用Python编写WordCount程序任务
|
程序 |
WordCount |
|
输入 |
一个包含大量单词的文本文件 |
|
输出 |
文件中每个单词及其出现次数(频数),并按照单词字母顺序排序,每个单词和其频数占一行,单词和频数之间有间隔 |
1.编写map函数,reduce函数
首先在/home/hadoop路径下建立wc文件夹,在wc文件夹下创建文件mapper.py和reducer.py
cd /home/hadoop mkdir wc cd /home/hadoop/wc touch mapper.py
touch reducer.py
编写两个函数
mapper.py:
#!/usr/bin/env python
import sys
for line in sys.stdin:
line = line.strip()
words = line.split()
for word in words:
print '%s %s' % (word,1)
reducer.py:
#!/usr/bin/env python
from operator import itemgetter
import sys
current_word = None
current_count = 0
word=None
for line in sys.stdin:
line = line.strip()
word, count = line.split(' ', 1)
try:
count=int(count)
except ValueError:
continue
if current_word == word:
current_count += count
else:
if current_word:
print '%s %s' % (current_word, current_count)
current_count = count
current_word = word
if current_word == word:
print '%s %s' % (current_word, current_count)
2.将其权限作出相应修改
chmod a+x /home/hadoop/wc/mapper.py chmod a+x /home/hadoop/wc/reducer.py
3.本机上测试运行代码
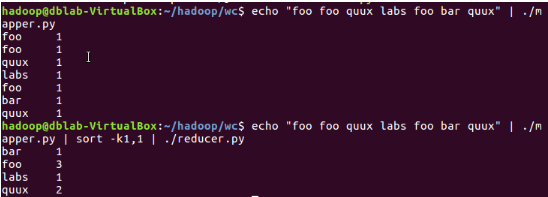
echo "foo foo quux labs foo bar quux" | /home/hadoop/wc/mapper.py echo "foo foo quux labs foo bar quux" | /home/hadoop/wc/mapper.py | sort -k1,1 | /home/hadoop/wc/reducer.py
4.放到HDFS上运行
下载文本文件或爬取网页内容存成的文本文件:
cd /home/hadoop/wc wget http://www.gutenberg.org/files/5000/5000-8.txt wget http://www.gutenberg.org/cache/epub/20417/pg20417.txt
5.下载并上传文件到hdfs上
hdfs dfs -put /home/hadoop/hadoop/gutenberg/*.txt /user/hadoop/input

6.用Hadoop Streaming命令提交任务
寻找你的streaming的jar文件存放地址:
cd /usr/local/hadoop/share/hadoop/tools/lib/hadoop-streaming-2.7.1.jar
打开环境变量配置文件:
gedit ~/.bashrc
在里面写入streaming路径:
export STREAM=$HADOOP_HOME/share/hadoop/tools/lib/hadoop-streaming-*.jar
让环境变量生效:
source ~/.bashrc echo $STREAM
建立一个shell名称为run.sh来运行:
gedit run.sh
hadoop jar $STREAM -file /home/hadoop/wc/mapper.py -mapper /home/hadoop/wc/mapper.py -file /home/hadoop/wc/reducer.py -reducer /home/hadoop/wc/reducer.py -input /user/hadoop/input/*.txt -output /user/hadoop/wcoutput
source run.sh