文章转自:https://blog.csdn.net/xhh198781/article/details/7268298
在Hadoop中为了方便集群中各个组件之间的通信,它采用了RPC,当然为了提高组件之间的通信效率以及考虑到组件自身的负载等情况,Hadoop在其内部实现了一个基于IPC模型的RPC。关于这个RPC组件的整体情况我已绍经在前面的博文中介绍过了。而在本文,我将结合源代码详细地介绍它在客户端的实现。
先来看看与RPC客户端相关联的一些类吧!
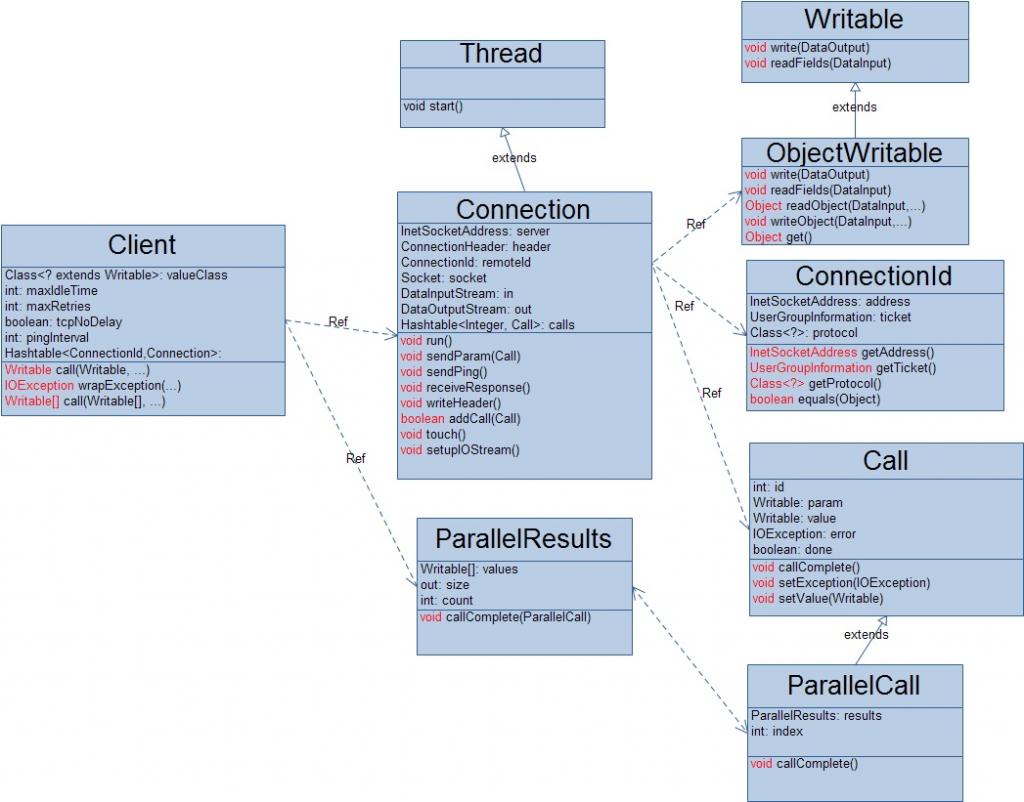
1.Client类
-
private Hashtable<ConnectionId, Connection> connections = new Hashtable<ConnectionId, Connection>(); //与远程服务器连接的缓存池
-
-
private Class<? extends Writable> valueClass; //远程方法调用发回后返回值解析器
-
-
final private int maxIdleTime; //连接的最大空闲时间
-
final private int maxRetries; //Socket连接时,最大Retry次数
-
private boolean tcpNoDelay; //设置TCP连接是否延迟
-
private int pingInterval; //ping服务端的间隔
在Client中,因为与服务器的每一次连接不仅会产生网络延迟,而且也会占用大量的系统资源,所以在Client内部设计了一个连接池,用来缓存与不同服务端的连接,通过对象ConnectionId来表示每一连接。当然,每一个连接有一个最大空闲期maxIdleTime,如果一个连接在时间maxIdleTime内没有被使用的话,该连接将自动关闭与Server的连接,以此来释放该连接在服务器端和客户端的系统资源。这个最大空闲期maxIdleTime的值可以通过客户端的配置文件来设置,对应的配置项为:ipc.client.connection.maxidletime。同时为了维护该连接的有效性,该连接设置了基于TCP的Socket的网络超时时间,当该连接发生SocketTimeoutException时,会自动的向服务器端发送ping包,来测试当前客户端与服务器端的连接是否正常,同时也来告诉服务器自己现在还是在正常工作的,若果处理来了就可以把结果发送回来,这个超时时间的值为pingInterval,该值的默认大小是60000ms,不过也可以通过 客户端的配置文件来配置,对应的配置项为:ipc.ping.interva l。另外,当该连接向服务器发起连接请求失败的时候,可以不断的重新尝试,尝试的次数由maxRetries决定,当尝试的次数超过该值时,就将该连接视为彻底的失败,客户端的这一次RPC也就失败了。maxRetries默认的值为10,但也可以客户端的配置文件来配置,对应的配置选项为:ipc.client.connect.max.retries。底层的基于TCP的Socket网络连接还可以通过配置文件来设置是否延迟,对应的配置项为:ipc.client.tcpnodelay。其实,对于上面Client内部的四个参数,我们可以根据具体的应用场景来设置适当的值,已达到提高Hadoop集群性能的目的。当一个RPC成果返回之后,Client还需要把此次调用的返回结果解析成用户真正需要的数据类型(毕竟,网络返回的都是0/1序列),所以Cleint在其内部还需要一个解析器,该解析器的类型为valuesClass,在hadoop的0.20.2.0版本中,这个解析器的类型为ObjectWritable。但是令人不解的是,每一次RPC调用返回之后,都会利用JDK的反射机制来创建该类的一个实例,然后利用这个解析器实例来解析返回结果,这样做的后果想必熟悉JDK反射机制的人都很清除了。
2.Call类
-
int id; // 调用标示ID
-
Writable param; // 调用参数
-
Writable value; // 调用返回的值
-
IOException error; // 异常信息
-
boolean done; // 调用是否完成
客户端的一次RPC所涉及到的所有参数信息(方法名、输入参数、返回值)都被抽象到一个Call对象中,不过在这里所要说的是,Call的param属性包含了此次RPC调用的方法名和所有的输入参数,它的具体类型是org.apache.hadoop.ipc.RPC.Invocation,它主要属性有:
-
private String methodName; //方法名
-
private Class[] parameterClasses; //参数类型集合
-
private Object[] parameters; //参数值
3.ConnectionId类
-
InetSocketAddress address;//连接实例的Socket地址
-
GroupInformation ticket;//客户端用户信息
-
Class<?> protocol;//连接的协议
前面刚说过,在Client内部设计了一个RPC连接池,避免与服务器端频繁的连接于关闭,以此来提高整个系统的工作效率,所以就需要一个标识来表示一个唯一的RPC连接,在这里是通过服务器地址、用户信息、协议类型三个信息来唯一标识一个RPC连接的。
4.Connection类
-
private InetSocketAddress server; // 服务端ip:port
-
private ConnectionHeader header; // 连接头信息,该实体类封装了连接协议与用户信息UserGroupInformation
-
private ConnectionId remoteId; // 连接ID
-
-
private Socket socket = null; // 客户端已连接的Socket
-
private DataInputStream in;
-
private DataOutputStream out;
-
-
private Hashtable<Integer, Call> calls = new Hashtable<Integer, Call>(); //待处理的RPC队列
-
private AtomicLong lastActivity = new AtomicLong();// 最后I/O活跃的时间
-
private AtomicBoolean shouldCloseConnection = new AtomicBoolean(); //连接是否关闭
-
private IOException closeException; //连接关闭原因
在Client内部,把每一个RPC连接Connection设计成了一个后台线程,它的内部放置了一个任务队列来存储待处理的RPC调用,当一个 RPC连接的空闲时间超过设置的最大空闲值时就会自动的关闭,从而及时地释放自己在客户端和服务器端所占用的系统资源。为了保证客户端和服务器端底层通信协议的一致性,客户端在与服务器端建立网络连接之后会马上向服务器端发送一个头部信息,以确保C/S两端所用的协议版本号是相同的,当服务器端发现自己与客户端所使用的通信协议版本号不一致时,会立马关闭与客户单的网络连接,而客户端之后会抛出EOFException异常信息。这个头部信息如下:

hrpc:hadoop的RPC实现标识;
version:协议的版本号;
length:剩余信息长度;
protocol:协议类型;
flag:是否有客户端信息;
ugi:客户端信息;
客户端的一次RPC调用的处理过程如下图:

Client为客户设计了两种调用接口,一种是单个RPC调用接口,一种是批量的RPC调用,如下:
-
public Writable call(Writable param, InetSocketAddress addr, Class<?> protocol, UserGroupInformation ticket) throws InterruptedException, IOException
-
public Writable[] call(Writable[] params, InetSocketAddress[] addresses, Class<?> protocol, UserGroupInformation ticket) throws IOException
-
不过这种批量的RPC调用的本质只是对单个RPC调用接口的循环调用,基本上没有做出任何的优化。个人认为可以对批量的RPC调用进行改进来优化调用的执行效率,如:在一次批量的RPC调用中,对于所有相同的Server,可以一次性全部发送到该Server,然后调用的所有执行结果根据该server当前的具体情况一次性全部返回或者分批次返回。总体说来,Hadoop的RPC过程是一个同步的过程。