随着JavaScript越来越流行,越来越多的团队广泛的把JavaScript应用到前端、后台、hybrid 应用、嵌入式等等领域。
这篇文章旨在深入挖掘JavaScript,以及向大家解释JavaScript是如何工作的。我们通过了解它的底层构建以及它是怎么发挥作用的,可以帮助我们写出更好的代码与应用。据 GitHut 统计显示,JavaScript 长期占据GitHub中 Active Repositories 和 Total Pushes 的榜首,并且在其他的类别中也不会落后太多。
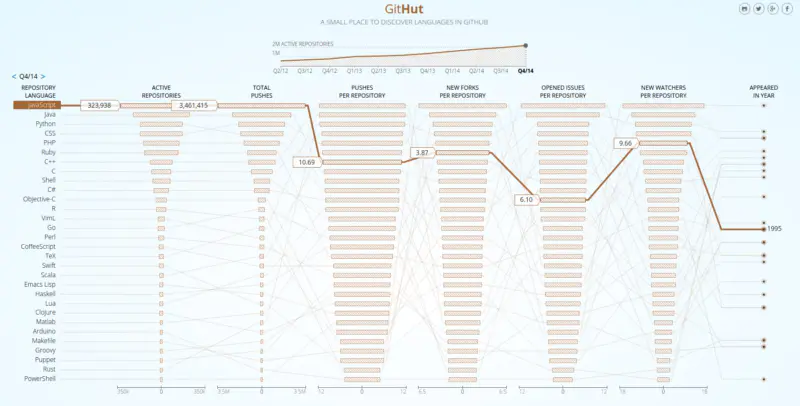
如果一个项目越来越依赖 JavaScript,这就意味着开发人员必须利用这些语言和生态系统提供更深层次的核心内容去构建一个令人振奋的应用。然而,事实证明,有很多的开发者每天都在使用 JavaScript,但是却不知道在底层 JavaScript 是怎么运作的。
二、JavaScript引擎

这个引擎主要是由两部分组成:
(1)内存堆:这是内存分配发生的地方
(2)调用栈:这是你的代码执行的地方
三、运行时
有些浏览器的 API 经常被使用到(比如说:setTimeout),但是,这些 API 都不是引擎提供的。那么,他们是哪里来的呢?事实上。这里的情况有点复杂。
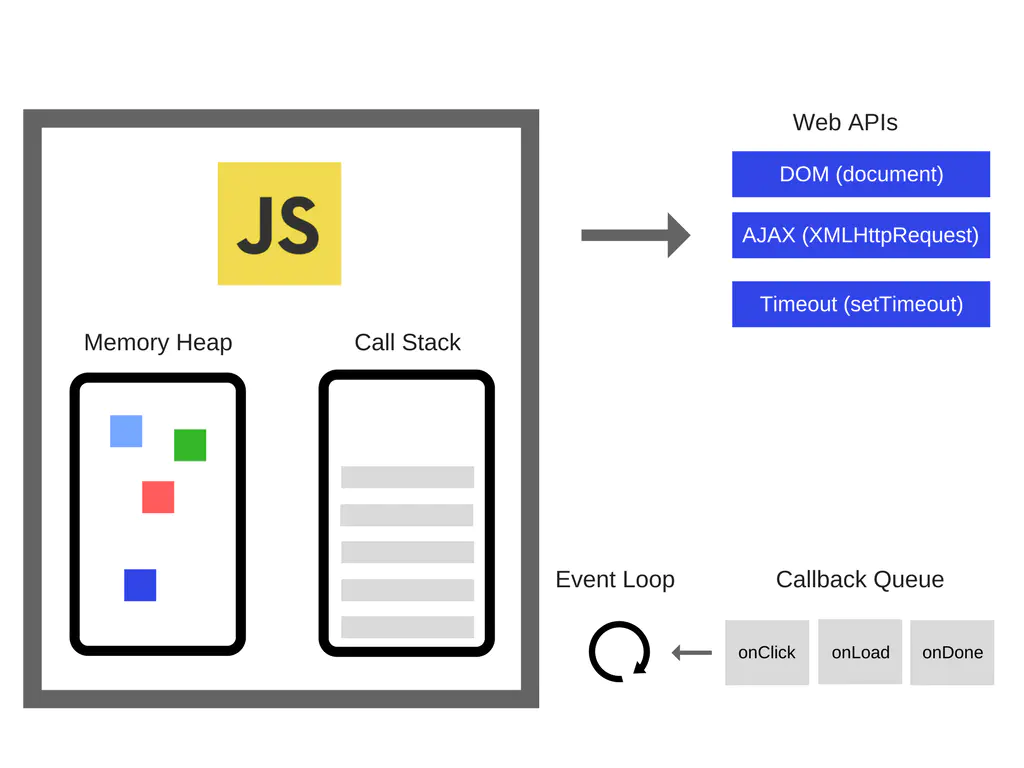
所以说,我们还有很多引擎之外的 API ,我们把这些称为浏览器提供的 Web API ,比如说 DOM ,AJAX,setTimeout 等。
然后我们还拥有如此流行的事件循环和回调队列。
四、调用栈
JavaScript 是一门单线程的语言,这意味着它只有一个调用栈,因此,它同一时间只能做一件事。
调用栈是一种数据结构,他记录了我们在程序中的位置,如果我们运行到一个函数,它将会将其放置到栈顶。当这个函数返回的时候,就会将这个函数从栈顶弹出,这就是调用栈做的事情。
如下例子:
function multiply(x, y) { return x * y; } function printSquare(x) { var s = multiply(x, x); console.log(s); } printSquare(5);
当程序开始执行的时候,调用栈是空的,然后,步骤如下:
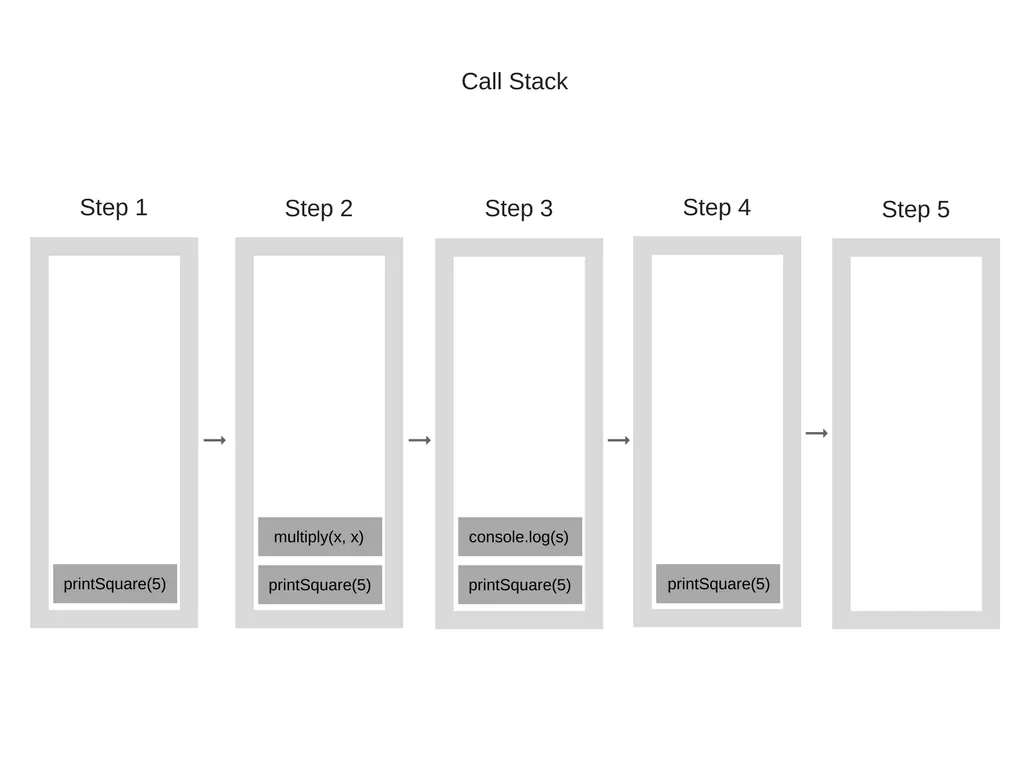
每一个进入调用栈的都称为 “调用帧”。
这能清楚的知道当异常发生的时候堆栈追踪是怎么被构造的,堆栈的状态是如何的。让我们看一下下面的代码。
function foo() { throw new Error('SessionStack will help you resolve crashes :)'); } function bar() { foo(); } function start() { bar(); } start();
如果这发生在 Chrome 里(假设这段代码在一个名为foo.js的文件中),那么将会发生一下的堆栈追踪。

“堆栈溢出”,当你到达调用栈最大的大小的时候,就会发生这种情况,而且这相当容易发生,特别是你写递归的时候却没有全方面的测试它。我们来看看下面的代码:
function foo() { foo(); } foo();
当我们的引擎开始执行这段代码的时候,它从foo 函数开始,然后这是个递归的函数,并且在没有任何的终止条件下开始调用自己,因此每执行一步,就会把这个相同的函数一次又一次的添加到调用堆栈中,然后他看起来是这样的:
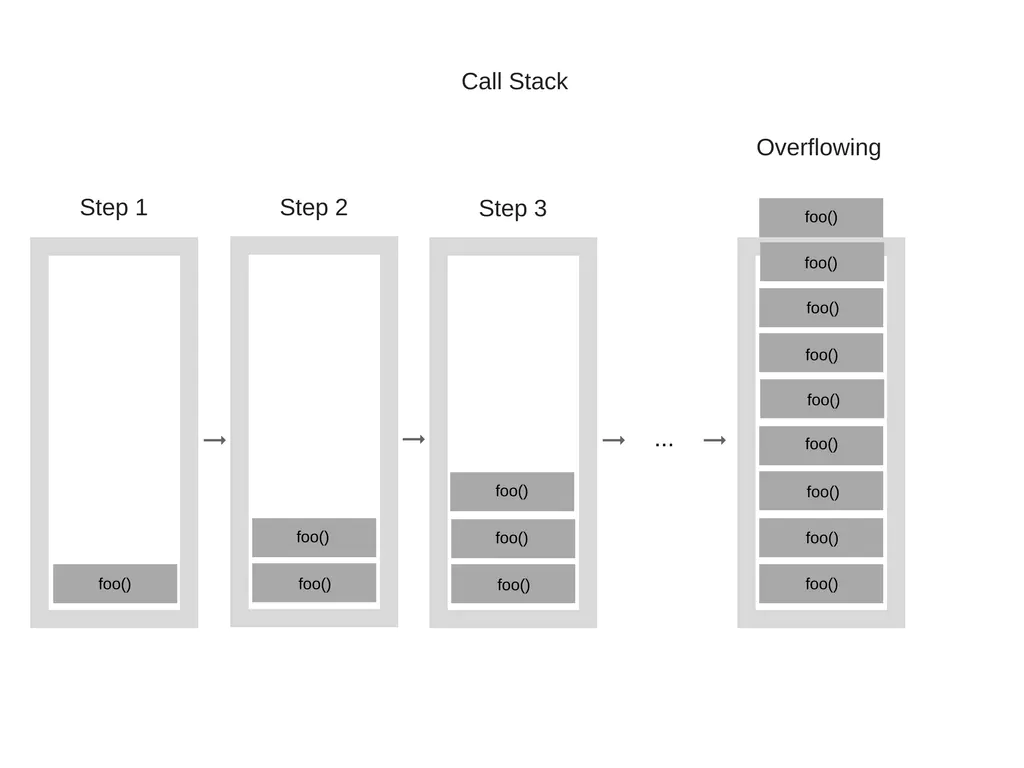
然后,在某一个时刻,调用栈中的函数调用的数量超过了调用栈的实际大小,浏览器就决定干掉它,抛出一个错误,它看起来就像是这样:

在单个线程上运行代码很容易,因为你不必处理在多线程中出现的复杂场景——例如死锁,但是在一个线程上运行也是非常有限制。由于 JavaScript 只有一个堆栈,当某段代码运行变慢的时候会发生什么?
作者:小烜同学
链接:https://juejin.cn/post/6844903510538993671
来源:掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。