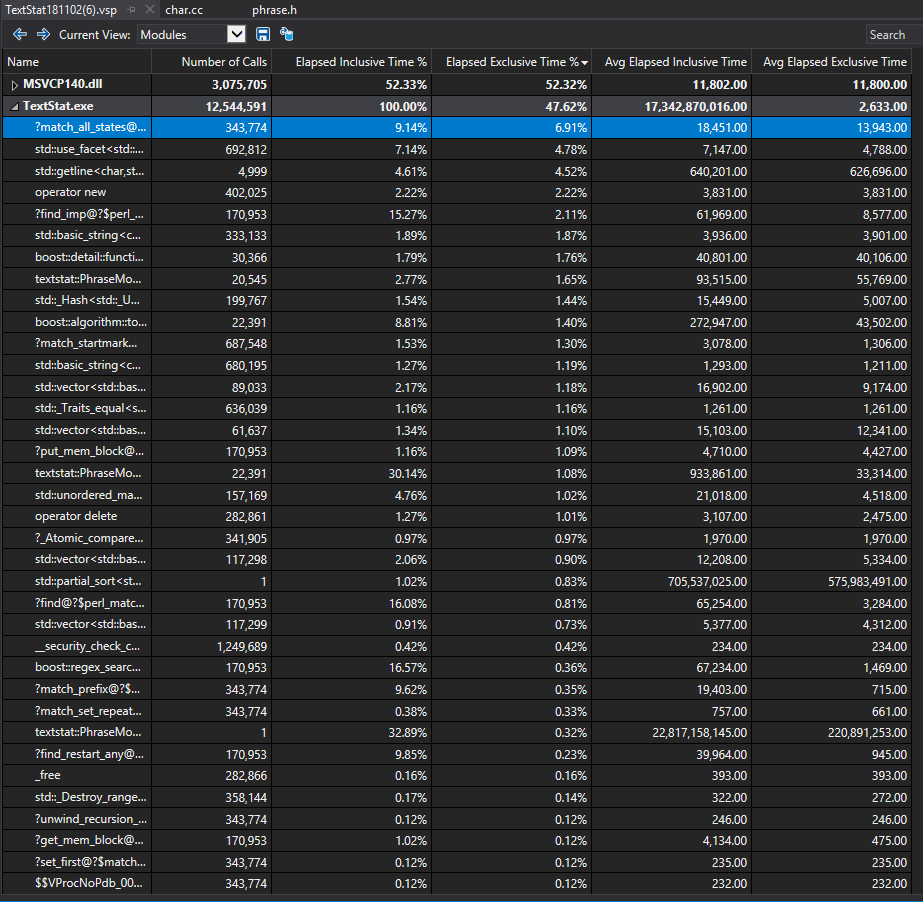
下图是我们获得各个函数的执行情况表(在统计词组的情况下),从墙上函数内运行时间(Elapsed Exclusive Time) 来看,第一个热点函数是正则匹配中使用到的,说明正则匹配在整个过程中拥有着较大的开销。同时第三大开销是std::getline(), 这是存在于文件读取的,由于文件大小已经固定,读取的时间基本也就不会再变。但是可以整体减少整个线程的运行时间,于是也就有了上述的优化。
实际上,更适合我们做性能分析的是性能分析工具的Concurrency 模块,这个模块应该可以看到各个线程的负载情况,从而对线程间能做到更好的负载均衡。但是因为windows权限问题,这个模块的工具无法使用,因此无法做出更进一步的性能分析。
实验结果
我们测试了傲慢与偏见下词组为3的情况,
测试命令为(powershell)
Measure-Command {.TextStat.exe -p 3 -n 10 -v C:Usersv-zhilinDownloads estfileverbs.txt C:Usersv-zhilinDownloads estfilepride-and-prejudice.txt}
测试时间稳定在 0.13秒左右。
结对编程感悟
结对编程可以提高代码编写的速度,同时这次编程采用的框架也是一般大型开源工程采用的源码框架,所以对项目编程有很大的收获。